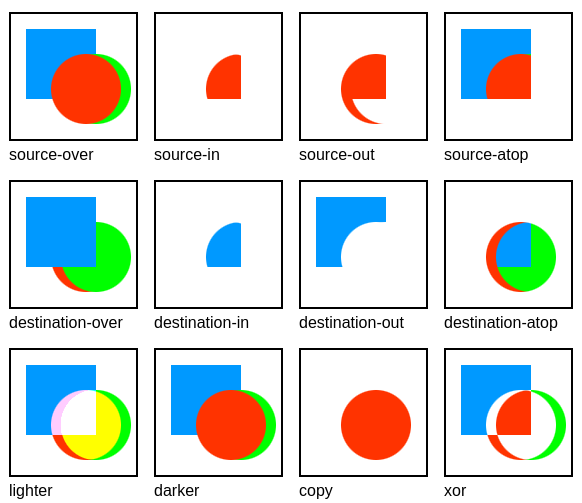
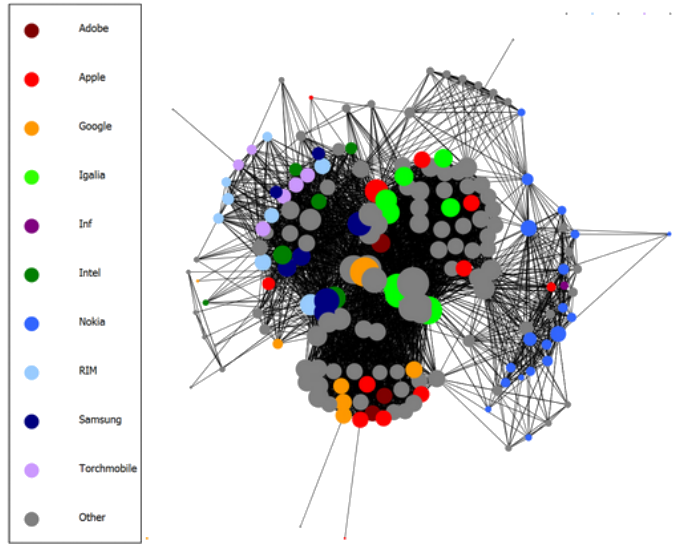
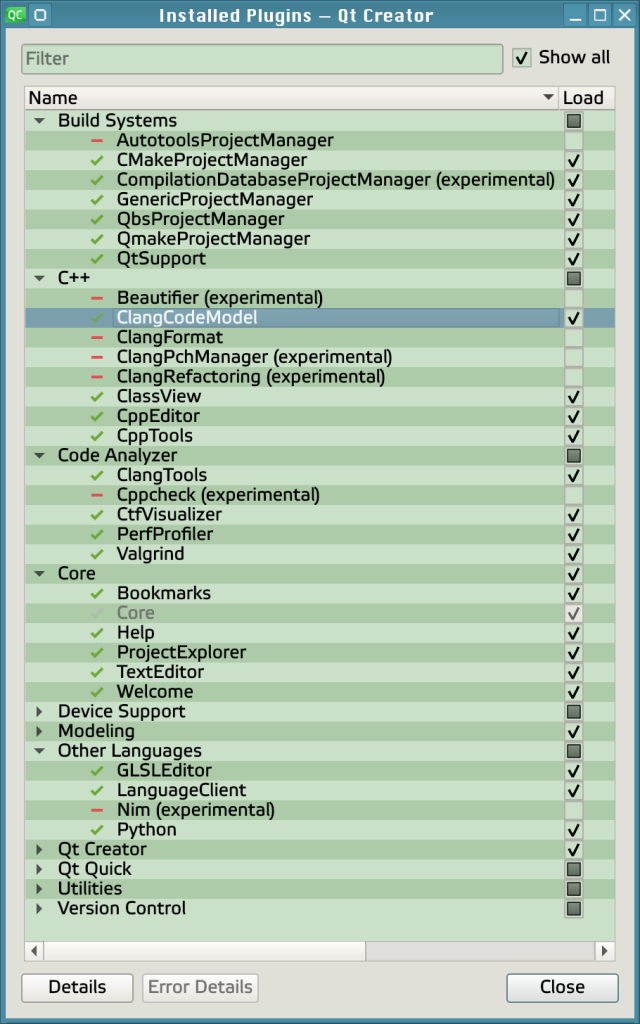
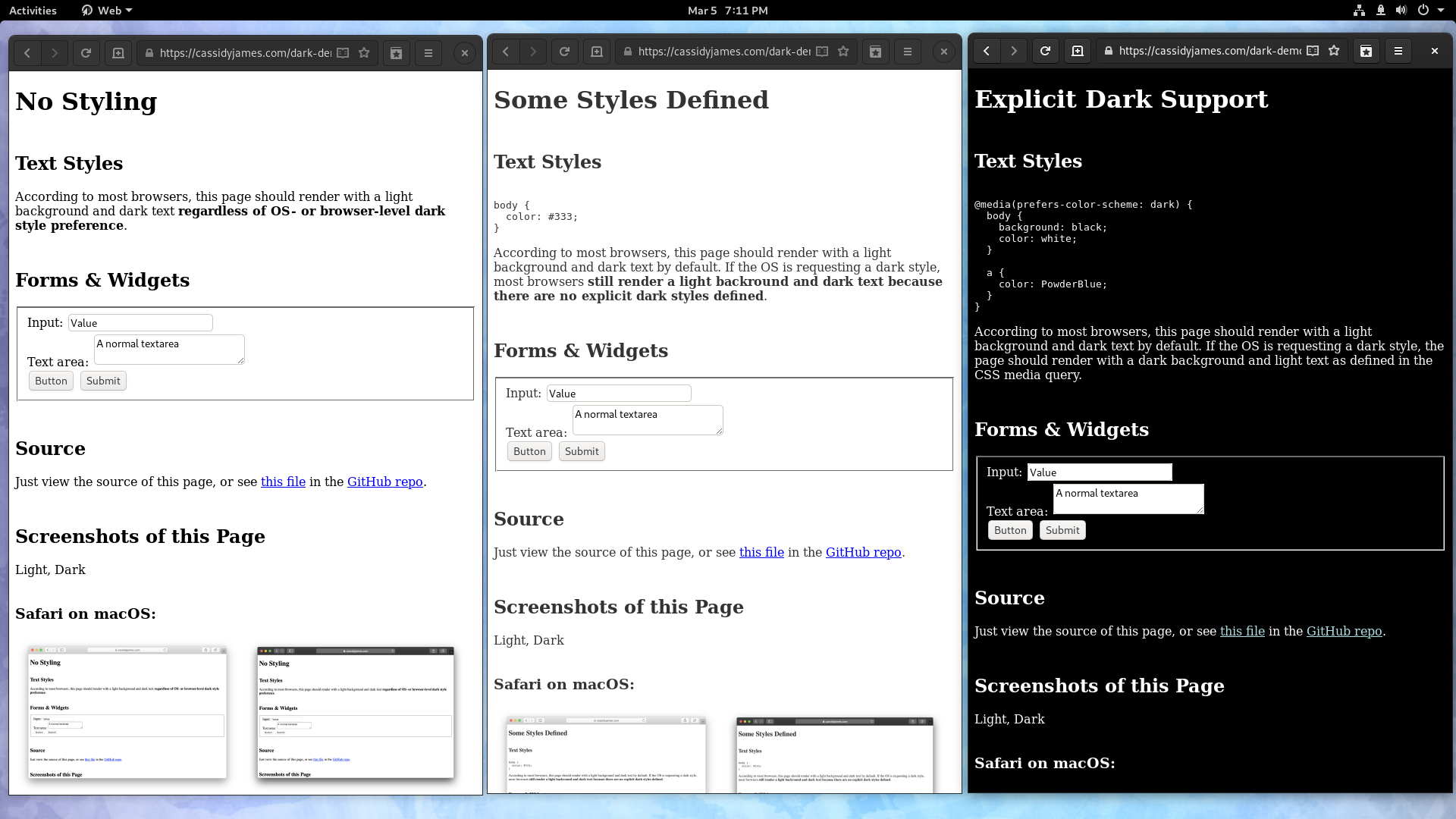
Now that 2025 is over, it’s time to look back and feel proud of the path we’ve walked. Last year has been really exciting in terms of contributions to GStreamer and WebKit for the Igalia Multimedia team.
With more than 459 contributions along the year, we’ve been one of the top contributors to the GStreamer project, in areas like Vulkan Video, GstValidate, VA, GStreamer Editing Services, WebRTC or H.266 support.
Igalia’s contributions to the GStreamer project
In Vulkan Video we’ve worked on the VP9 video decoder, and cooperated with other contributors to push the AV1 decoder as well. There’s now an H.264 base class for video encoding that is designed to support general hardware-accelerated processing.
GStreaming Editing Services, the framework to build video editing applications, has gained time remapping support, which now allows to include fast/slow motion effects in the videos. Video transformations (scaling, cropping, rounded corners, etc) are now hardware-accelerated thanks to the addition of new Skia-based GStreamer elements and integration with OpenGL. Buffer pool tuning and pipeline improvements have helped to optimize memory usage and performance, enabling the edition of 4K video at 60 frames per second. Much of this work to improve and ensure quality in GStreamer Editing Services has also brought improvements in the GstValidate testing framework, which will be useful for other parts of GStreamer.
Regarding H.266 (VVC), full playback support (with decoders such as vvdec and avdec_h266, demuxers and muxers for Matroska, MP4 and TS, and parsers for the vvc1 and vvi1 formats) is now available in GStreamer 1.26 thanks to Igalia’s work. This allows user applications such as the WebKitGTK web browser to leverage the hardware accelerated decoding provided by VAAPI to play H.266 video using GStreamer.
Igalia has also been one of the top contributors to GStreamer Rust, with 43 contributions. Most of the commits there have been related to Vulkan Video.
Igalia’s contributions to the GStreamer Rust project
In addition to GStreamer, the team also has a strong presence in WebKit, where we leverage our GStreamer knowledge to implement many features of the web engine related to multimedia. From the 1739 contributions to the WebKit project done last year by Igalia, the Multimedia team has made 323 of them. Nearly one third of those have been related to generic multimedia playback, and the rest have been on areas such as WebRTC, MediaStream, MSE, WebAudio, a new Quirks system to provide adaptations for specific hardware multimedia platforms at runtime, WebCodecs or MediaRecorder.
Igalia Multimedia Team’s contributions to different areas of the WebKit project
We’re happy about what we’ve achieved along the year and look forward to maintaining this success and bringing even more exciting features and contributions in 2026.
This article is a continuation of the series on WPE performance considerations. While the previous article touched upon fairly low-level aspects of the DOM tree overhead,
this one focuses on more high-level problems related to managing the application’s workload over time. Similarly to before, the considerations and conclusions made in this blog post are strongly related to web applications
in the context of embedded devices, and hence the techniques presented should be used with extra care (and benchmarking) if one would like to apply those on desktop-class devices.
Typical web applications on embedded devices have their workloads distributed over time in various ways. In practice, however, the workload distributions can usually be fitted into one of the following categories:
Idle applications with occasional updates - the applications that present static content and are updated at very low intervals. As an example, one can think of some static dashboard that presents static content and switches
the page every, say, 60 seconds - such as e.g. a static departures/arrivals dashboard on the airport.
Idle applications with frequent updates - the applications that present static content yet are updated frequently (or are presenting some dynamic content, such as animations occasionally). In that case, one can imagine a similar
airport departures/arrivals dashboard, yet with the animated page scrolling happening quite frequently.
Active applications with occasional updates - the applications that present some dynamic content (animations, multimedia, etc.), yet with major updates happening very rarely. An example one can think of in this case is an application
playing video along with presenting some metadata about it, and switching between other videos every few minutes.
Active applications with frequent updates - the applications that present some dynamic content and change the surroundings quite often. In this case, one can think of a stock market dashboard continuously animating the charts
and updating the presented real-time statistics very frequently.
Such workloads can be well demonstrated on charts plotting the browser’s CPU usage over time:
As long as the peak workload (due to updates) is small, no negative effects are perceived by the end user. However, when the peak workload is significant, some negative effects may start getting noticeable.
In case of applications from groups (1) and (2) mentioned above, a significant peak workload may not be a problem at all. As long as there are no continuous visual changes and no interaction is allowed during updates, the end-user
is unable to notice that the browser was not responsive or missed some frames for some period of time. In such cases, the application designer does not need to worry much about the workload.
In other cases, especially the ones involving applications from groups (3) and (4) mentioned above, the significant peak workload may lead to visual stuttering, as any processing making the browser busy for longer than 16.6 milliseconds
will lead to lost frames. In such cases, the workload has to be managed in a way that the peaks are reduced either by optimizing them or distributing them over time.
The first step to addressing the peak workload is usually optimization. Modern web platform gives a full variety of tools to optimize all the stages of web application processing done by the browser. The usual process of optimization is a
2-step cycle starting with measuring the bottlenecks and followed by fixing them. In the process, the usual improvements involve:
using CSS containment,
using shadow DOM,
promoting certain parts of the DOM to layers and manipulating them with transforms,
parallelizing the work with workers/worklets,
using the visibility CSS property to separate painting from layout,
optimizing the application itself (JavaScript code, the structure of the DOM, the architecture of the application),
Unfortunately, in practice, it’s not uncommon that even very well optimized applications still have too much of a peak workload for the constrained embedded devices they’re used on. In such cases, the last resort solution is
pre-rendering. As long as it’s possible from the application business-logic perspective, having at least some web page content pre-rendered is very helpful in situations when workload has to be managed, as pre-rendering
allows the web application designer to choose the precise moment when the content should actually be rendered and how it should be done. With that, it’s possible to establish a proper trade-off between reduction in peak workload and
the amount of extra memory used for storing the pre-rendered contents.
Nowadays, the web platform provides at lest a few widely-adapted APIs that provide means for the application to perform various kinds of pre-rendering. Also, due to the ways the browsers are implemented, some APIs can be purposely misused
to provide pre-rendering techniques not necessarily supported by the specification. However, in the pursuit of good trade-offs, all the possibilities should be taken into account.
Before jumping into particular pre-rendering techniques, it’s necessary to emphasize that the pre-rendering term used in this article refers to the actual rendering being done earlier than it’s visually presented. In that
sense, the resource is rasterized to some intermediate form when desired and then just composited by the browser engine’s compositor later.
The most basic (and limited at the same time) pre-rendering technique is one that involves rendering offline i.e. before the browser even starts. In that case, the first limitation is that the content to be rendered must be known
beforehand. If that’s the case, the rendering can be done in any way, and the result may be captured as e.g. raster or vector image (depending on the desired trade-off). However, the other problem is that such a rendering is usually out of
the given web application scope and thus requires extra effort. Moreover, depending on the situation, the amount of extra memory used, the longer web application startup (due to loading the pre-rendered resources), and the processing
power required to composite a given resource, it may not always be trivial to obtain the desired gains.
The first group of actual pre-rendering techniques happening during web application runtime is related to Canvas and
OffscreenCavas. Those APIs are really useful as they offer great flexibility in terms of usage and are usually very performant.
However, in this case, the natural downside is the lack of support for rendering the DOM inside the canvas. Moreover, canvas has a very limited support for painting text — unlike the DOM, where
CSS has a significant amount of features related to it. Interestingly, there’s an ongoing proposal called HTML-in-Canvas that could resolve those limitations
to some degree. In fact, Blink has a functioning prototype of it already. However, it may take a while before the spec is mature and widely adopted by other browser engines.
When it comes to actual usage of canvas APIs for pre-rendering, the possibilities are numerous, and there are even more of them when combined with processing using workers.
The most popular ones are as follows:
rendering to an invisible canvas and showing it later,
rendering to a canvas detached from the DOM and attaching it later,
rendering to an invisible/detached canvas and producing an image out of it to be shown later,
rendering to an offscreen canvas and producing an image out of it to be shown later.
When combined with workers, some of the above techniques may be used in the worker threads with the rendered artifacts transferred to the main for presentation purposes. In that case, one must be careful with
the transfer itself, as some objects may get serialized, which is very costly. To avoid that, it’s recommended to use transferable objects
and always perform a proper benchmarking to make sure the transfer is not involving serialization in the particular case.
While the use of canvas APIs is usually very straightforward, one must be aware of two extra caveats.
First of all, in the case of many techniques mentioned above, there is no guarantee that the browser will perform actual rasterization at the given point in time. To ensure the rasterization is triggered, it’s usually
necessary to enforce it using e.g. a dummy readback (getImageData()).
Finally, one should be aware that the usage of canvas comes with some overhead. Therefore, creating many canvases or creating them often, may lead to performance problems that could outweigh the gains from the
pre-rendering itself.
The second group of pre-rendering techniques happening during web application runtime is limited to the DOM rendering and comes out of a combination of purposeful spec misuse and tricking the browser engine into making it rasterizing
on demand. As one can imagine, this group of techniques is very much browser-engine-specific. Therefore, it should always be backed by proper benchmarking of all the use cases on the target browsers and target hardware.
In principle, all the techniques of this kind consist of 3 parts:
Enforcing the content to be pre-rendered being placed on a separate layer backed by an actual buffer internally in the browser,
Tricking the browser’s compositor into thinking that the layer needs to be rasterized right away,
Ensuring the layer won’t be composited eventually.
When all the elements are combined together, the browser engine will allocate an internal buffer (e.g. texture) to back the given DOM fragment, it will process that fragment (style recalc, layout), and rasterize it right away. It will do so
as it will not have enough information to allow delaying the rasterization of the layer (as e.g. in case of display: none). Then, when the compositing time comes, the layer will turn out to be invisible in practice
due to e.g. being occluded, clipped, etc. This way, the rasterization will happen right away, but the results will remain invisible until a later time when the layer is made visible.
In practice, the following approaches can be used to trigger the above behavior:
for (1), the CSS properties such as will-change: transform, z-index, position: fixed, overflow: hidden etc. can be used depending on the browser engine,
for (2) and (3), the CSS properties such as opacity: 0, overflow: hidden, contain: strict etc. can be utilized, again, depending on the browser engine.
The scrolling trick
While the above CSS properties allow for various combinations, in case of WPE WebKit in the context of embedded devices (tested on NXP i.MX8M Plus), the combination that has proven to yield the best performance benefits turns
out to be a simple approach involving overflow: hidden and scrolling. The example of such an approach is explained below.
With the number of idle frames (if) set to 59, the idea is that the application does nothing significant for the 59 frames, and then every 60th frame it updates all the numbers in the table.
As one can imagine, on constrained embedded devices, such an approach leads to a very heavy workload during every 60th frame and hence to lost frames and unstable application’s FPS.
As long as the numbers are available earlier than every 60th frame, the above application is a perfect example where pre-rendering could be used to reduce the peak workload.
To simulate that, the 3 variants of the approach involving the scrolling trick were prepared for comparison with the above:
In the above demos, the idea is that each cell with a number becomes a scrollable container with 2 numbers actually — one above the other. In that case, because overflow: hidden is set, only one of the numbers is visible while the
other is hidden — depending on the current scrolling:
With such a setup, it’s possible to update the invisible numbers during idle frames without the user noticing. Due to how WPE WebKit accelerates the scrolling, changing the invisible
numbers, in practice, triggers the layout and rendering right away. Moreover, the actual rasterization to the buffer backing the scrollable container happens immediately (depending on the tiling settings), and hence the high cost of layout
and text rasterization can be distributed. When the time comes, and all the numbers need to be updated, the scrollable containers can be just scrolled, which in that case turns out to be ~2 times faster than updating all the numbers in place.
While the first sysprof trace shows very little processing during 11 idle frames and a big chunk of processing (21 ms) every 12th frame, the second sysprof trace shows how the distribution of load looks. In
that case, the amount of work during 11 idle frames is much bigger (yet manageable), but at the same time, the formerly big chunk of processing every 12th frame is reduced almost 2 times (to 11 ms). Therefore, the overall
frame rate in the application is much better.
Results
Despite the above improvement speaking for itself, it’s worth summarizing the improvement with the benchmarking results of the above demos obtained from the NXP i.MX8M Plus and presenting the application’s average
frames per second (FPS):
Clearly, the positive impact of pre-rendering can be substantial depending on the conditions. In practice, when the rendered DOM fragment is more complex, the trick such as above can yield even better results.
However, due to how tiling works, the effect can be minimized if the content to be pre-rendered spans multiple tiles. In that case, the browser may defer rasterization until the tiles are actually needed. Therefore,
the above needs to be used with care and always with proper benchmarking.
As demonstrated in the above sections, when it comes to pre-rendering the contents to distribute the web application workload over time, the web platform gives both the official APIs to do it, as well as unofficial
means through purposeful misuse of APIs and exploitation of browser engine implementations. While this article hasn’t covered all the possibilities available, the above should serve as a good initial read with some easy-to-try
solutions that may yield surprisingly good results. However, as some of the ideas mentioned above are very much browser-engine-specific, they should be used with extra care and with the limitations (lack of portability)
in mind.
As the web platform constantly evolves, the pool of pre-rendering techniques and tricks should keep evolving as well. Also, as more and more web applications are used on embedded devices, more pressure should be
put on the specification, which should yield more APIs targeting the low-end devices in the future. With that in mind, it’s recommended for the readers to stay up-to-date with the latest specification and
perhaps even to get involved if some interesting use cases would be worth introducing new APIs.
WebKitGTK 2.50.3 contains a workaround for CVE-2025-13947, an issue that allows websites to exfiltrate files from your filesystem. If you’re using Epiphany or any other web browser based on WebKitGTK, then you should immediately update to 2.50.3.
Websites may attach file URLs to drag sources. When the drag source is dropped onto a drop target, the website can read the file data for its chosen files, without any restrictions. Oops. Suffice to say, this is not how drag and drop is supposed to work. Websites should not be able to choose for themselves which files to read from your filesystem; only the user is supposed to be able to make that choice, by dragging the file from an external application. That is, drag sources created by websites should not receive file access.
I failed to find the correct way to fix this bug in the two afternoons I allowed myself to work on this issue, so instead my overly-broad solution was to disable file access for all drags. With this workaround, the website will only receive the list of file URLs rather than the file contents.
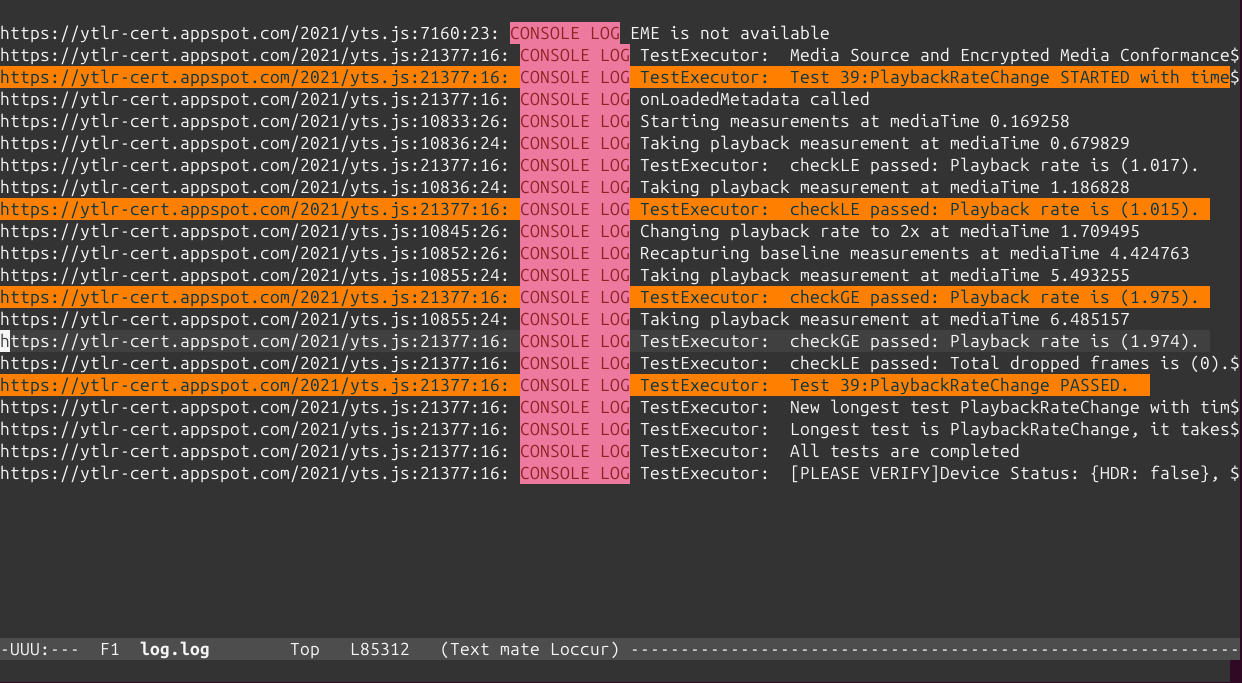
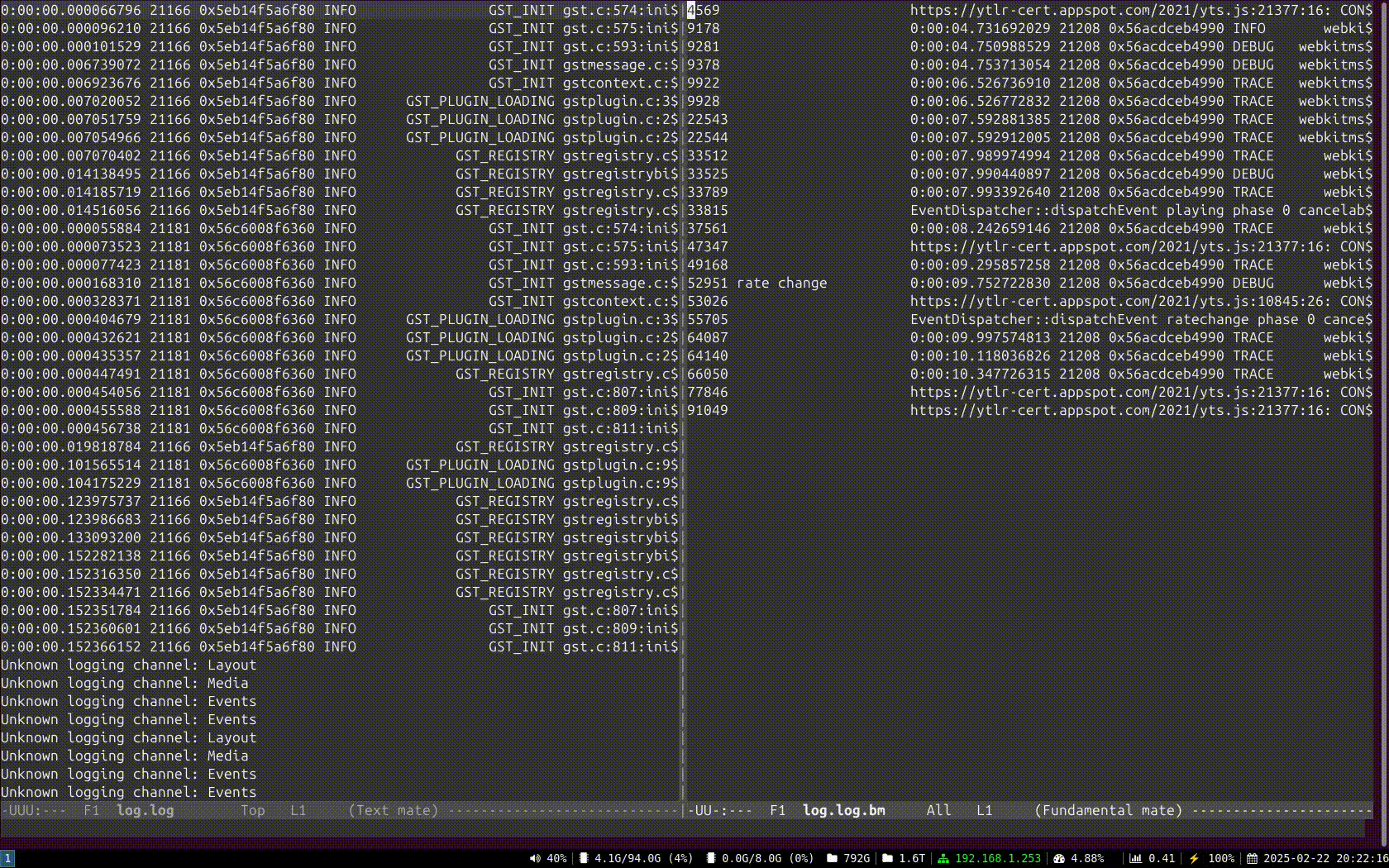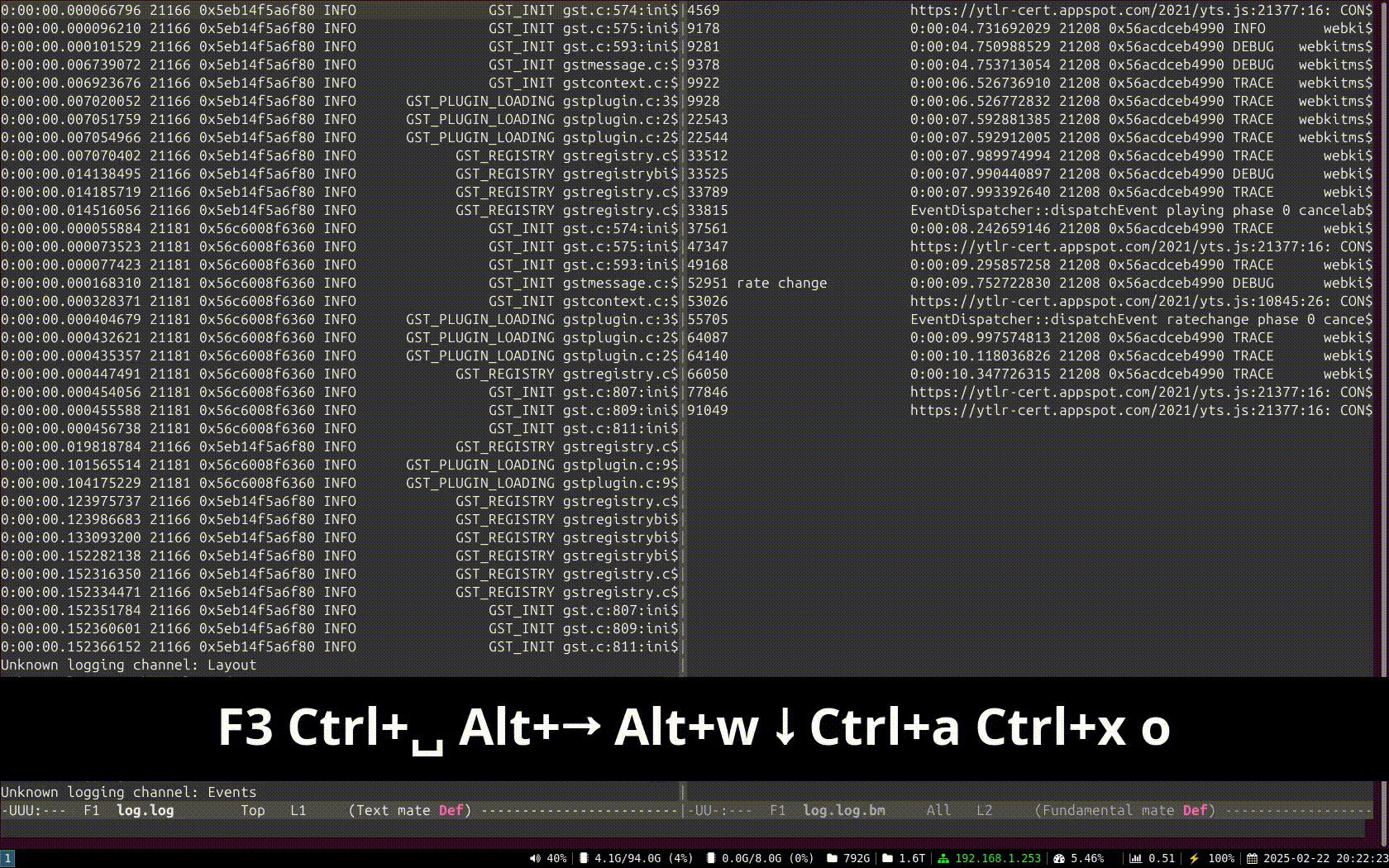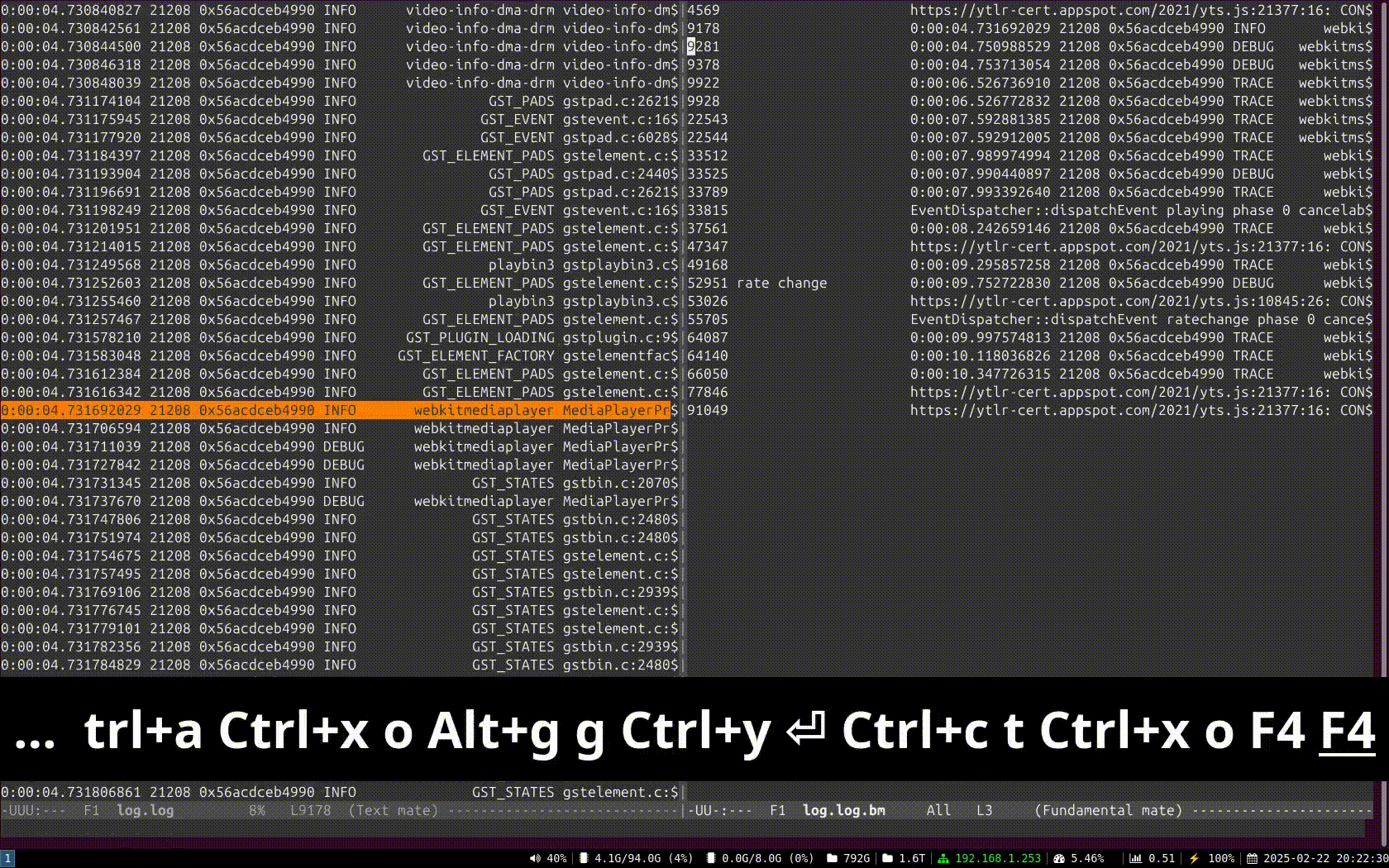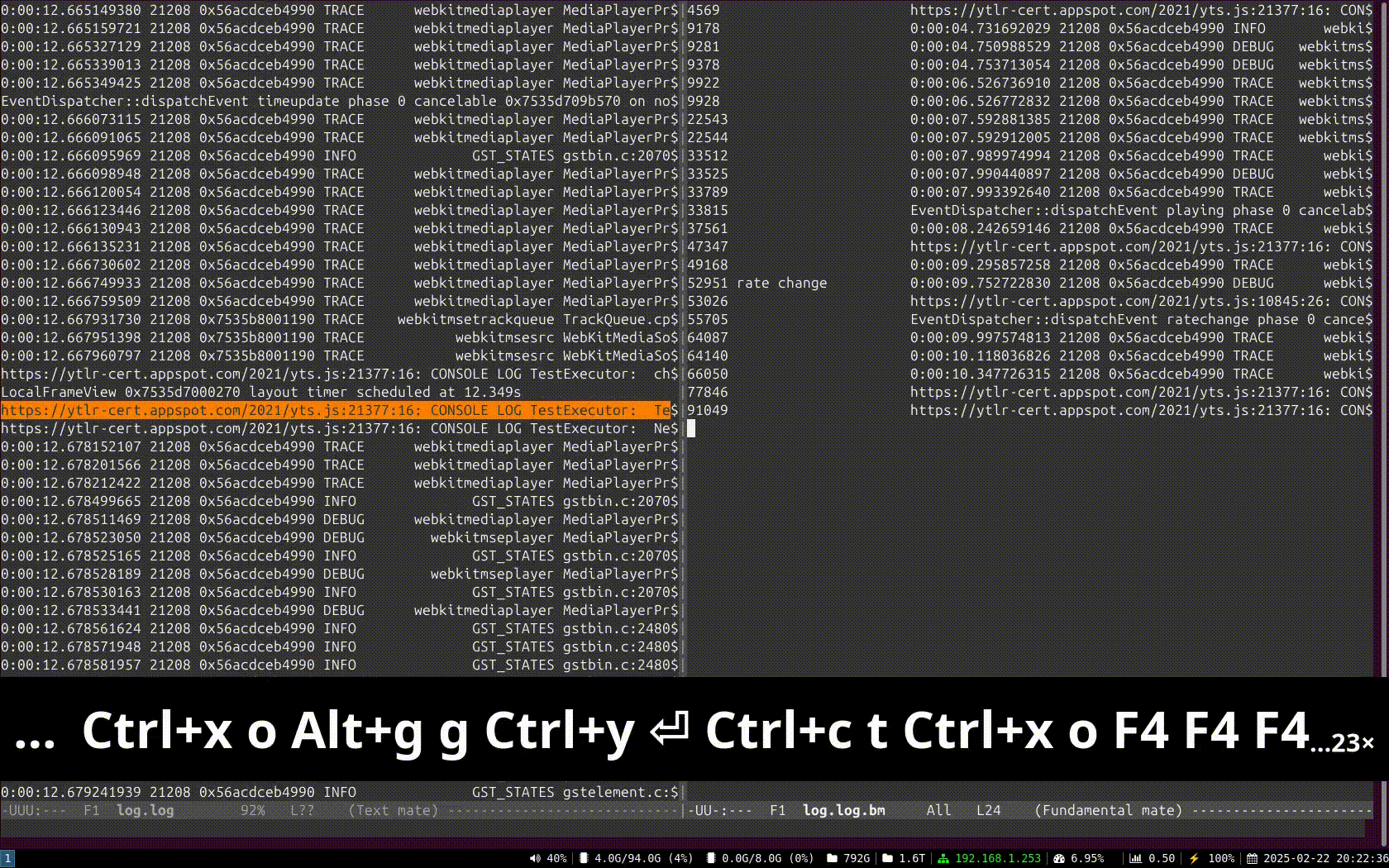
Some years ago I had mentioned some command line tools I used to analyze and find useful information on GStreamer logs. I’ve been using them consistently along all these years, but some weeks ago I thought about unifying them in a single tool that could provide more flexibility in the mid term, and also as an excuse to unrust my Rust knowledge a bit. That’s how I wrote Meow, a tool to make cat speak (that is, to provide meaningful information).
The idea is that you can cat a file through meow and apply the filters, like this:
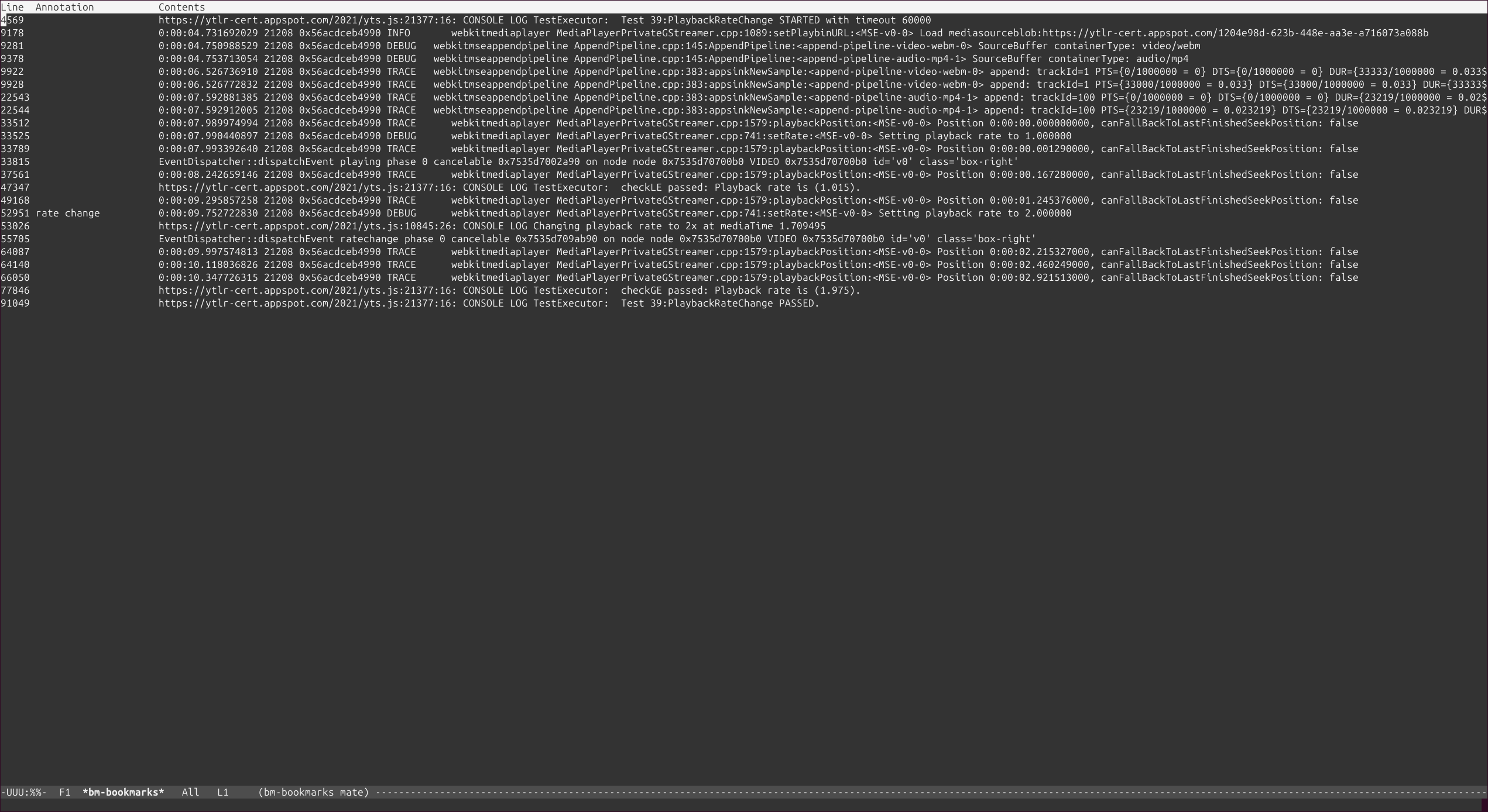
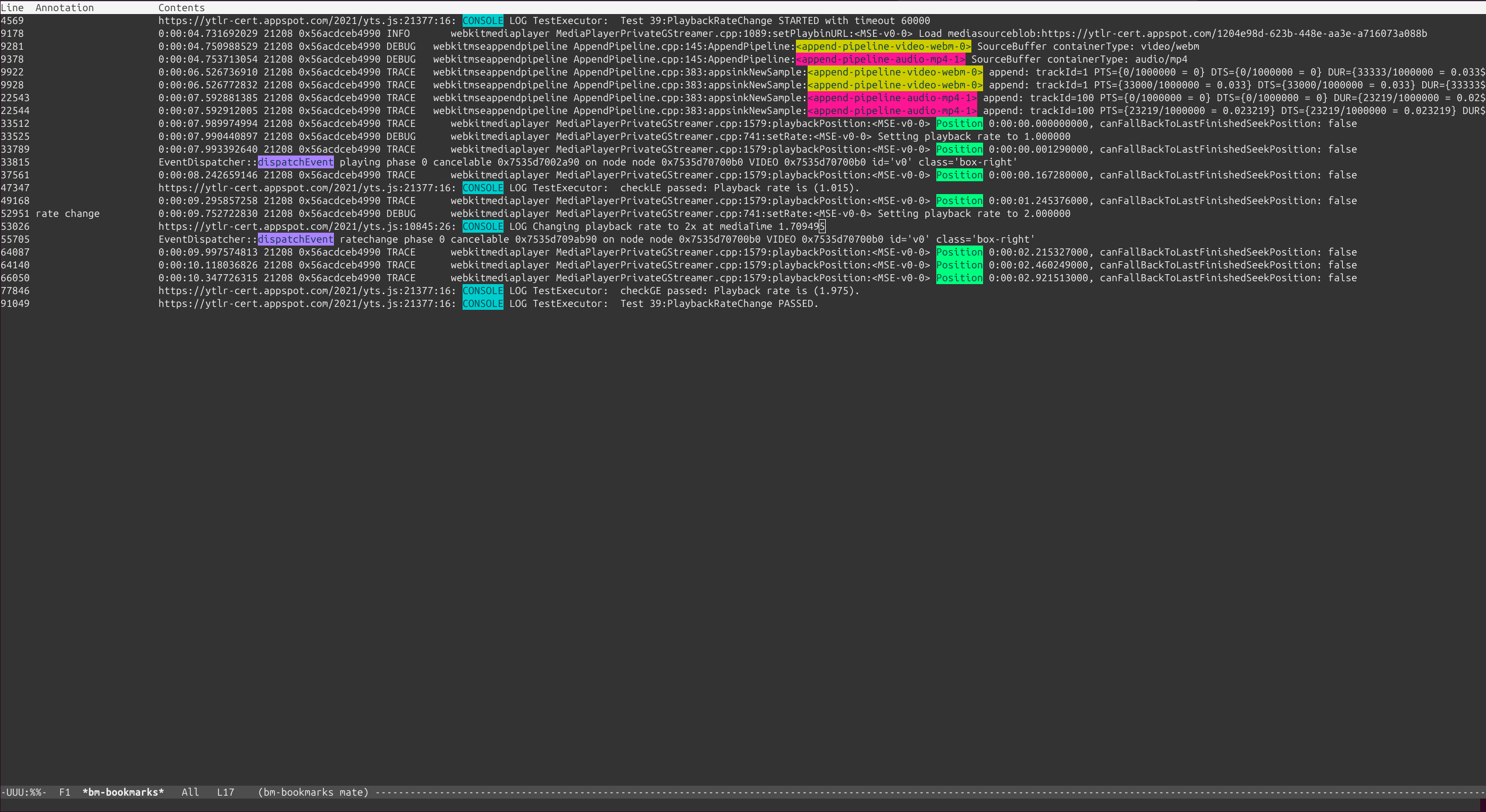
which means “select those lines that contain appsinknewsample (with case insensitive matching), but don’t contain V0 nor video (that is, by exclusion, only that contain audio, probably because we’ve analyzed both and realized that we should focus on audio for our specific problem), highlight the different thread ids, only show those lines with timestamp lower than 21.46 sec, and change strings like Source/WebCore/platform/graphics/gstreamer/mse/AppendPipeline.cpp to become just AppendPipeline.cpp“, to get an output as shown in this terminal screenshot:
Cool, isn’t it? After all, I’m convinced that the answer to any GStreamer bug is always hidden in the logs (or will be, as soon as I add “just a couple of log lines more, bro” ).
Currently, meow supports this set of manipulation commands:
Word filter and highlighting by regular expression (fc:REGEX, or just REGEX): Every expression will highlight its matched words in a different color.
Filtering without highlighting (fn:REGEX): Same as fc:, but without highlighting the matched string. This is useful for those times when you want to match lines that have two expressions (E1, E2) but the highlighting would pollute the line too much. In those case you can use a regex such as E1.*E2 and then highlight the subexpressions manually later with an h: rule.
Negative filter (n:REGEX): Selects only the lines that don’t match the regex filter. No highlighting.
Highlight with no filter (h:REGEX): Doesn’t discard any line, just highlights the specified regex.
Substitution (s:/REGEX/REPLACE): Replaces one pattern for another. Any other delimiter character can be used instead of /, it that’s more convenient to the user (for instance, using # when dealing with expressions to manipulate paths).
Time filter (ft:TIME-TIME): Assuming the lines start with a GStreamer log timestamp, this filter selects only the lines between the target start and end time. Any of the time arguments (or both) can be omitted, but the - delimiter must be present. Specifying multiple time filters will generate matches that fit on any of the time ranges, but overlapping ranges can trigger undefined behaviour.
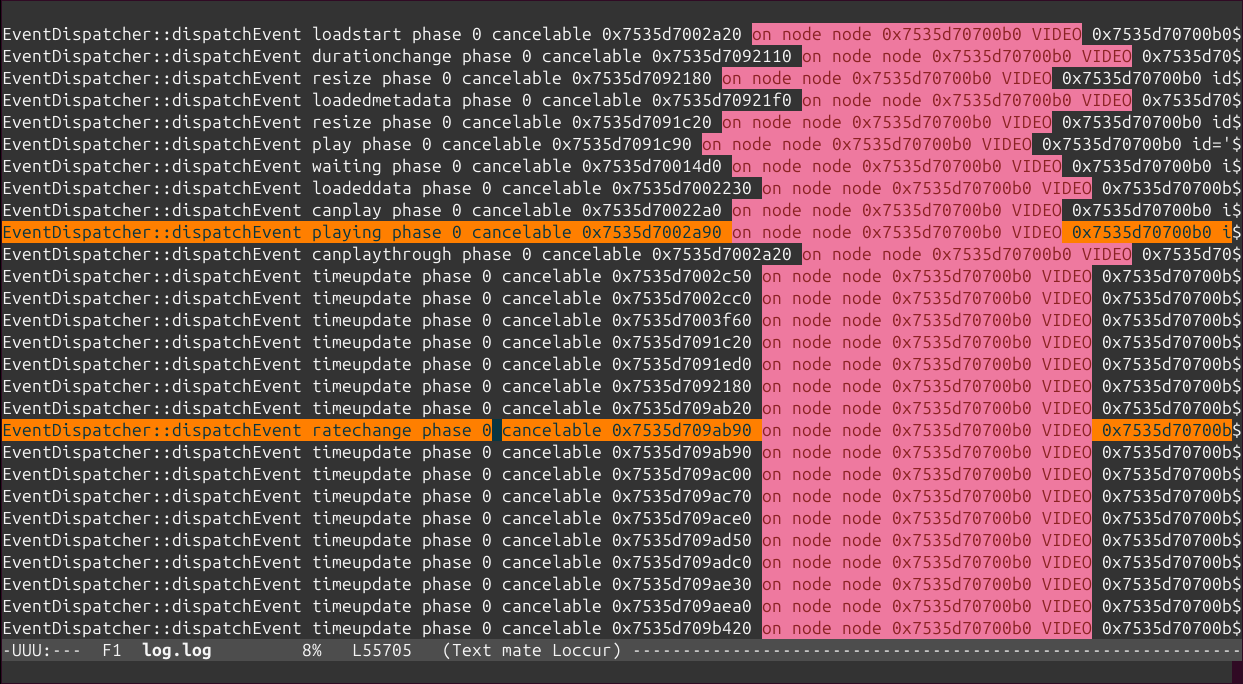
Highlight threads (ht:): Assuming a GStreamer log, where the thread id appears as the third word in the line, highlights each thread in a different color.
The REGEX pattern is a regular expression. All the matches are case insensitive. When used for substitutions, capture groups can be defined as (?CAPTURE_NAMEREGEX).
The REPLACEment string is the text that the REGEX will be replaced by when doing substitutions. Text captured by a named capture group can be referred to by ${CAPTURE_NAME}.
The TIME pattern can be any sequence of numbers, : or . . Typically, it will be a GStreamer timestamp (eg: 0:01:10.881123150), but it can actually be any other numerical sequence. Times are compared lexicographically, so it’s important that all of them have the same string length.
The filtering algorithm has a custom set of priorities for operations, so that they get executed in an intuitive order. For instance, a sequence of filter matching expressions (fc:, fn:) will have the same priority (that is, any of them will let a text line pass if it matches, not forbidding any of the lines already allowed by sibling expressions), while a negative filter will only be applied on the results left by the sequence of filters before it. Substitutions will be applied at their specific position (not before or after), and will therefore modify the line in a way that can alter the matching of subsequent filters. In general, the user doesn’t have to worry about any of this, because the rules are designed to generate the result that you would expect.
Now some practical examples:
Example 1: Select lines with the word “one”, or the word “orange”, or a number, highlighting each pattern in a different color except the number, which will have no color:
$ cat file.txt | meow one fc:orange 'fn:[0-9][0-9]*' 000 one small orange 005 one big orange
Example 2: Assuming a pictures filename listing, select filenames not ending in “jpg” nor in “jpeg”, and rename the filename to “.bak”, preserving the extension at the end:
Example 3: Only print the log lines with times between 0:00:24.787450146 and 0:00:24.790741865 or those at 0:00:30.492576587 or after, and highlight every thread in a different color:
This is only the begining. I have great ideas for this new tool (as time allows), such as support for parenthesis (so the expressions can be grouped), or call stack indentation on logs generated by tracers, in a similar way to what Alicia’s gst-log-indent-tracers tool does. I might also predefine some common expressions to use in regular expressions, such as the ones to match paths (so that the user doesn’t have to think about them and reinvent the wheel every time). Anyway, these are only ideas. Only time and hyperfocus slots will tell…
One of the main constraints that embedded platforms impose on the browsers is a very limited memory. Combined with the fact that embedded web applications tend to run actively for days, weeks, or even longer,
it’s not hard to imagine how important the proper memory management within the browser engine is in such use cases. In fact, WebKit and WPE in particular receive numerous memory-related fixes and improvements every year.
Before making any changes, however, the areas to fix/improve need to be narrowed down first. Like any C++ application, WebKit memory can be profiled using a variety of industry-standard tools. Although such well-known
tools are really useful in the majority of use cases, they have their limits that manifest themselves when applied on production-grade embedded systems in conjunction with long-running web applications.
In such cases, a very useful tool is a debug-only feature of WebKit itself called malloc heap breakdown, which this article describes.
Massif is a heap profiler that comes as part of the Valgrind suite. As its documentation states:
It measures how much heap memory your program uses. This includes both the useful space, and the extra bytes allocated for book-keeping and alignment purposes. It can also measure the size of your program’s stack(s),
although it does not do so by default.
Using Massif with WebKit is very straightforward and boils down to a single command:
The Malloc=1 environment variable set above is necessary to instruct WebKit to enable debug heaps that use the system malloc allocator.
Given some results are generated, the memory usage over time can be visualized using massif-visualizer utility. An example of such a visualization is presented in the image below:
While Massif has been widely adopted and used for many years now, from the very beginning, it suffered from a few significant downsides.
First of all, the way Massif instruments the profiled application introduces significant overhead that may slow down the application up to 2 orders of magnitude. In some cases, such overhead makes it simply unusable.
The other important problem is that Massif is snapshot-based, and hence, the level of detail is not ideal.
Heaptrack is a modern heap profiler developed as part of KDE. The below is its description from the git repository:
Heaptrack traces all memory allocations and annotates these events with stack traces. Dedicated analysis tools then allow you to interpret the heap memory profile to:
find hotspots that need to be optimized to reduce the memory footprint of your application
find memory leaks, i.e. locations that allocate memory which is never deallocated
find allocation hotspots, i.e. code locations that trigger a lot of memory allocation calls
find temporary allocations, which are allocations that are directly followed by their deallocation
At first glance, Heaptrack resembles Massif. However, a closer look at the architecture and features shows that it’s much more than the latter. While it’s fair to say it’s a bit similar, in fact, it is a
significant progression.
Usage of Heaptrack to profile WebKit is also very simple. At the moment of writing, the most suitable way to use it is to attach to a certain running WebKit process using the following command:
heaptrack -p <PID>
while the WebKit needs to be run with system malloc, just like in Massif case:
If profiling of e.g. web content process startup is essential, it’s then recommended also to use WEBKIT2_PAUSE_WEB_PROCESS_ON_LAUNCH=1, which adds 30s delay to the process startup.
When the profiling session is done, the analysis of the recordings is done using:
heaptrack --analyze <RECORDING>
The utility opened with the above, shows various things, such as the memory consumption over time:
flame graphs of memory allocations with respect to certain functions in the code:
etc.
As Heaptrack records every allocation and deallocation, the data it gathers is very precise and full of details, especially when accompanied by stack traces arranged into flame graphs. Also, as Heaptrack
does instrumentation differently than e.g. Massif, it’s usually much faster in the sense that it slows down the profiled application only up to 1 order of magnitude.
Although the memory profilers such as above are really great for everyday use, their limitations on embedded platforms are:
they significantly slow down the profiled application — especially on low-end devices,
they effectively cannot be run for a longer period of time such as days or weeks, due to memory consumption,
they are not always provided in the images — and hence require additional setup,
they may not be buildable out of the box on certain architectures — thus requiring extra patching.
While the above limitations are not always a problem, usually at least one of them is. What’s worse, usually at least one of the limitations turns into a blocking problem. For example, if the target device is very short on memory,
it may be basically impossible to run anything extra beyond the browser. Another example could be a situation where the application slowdown due to the profiler usage, leads to different application behavior, such as a problem
that originally reproduced 100% of the time, does not reproduce anymore etc.
Profiling the memory of WebKit while addressing the above problems points towards a solution that does not involve any extra tools, i.e. instrumenting WebKit itself. Normally, adding such an instrumentation to the C++ application
means a lot of work. Fortunately, in the case of WebKit, all that work is already done and can be easily enabled by using the Malloc heap breakdown.
In a nutshell, Malloc heap breakdown is a debug-only feature that enables memory allocation tracking within WebKit itself. Since it’s built into WebKit, it’s very lightweight and very easy to build, as it’s just about setting
the ENABLE_MALLOC_HEAP_BREAKDOWN build option. Internally, when the feature is enabled, WebKit switches to using debug heaps that use system malloc along with the malloc zone API
to mark objects of certain classes as belonging to different heap zones and thus allowing one to track the allocation sizes of such zones.
As the malloc zone API is specific to BSD-like OSes, the actual implementations (and usages) in WebKit have to be considered separately for Apple and non-Apple ports.
Malloc heap breakdown was originally designed only with Apple ports in mind, with the reason being twofold:
The malloc zone API is provided virtually by all platforms that Apple ports integrate with.
MacOS platforms provide a great utility called footprint that allows one to inspect per-zone memory statistics for a given process.
Given the above, usage of malloc heap breakdown with Apple ports is very smooth and as simple as building WebKit with the ENABLE_MALLOC_HEAP_BREAKDOWN build option and running on macOS while using the footprint utility:
Footprint is a macOS specific tool that allows the developer to check memory usage across regions.
Since all of the non-Apple WebKit ports are mostly being built and run on non-BSD-like systems, it’s safe to assume the malloc zone API is not offered to such ports by the system itself.
Because of the above, for many years, malloc heap breakdown was only available for Apple ports.
The idea behind the integration for non-Apple ports is to provide a simple WebKit-internal library that provides a fake <malloc/malloc.h> header along with simple implementation that provides malloc_zone_*() function implementations
as proxy calls to malloc(), calloc(), realloc() etc. along with a tracking mechanism that keeps references to memory chunks. Such an approach gathers all the information needed to be reported later on.
At the moment of writing, the above allows 2 methods of reporting the memory usage statistics periodically:
By default, when WebKit is built with ENABLE_MALLOC_HEAP_BREAKDOWN, the heap breakdown is printed to the standard output every few seconds for each process. That can be tweaked by setting WEBKIT_MALLOC_HEAP_BREAKDOWN_LOG_INTERVAL=<SECONDS>
environment variable.
The results have a structure similar to the one below:
Given the allocation statistics per-zone, it’s easy to narrow down the unusual usage patterns manually. The example of a successful investigation is presented in the image below:
Moreover, the data presented can be processed either manually or using scripts to create memory usage charts that span as long as the application lifetime so e.g. hours (20+ like below), days, or even longer:
Periodic reporting to sysprof
The other reporting mechanism currently supported is reporting periodically to sysprof as counters. In short, sysprof is a modern system-wide profiling tool
that already integrates with WebKit very well when it comes to non-Apple ports.
The condition for malloc heap breakdown reporting to sysprof is that the WebKit browser needs to be profiled e.g. using:
sysprof-cli -f -- <BROWSER_COMMAND>
and the sysprof has to be in the latest version possible.
With the above, the memory usage statistics can then be inspected using the sysprof utility and look like in the image below:
In the case of sysprof, memory statistics in that case are just a minor addition to other powerful features that were well described in this blog post from Georges.
While malloc heap breakdown is very useful in some use cases — especially on embedded systems — there are a few problems with it.
First of all, compilation with -DENABLE_MALLOC_HEAP_BREAKDOWN=ON is not guarded by any continuous integration bots; therefore, the compilation issues are expected on the latest WebKit main. Fortunately, fixing the problems
is usually straightforward. For a reference on what may be causing compilation problems usually, one should refer to 299555@main, which contains a full variety of fixes.
The second problem is that malloc heap breakdown uses WebKit’s debug heaps, and hence the memory usage patterns may be different just because system malloc is used.
The third, and final problem, is that malloc heap breakdown integration for non-Apple ports introduces some overhead as the allocations need to lock/unlock the mutex, and as statistics are stored in the memory as well.
Although malloc heap breakdown can be considered fairly constrained, in the case of non-Apple ports, it gives some additional possibilities that are worth mentioning.
Because on non-Apple ports, the custom library is used to track allocations (as mentioned at the beginning of the Malloc heap breakdown on non-Apple ports section), it’s very easy
to add more sophisticated tracking/debugging/reporting capabilities. The only file that requires changes in such a case is:
Source/WTF/wtf/malloc_heap_breakdown/main.cpp.
Some examples of custom modifications include:
adding different reporting mechanisms — e.g. writing to a file, or to some other tool,
reporting memory usage with more details — e.g. reporting the per-memory-chunk statistics,
dumping raw memory bytes — e.g. when some allocations are suspicious.
altering memory in-place — e.g. to simulate memory corruption.
While the presented malloc heap breakdown mechanism is a rather poor approximation of what industry standard tools offer, the main benefit of it is that it’s built into WebKit, and that in some rare use-cases (especially on
embedded platforms), it’s the only way to perform any reasonable profiling.
In general, as a rule of thumb, it’s not recommended to use malloc heap breakdown unless all other methods have failed. In that sense, it should be considered a last resort approach. With that in mind, malloc heap breakdown
can be seen as a nice mechanism complementing other tools in the toolbox.
Designing performant web applications is not trivial in general. Nowadays, as many companies decide to use web platform on embedded devices, the problem of designing performant web applications becomes even more complicated.
Typical embedded devices are orders of magnitude slower than desktop-class ones. Moreover, the proportion between CPU and GPU power is commonly different as well. This usually results in unexpected performance bottlenecks
when the web applications designed with desktop-class devices in mind are being executed on embedded environments.
In order to help web developers approach the difficulties that the usage of web platform on embedded devices may bring, this blog post initiates a series of articles covering various performance-related aspects
in the context of WPE WebKit usage on embedded devices. The coverage in general will include:
introducing the demo web applications dedicated to showcasing use cases of a given aspect,
benchmarking and profiling the WPE WebKit performance using the above demos,
discussing the causes for the performance measured,
inferring some general pieces of advice and rules of thumb based on the results.
This article, in particular, discusses the overhead of nodes in the DOM tree when it comes to layouting. It does that primarily by investigating the impact of idle nodes that introduce the least overhead and hence
may serve as a lower bound for any general considerations. With the data presented in this article, it should be clear how the DOM tree size/depth scales in the case of embedded devices.
Historically, the DOM trees emerging from the usual web page designs were rather limited in size and fairly shallow. This was the case as there were
no reasons for them to be excessively large unless the web page itself had a very complex UI. Nowadays, not only are the DOM trees much bigger and deeper, but they also tend to contain idle nodes that artificially increase
the size/depth of the tree. The idle nodes are the nodes in the DOM that are active yet do not contribute to any visual effects. Such nodes are usually a side effect of using various frameworks and approaches that
conceptualize components or services as nodes, which then participate in various kinds of processing utilizing JavaScript. Other than idle nodes, the DOM trees are usually bigger and deeper nowadays, as there
are simply more possibilities that emerged with the introduction of modern APIs such as Shadow DOM,
Anchor positioning, Popover, and the like.
In the context of web platform usage on embedded devices, the natural consequence of the above is that web designers require more knowledge on how the particular browser performance scales with the DOM tree size and shape.
Before considering embedded devices, however, it’s worth to take a brief look at how various web engines scale on desktop with the DOM tree growing in depth.
In short, the above demo measures the average duration of a benchmark function run, where the run does the following:
changes the text of a single DOM element to a random number,
forces a full tree layout.
Moreover, the demo allows one to set 0 or more parent idle nodes for the node holding text, so that the layout must consider those idle nodes as well.
The parameters used in the URL above mean the following:
vr=0 — the results are reported to the console. Alternatively (vr=1), at the end of benchmarking (~23 seconds), the result appears on the web page itself.
ms=1 — the results are reported in “milliseconds per run”. Alternatively (ms=0), “runs per second” are reported instead.
dv=0 — the idle nodes are using <span> tag. Alternatively, (dv=1) <div> tag is used instead.
ns=N — the N idle nodes are added.
The idea behind the experiment is to check how much overhead is added as the number of extra idle nodes (ns=N) in the DOM tree increases. Since the browsers used in the experiments are not fair to compare due to various reasons,
instead of concrete numbers in milliseconds, the results are presented in relative terms for each browser separately. It means that the benchmarking result for ns=0 serves as a baseline, and other results show the relative duration
increase to that baseline result, where, e.g. a 300% increase means 3 times the baseline duration.
The results for a few mainstream browsers/browser engines (WebKit GTK MiniBrowser [09.09.2025], Chromium 140.0.7339.127, and Firefox 142.0) and a few experimental ones (Servo [04.07.2024] and Ladybird [30.06.2024])
are presented in the image below:
As the results show, trends among all the browsers are very close to linear. It means that the overhead is very easy to assess, as usually N times more idle nodes will result in N
times the overhead.
Moreover, up until 100-200 extra idle nodes in the tree, the overhead trends are very similar in all the browsers except for experimental Ladybird. That in turn means that even for big web applications, it’s safe to
assume the overhead among the browsers will be very much the same. Finally, past the 200 extra idle nodes threshold, the overhead across browsers diverges. It’s very likely due to the fact that the browsers are not
optimizing such cases as a result of a lack of real-world use cases.
All in all, the conclusion is that on desktop, only very large / specific web applications should be cautious about the overhead of nodes, as modern web browsers/engines are very well optimized for handling substantial amounts
of nodes in the DOM.
When it comes to the embedded devices, the above conclusions are no longer applicable. To demonstrate that, a minimal browser utilizing WPE WebKit is used to run the demo from the previous section both on desktop and
NXP i.MX8M Plus platforms. The latter is a popular choice for embedded applications as it has quite an interesting set of features while still having strong specifications, which may be compared to those of Raspberry Pi 5.
The results are presented in the image below:
This time, the Y axis presents the duration (in milliseconds) of a single benchmark run, and hence makes it very easy to reason about overhead. As the results show, in the case of the desktop, 100 extra idle nodes in the DOM
introduce barely noticeable overhead. On the other hand, on an embedded platform, even without any extra idle nodes, the time to change and layout the text is already taking around 0.6 ms. With 10 extra idle nodes, this
duration increases to 0.75 ms — thus yielding 0.15 ms overhead. With 100 extra idle nodes, such overhead grows to 1.3 ms.
One may argue if 1.3 ms is much, but considering an application that e.g. does 60 FPS rendering, the
time at application disposal each frame is below 16.67 ms, and 1.3 ms is ~8% of that, thus being very considerable. Similarly, for the application to be perceived as responsive, the input-to-output latency should usually
be under 20 ms. Again, 1.3 ms is a significant overhead for such a scenario.
Given the above, it’s safe to state that the 20 extra idle nodes should be considered the safe maximum for embedded devices in general. In case of low-end embedded devices i.e. ones comparable to Raspberry Pi 1 and 2,
the maximum should be even lower, but a proper benchmarking is required to come up with concrete numbers.
While the previous subsection demonstrated that on embedded devices, adding extra idle nodes as parents must usually be done in a responsible way, it’s worth examining if there are nuances that need to be considered as
well.
The first matter that one may wonder about is whether there’s any difference between the overhead of idle nodes being inlines (display: inline) or blocks (display: block). The intuition here may be that, as idle nodes
have no visual impact on anything, the overhead should be similar.
To verify the above, the demo from Desktop considerations section can be used with dv parameter used to control whether extra idle nodes should be blocks (1, <div>) or inlines (0, <span>).
The results from such experiments — again, executed on NXP i.MX8M Plus — are presented in the image below:
While in the safe range of 0-20 extra idle nodes the results are very much similar, it’s evident that in general, the idle nodes of block type are actually introducing more overhead.
The reason for the above is that, for layout purposes, the handling of inline and block elements is very different. The inline elements sharing the same line can be thought of as being flattened within so called
line box tree. The block elements, on the other hand, have to be represented in a tree.
To show the above visually, it’s interesting to compare sysprof flamegraphs of WPE WebProcess from the scenarios comprising 20 idle nodes and using either <span> or <div> for idle nodes:
idle <span> nodes:
idle <div> nodes:
The first flamegraph proves that there’s no clear dependency between the call stack and the number of idle nodes. The second one, on the other hand, shows exactly the opposite — each of the extra idle nodes is
visible as adding extra calls. Moreover, each of the extra idle block nodes adds some overhead thus making the flamegraph have a pyramidal shape.
Another nuance worth exploring is the overhead of text nodes created because of whitespaces.
When the DOM tree is created from the HTML, usually a lot of text nodes are created just because of whitespaces. It’s because the HTML usually looks like:
<span> <span> (...) </span> </span>
rather than:
<span><span>(...)</span></span>
which makes sense from the readability point of view. From the performance point of view, however, more text nodes naturally mean more overhead. When such redundant text nodes are combined with
idle nodes, the net outcome may be that with each extra idle node, some overhead will be added.
To verify the above hypothesis, the demo similar to the above one can be used along with the above one to perform a series of experiments comparing the approach with and without redundant whitespaces:
random-number-changing-in-the-tree-w-whitespaces.html?vr=0&ms=1&dv=0&ns=0.
The only difference between the demos is that the w-whitespaces one creates the DOM tree with artificial whitespaces, simulating as-if it was written in the formatted document. The comparison results
from the experiments run on NXP i.MX8M Plus are presented in the image below:
As the numbers suggest, the overhead of redundant text nodes is rather small on a per-idle-node basis. However, as the number of idle nodes scales, so does the overhead. Around 100 extra idle nodes, the
overhead is noticeable already. Therefore, a natural conclusion is that the redundant text nodes should rather be avoided — especially as the number of nodes in the tree becomes significant.
The last topic that deserves a closer look is whether adding idle nodes as siblings is better than adding them as parent nodes. In theory, having extra nodes added as siblings should be better as the layout engine
will have to consider them, yet it won’t mark them with a dirty flag and hence it won’t have to layout them.
The experiment results corroborate the theoretical considerations made above — idle nodes added as siblings indeed introduce less layout overhead. The savings are not very large from a single idle node perspective,
but once scaled enough, they are beneficial enough to justify DOM tree re-organization (if possible).
The above experiments mostly emphasized the idle nodes, however, the results can be extrapolated to regular nodes in the DOM tree. With that in mind, the overall conclusion to the experiments done in the former sections
is that DOM tree size and shape has a measurable impact on web application performance on embedded devices. Therefore, web developers should try to optimize it as early as possible and follow the general rules of thumb that
can be derived from this article:
Nodes are not free, so they should always be added with extra care.
Idle nodes should be limited to ~20 on mid-end and ~10 on low-end embedded devices.
Idle nodes should be inline elements, not block ones.
Redundant whitespaces should be avoided — especially with idle nodes.
Nodes (especially idle ones) should be added as siblings.
Although the above serves as great guidance, for better results, it’s recommended to do the proper browser benchmarking on a given target embedded device — as long as it’s feasible.
Also, the above set of rules is not recommended to follow on desktop-class devices, as in that case, it can be considered a premature optimization. Unless the particular web application yields an exceptionally large
DOM tree, the gains won’t be worth the time spent optimizing.
This article is a continuation of the series on damage propagation. While the previous article laid some foundation on the subject, this one
discusses the cost (increased CPU and memory utilization) that the feature incurs, as this is highly dependent on design decisions and the implementation of the data structure used for storing damage information.
From the perspective of this article, the two key things worth remembering from the previous one are:
The damage propagation is an optional WPE/GTK WebKit feature that — when enabled — reduces the browser’s GPU utilization at the expense of increased CPU and memory utilization.
On the implementation level, the damage is almost always a collection of rectangles that cover the changed region.
As mentioned in the section about damage of the previous article,
the damage information describes a region that changed and requires repainting. It was also pointed out that such a description is usually done via a collection of rectangles. Although sometimes
it’s better to describe a region in a different way, the rectangles are a natural choice due to the very nature of the damage in the web engines that originates from the box model.
A more detailed description of the damage nature can be inferred from the Pipeline details section of the
previous article. The bottom line is, in the end, the visual changes to the render tree yield the damage information in the form of rectangles.
For the sake of clarity, such original rectangles may be referred to as raw damage.
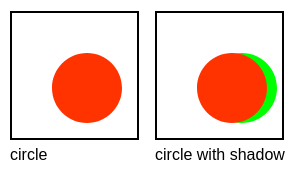
In practice, the above means that it doesn’t matter whether, e.g. the circle is drawn on a 2D canvas or the background color of some block element changes — ultimately, the rectangles (raw damage) are always produced
in the process.
As the raw damage is a collection of rectangles describing a damaged region, the geometrical consequence is that there may be more than one set of rectangles describing the same region.
It means that raw damage could be stored by a different set of rectangles and still precisely describe the original damaged region — e.g. when raw damage contains more rectangles than necessary.
The example of different approximations of a simple raw damage is depicted in the image below:
Changing the set of rectangles that describes the damaged region may be very tempting — especially when the size of the set could be reduced. However, the following consequences must be taken into account:
The damaged region could shrink when some damaging information would be lost e.g. if too many rectangles would be removed.
The damaged region could expand when some damaging information would be added e.g. if too many or too big rectangles would be added.
The first consequence may lead to visual glitches when repainting. The second one, however, causes no visual issues but degrades performance since a larger area
(i.e. more pixels) must be repainted — typically increasing GPU usage. This means the damage information can be approximated as long as the trade-off between the extra repainted area and the degree of simplification
in the underlying set of rectangles is acceptable.
The approximation mentioned above means the situation where the approximated damaged region covers the original damaged region entirely i.e. not a single pixel of information is lost. In that sense, the
approximation can only add extra information. Naturally, the lower the extra area added to the original damaged region, the better.
The approximation quality can be referred to as damage resolution, which is:
low — when the extra area added to the original damaged region is significant,
high — when the extra area added to the original damaged region is small.
The examples of low (left) and high (right) damage resolutions are presented in the image below:
Given the description of the damage properties presented in the sections above, it’s evident there’s a certain degree of flexibility when it comes to processing damage information. Such a situation is very fortunate in the
context of storing the damage, as it gives some freedom in designing a proper data structure. However, before jumping into the actual solutions, it’s necessary to understand the problem end-to-end.
layer damage — the damage tracked separately for each layer,
frame damage — the damage that aggregates individual layer damages and consists of the final damage of a given frame.
Assuming there are L layers and there is some data structure called Damage that can store the damage information, it’s easy to notice that there may be L+1 instances
of Damage present at the same time in the pipeline as the browser engine requires:
L Damage objects for storing layer damage,
1 Damage object for storing frame damage.
As there may be a lot of layers in more complex web pages, the L+1 mentioned above may be a very big number.
The first consequence of the above is that the Damage data structure in general should store the damage information in a very compact way to avoid excessive memory usage when L+1 Damage objects
are present at the same time.
The second consequence of the above is that the Damage data structure in general should be very performant as each of L+1 Damage objects may be involved into a considerable amount of processing when there are
lots of updates across the web page (and hence huge numbers of damage rectangles).
To better understand the above consequences, it’s essential to examine the input and the output of such a hypothetical Damage data structure more thoroughly.
The Damage becomes an input of other Damage in some situations, happening in the middle of the damage propagation pipeline when the broader damage is being assembled from smaller chunks of damage. What it consists
of depends purely on the Damage implementation.
The raw damage, on the other hand, becomes an input of the Damage always at the very beginning of the damage propagation pipeline. In practice, it consists of a set of rectangles that are potentially overlapping, duplicated, or empty. Moreover,
such a set is always as big as the set of changes causing visual impact. Therefore, in the worst case scenario such as drawing on a 2D canvas, the number of rectangles may be enormous.
Given the above, it’s clear that the hypothetical Damage data structure should support 2 distinct input operations in the most performant way possible:
When it comes to the Damage data structure output, there are 2 possibilities either:
other Damage,
the platform API.
The Damage becomes the output of other Damage on each Damage-to-Damage append that was described in the subsection above.
The platform API, on the other hand, becomes the output of Damage at the very end of the pipeline e.g. when the platform API consumes the frame damage (as described in the
pipeline details section of the previous article).
In this situation, what’s expected on the output technically depends on the particular platform API. However, in practice, all platforms supporting damage propagation require a set of rectangles that describe the damaged region.
Such a set of rectangles is fed into the platforms via APIs by simply iterating the rectangles describing the damaged region and transforming them to whatever data structure the particular API expects.
The natural consequence of the above is that the hypothetical Damage data structure should support the following output operation — also in the most performant way possible:
Given all the above perspectives, the problem of designing the Damage data structure can be summarized as storing the input damage information to be accessed (iterated) later in a way that:
the performance of operations for adding and iterating rectangles is maximal (performance),
the memory footprint of the data structure is minimal (memory footprint),
the stored region covers the original region and has the area as close to it as possible (damage resolution).
With the problem formulated this way, it’s obvious that this is a multi-criteria optimization problem with 3 criteria:
Given the problem of storing damage defined as above, it’s possible to propose various ways of solving it by implementing a Damage data structure. Before diving into details, however, it’s important to emphasize
that the weights of criteria may be different depending on the situation. Therefore, before deciding how to design the Damage data structure, one should consider the following questions:
What is the proportion between the power of GPU and CPU in the devices I’m targeting?
What are the memory constraints of the devices I’m targeting?
What are the cache sizes on the devices I’m targeting?
What is the balance between GPU and CPU usage in the applications I’m going to optimize for?
Are they more rendering-oriented (e.g. using WebGL, Canvas 2D, animations etc.)?
Are they more computing-oriented (frequent layouts, a lot of JavaScript processing etc.)?
Although answering the above usually points into the direction of specific implementation, usually the answers are unknown and hence the implementation should be as generic as possible. In practice,
it means the implementation should not optimize with a strong focus on just one criterion. However, as there’s no silver bullet solution, it’s worth exploring multiple, quasi-generic solutions that have been researched as
part of Igalia’s work on the damage propagation, and which are the following:
Damage storing all input rects,
Bounding box Damage,
Damage using WebKit’s Region,
R-Tree Damage,
Grid-based Damage.
All of the above implementations are being evaluated along the 3 criteria the following way:
Performance
by specifying the time complexity of add(Rectangle) operation as add(Damage) can be transformed into the series of add(Rectangle) operations,
by specifying the time complexity of forEachRectangle(...) operation.
Memory footprint
by specifying the space complexity of Damage data structure.
The most natural — yet very naive — Damage implementation is one that wraps a simple collection (such as vector) of rectangles and hence stores the raw damage in the original form.
In that case, the evaluation is as simple as evaluating the underlying data structure.
Assuming a vector data structure and O(1) amortized time complexity of insertion, the evaluation of such a Damage implementation is:
Performance
insertion is O(1) ✅
iteration is O(N) ❌
Memory footprint
O(N) ❌
Damage resolution
perfect ✅
Despite being trivial to implement, this approach is heavily skewed towards the damage resolution criterion. Essentially, the damage quality is the best possible, yet the expense is a very poor
performance and substantial memory footprint. It’s because a number of input rects N can be a very big number, thus making the linear complexities unacceptable.
The other problem with this solution is that it performs no filtering and hence may store a lot of redundant rectangles. While the empty rectangles can be filtered out in O(1),
filtering out duplicates and some of the overlaps (one rectangle completely containing the other) would make insertion O(N). Naturally, such a filtering
would lead to a smaller memory footprint and faster iteration in practice, however, their complexities would not change.
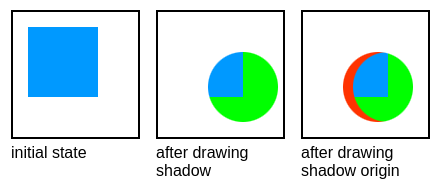
The second simplest Damage implementation one can possibly imagine is the implementation that stores just a single rectangle, which is a minimum bounding rectangle (bounding box) of all the damage
rectangles that were added into the data structure. The minimum bounding rectangle — as the name suggests — is a minimal rectangle that can fit all the input rectangles inside. This is well demonstrated in the picture below:
As this implementation stores just a single rectangle, and as the operation of taking the bounding box of two rectangles is O(1), the evaluation is as follows:
Performance
insertion is O(1) ✅
iteration is O(1) ✅
Memory footprint
O(1) ✅
Damage resolution
usually low ⚠️
Contrary to the Damage storing all input rects, this solution yields a perfect performance and memory footprint at the expense of low damage resolution. However,
in practice, the damage resolution of this solution is not always low. More specifically:
in the optimistic cases (raw damage clustered), the area of the bounding box is close to the area of the raw damage inside,
in the average cases, the approximation of the damaged region suffers from covering significant areas that were not damaged,
in the worst cases (small damage rectangles on the other ends of a viewport diagonal), the approximation is very poor, and it may be as bad as covering the whole viewport.
As this solution requires a minimal overhead while still providing a relatively useful damage approximation, in practice, it is a baseline solution used in:
Chromium,
Firefox,
WPE and GTK WebKit when UnifyDamagedRegions runtime preference is enabled, which means it’s used in GTK WebKit by default.
When it comes to more sophisticated Damage implementations, the simplest approach in case of WebKit is to wrap data structure already implemented in WebCore called
Region. Its purpose
is just as the name suggests — to store a region. More specifically, it’s meant to store rectangles describing region in an efficient way both for storage and for access to take advantage
of scanline coherence during rasterization. The key characteristic of the data structure is that it stores rectangles without overlaps. This is achieved by storing y-sorted lists of x-sorted, non-overlapping
rectangles. Another important property is that due to the specific internal representation, the number of integers stored per rectangle is usually smaller than 4. Also, there are some other useful properties
that are, however, not very useful in the context of storing the damage. More details on the data structure itself can be found in the J. E. Steinhart’s paper from 1991 titled
SCANLINE COHERENT SHAPE ALGEBRA
published as part of Graphics Gems II book.
The Damage implementation being a wrapper of the Region was actually used by GTK and WPE ports as a first version of more sophisticated Damage alternative for the bounding box Damage. Just as expected,
it provided better damage resolution in some cases, however, it suffered from effectively degrading to a more expensive variant bounding box Damage in the majority of situations.
The above was inevitable as the implementation was falling back to bounding box Damage when the Region’s internal representation was getting too complex. In essence, it was addressing the Region’s biggest problem,
which is that it can effectively store N2 rectangles in the worst case due to the way it splits rectangles for storing purposes. More specifically, as the Region stores ledges
and spans, each insertion of a new rectangle may lead to splitting O(N) existing rectangles. Such a situation is depicted in the image below, where 3 rectangles are being split
into 9:
Putting the above fallback mechanism aside, the evaluation of Damage being a simple wrapper on top of Region is the following:
Performance
insertion is O(logN) ✅
iteration is O(N2) ❌
Memory footprint
O(N2) ❌
Damage resolution
perfect ✅
Adding a fallback, the evaluation is technically the same as bounding box Damage for N above the fallback point, yet with extra overhead. At the same time, for smaller N, the above evaluation
didn’t really matter much as in such case all the performance, memory footprint, and the damage resolution were very good.
Despite this solution (with a fallback) yielded very good results for some simple scenarios (when N was small enough), it was not sustainable in the long run, as it was not addressing the majority of use cases,
where it was actually a bit slower than bounding box Damage while the results were similar.
In the pursuit of more sophisticated Damage implementations, one can think of wrapping/adapting data structures similar to quadtrees, KD-trees etc. However, in most of such cases, a lot of unnecessary overhead is added
as the data structures partition the space so that, in the end, the input is stored without overlaps. As overlaps are not necessarily a problem for storing damage information, the list of candidate data structures
can be narrowed down to the most performant data structures allowing overlaps. One of the most interesting of such options is the R-Tree.
In short, R-Tree (rectangle tree) is a tree data structure that allows storing multiple entries (rectangles) in a single node. While the leaf nodes of such a tree store the original
rectangles inserted into the data structure, each of the intermediate nodes stores the bounding box (minimum bounding rectangle, MBR) of the children nodes. As the tree is balanced, the above means that with every next
tree level from the top, the list of rectangles (either bounding boxes or original ones) gets bigger and more detailed. The example of the R-tree is depicted in the Figure 5 from
the Object Trajectory Analysis in Video Indexing and Retrieval Applications paper:
The above perfectly shows the differences between the rectangles on various levels and can also visually suggest some ideas when it comes to adapting such a data structure into Damage:
The first possibility is to make Damage a simple wrapper of R-Tree that would just build the tree and allow the Damage consumer to pick the desired damage resolution on iteration attempt. Such an approach is possible
as having the full R-Tree allows the iteration code to limit iteration to a certain level of the tree or to various levels from separate branches. The latter allows Damage to offer a particularly interesting API where the
forEachRectangle(...) function could accept a parameter specifying how many rectangles (at most) are expected to be iterated.
The other possibility is to make Damage an adaptation of R-Tree that conditionally prunes the tree while constructing it not to let it grow too much, yet to maintain a certain height and hence certain damage quality.
Regardless of the approach, the R-Tree construction also allows one to implement a simple filtering mechanism that eliminates input rectangles being duplicated or contained by existing rectangles on the fly. However,
such a filtering is not very effective as it can only consider a limited set of rectangles i.e. the ones encountered during traversal required by insertion.
Damage as a simple R-Tree wrapper
Although this option may be considered very interesting, in practice, storing all the input rectangles in the R-Tree means storing N rectangles along with the overhead of a tree structure. In the worst case scenario
(node size of 2), the number of nodes in the tree may be as big as O(N), thus adding a lot of overhead required to maintain the tree structure. This fact alone makes this solution have an
unacceptable memory footprint. The other problem with this idea is that in practice,
the damage resolution selection is usually done once — during browser startup. Therefore, the ability to select damage resolution during runtime brings no benefits while introduces unnecessary overhead.
The evaluation of the above is the following:
Performance
insertion is O(logMN) where M is the node size ✅
iteration is O(K) where K is a parameter and 0≤K≤N ✅
Memory footprint
O(N) ❌
Damage resolution
low to high ✅
Damage as an R-Tree adaptation with pruning
Considering the problems the previous idea has, the option with pruning seems to be addressing all the problems:
the memory footprint can be controlled by specifying at which level of the tree the pruning should happen,
the damage resolution (level of the tree where pruning happens) can be picked on the implementation level (compile time), thus allowing some extra implementation tricks if necessary.
While it’s true the above problems are not existing within this approach, the option with pruning — unfortunately — brings new problems that need to be considered. As a matter of fact, all the new problems it brings
are originating from the fact that each pruning operation leads to the loss of information and hence to the tree deterioration over time.
Before actually introducing those new problems, it’s worth understanding more about how insertions work in the R-Tree.
When the rectangle is inserted to the R-Tree, the first step is to find a proper position for the new record (see ChooseLeaf algorithm from Guttman1984). When the target node is
found, there are two possibilities:
adding the new rectangle to the target node does not cause overflow,
adding the new rectangle to the target node causes overflow.
If no overflow happens, the new rectangle is just added to the target node. However, if overflow happens i.e. the number of rectangles in the node exceeds the limit, the node splitting algorithm is invoked (see SplitNode
algorithm from Guttman1984) and the changes are being propagated up the tree (see ChooseLeaf algorithm from Guttman1984).
The node splitting, along with adjusting the tree, are very important steps within insertion as those algorithms are the ones that are responsible for shaping and balancing the tree. For example, when all the nodes in the tree are
full and the new rectangle is being added, the node splitting will effectively be executed for some leaf node and all its ancestors, including root. It means that the tree will grow and possibly, its structure will change significantly.
Due to the above mechanics of R-Tree, it can be reasonably asserted that the tree structure becomes better as a function of node splits. With that, the first problem of the tree pruning becomes obvious:
tree pruning on insertion limits the amount of node splits (due to smaller node splits cascades) and hence limits the quality of the tree structure. The second problem — also related to node splits — is that
with all the information lost due to pruning (as pruning is the same as removing a subtree and inserting its bounding box into the tree) each node split is less effective as the leaf rectangles themselves are
getting bigger and bigger due to them becoming bounding boxes of bounding boxes (…) of the original rectangles.
The above problems become more visible in practice when the R-tree input rectangles tend to be sorted. In general, one of the R-Tree problems is that its structure tends to be biased when the input rectangles are sorted.
Despite the further insertions usually fix the structure of the biased tree, it’s only done to some degree, as some tree nodes may not get split anymore. When the pruning happens and the input is sorted (or partially sorted)
the fixing of the biased tree is much harder and sometimes even impossible. It can be well explained with the example where a lot of rectangles from the same area are inserted into the tree. With the number of such rectangles
being big enough, a lot of pruning will happen and hence a lot of rectangles will be lost and replaced by larger bounding boxes. Then, if a series of new insertions will start inserting nodes from a different area which is
partially close to the original one, the new rectangles may end up being siblings of those large bounding boxes instead of the original rectangles that could be clustered within nodes in a much more reasonable way.
Given the above problems, the evaluation of the whole idea of Damage being the adaptation of R-Tree with pruning is the following:
Performance
insertion is O(logMK) where M is the node size, K is a parameter, and 0<K≤N ✅
iteration is O(K) ✅
Memory footprint
O(K) ✅
Damage resolution
low to medium ⚠️
Despite the above evaluation looks reasonable, in practice, it’s very hard to pick the proper pruning strategy. When the tree is allowed to be taller, the damage resolution is usually better, but the increased memory footprint,
logarithmic insertions, and increased iteration time combined pose a significant problem. On the other hand, when the tree is shorter, the damage resolution tends to be low enough not to justify using R-Tree.
The last, more sophisticated Damage implementation, uses some ideas from R-Tree and forms a very strict, flat structure. In short, the idea is to take some rectangular part of a plane and divide it into cells,
thus forming a grid with C columns and R rows. Given such a division, each cell of the grid is meant to store at most one rectangle that effectively is a bounding box of the rectangles matched to
that cell. The overview of the approach is presented in the image below:
As the above situation is very straightforward, one may wonder what would happen if the rectangle would span multiple cells i.e. how the matching algorithm would work in that case.
Before diving into the matching, it’s important to note that from the algorithmic perspective, the matching is very important as it accounts for the majority of operations during new rectangle insertion into the Damage data structure.
It’s because when the matched cell is known, the remaining part of insertion is just about taking the bounding box of existing rectangle stored in the cell and the new rectangle, thus having
O(1) time complexity.
As for the matching itself, it can be done in various ways:
it can be done using strategies known from R-Tree, such as matching a new rectangle into the cell where the bounding box enlargement would be the smallest etc.,
it can be done by maximizing the overlap between the new rectangle and the given cell,
it can be done by matching the new rectangle’s center (or corner) into the proper cell,
etc.
The above matching strategies fall into 2 categories:
O(CR) matching algorithms that compare a new rectangle against existing cells while looking for the best match,
O(1) matching algorithms that calculate the target cell using a single formula.
Due to the nature of matching, the O(CR) strategies eventually lead to smaller bounding boxes stored in the Damage and hence to better damage resolution as compared to the
O(1) algorithms. However, as the practical experiments show, the difference in damage resolution is not big enough to justify O(CR)
time complexity over O(1). More specifically, the difference in damage resolution is usually unnoticeable, while the difference between
O(CR) and O(1) insertion complexity is major, as the insertion is the most critical operation of the Damage data structure.
Due to the above, the matching method that has proven to be the most practical is matching the new rectangle’s center into the proper cell. It has O(1) time complexity
as it requires just a few arithmetic operations to calculate the center of the incoming rectangle and to match it to the proper cell (see
the implementation in WebKit). The example of such matching is presented in the image below:
The overall evaluation of the grid-based Damage constructed the way described in the above paragraphs is as follows:
performance
insertion is O(1) ✅
iteration is O(CR) ✅
memory footprint
O(CR) ✅
damage resolution
low to high (depending on the CR) ✅
Clearly, the fundamentals of the grid-based Damage are strong, but the data structure is heavily dependent on the CR. The good news is that, in practice, even a fairly small grid such as 8x4
(CR=32)
yields a damage resolution that is high. It means that this Damage implementation is a great alternative to bounding box Damage as even with very small performance and memory footprint overhead,
it yields much better damage resolution.
Moreover, the grid-based Damage implementation gives an opportunity for very handy optimizations that improve memory footprint, performance (iteration), and damage resolution further.
As the grid dimensions are given a-priori, one can imagine that intrinsically, the data structure needs to allocate a fixed-size array of rectangles with CR entries to store cell bounding boxes.
One possibility for improvement in such a situation (assuming small CR) is to use a vector along with bitset so that only non-empty cells are stored in the vector.
The other possibility (again, assuming small CR) is to not use a grid-based approach at all as long as the number of rectangles inserted so far does not exceed CR.
In other words, the data structure can allocate an empty vector of rectangles upon initialization and then just append new rectangles to the vector as long as the insertion does not extend the vector beyond
CR entries. In such a case, when CR is e.g. 32, up to 32 rectangles can be stored in the original form. If at some point the data structure detects that it would need to
store 33 rectangles, it switches internally to a grid-based approach, thus always storing at most 32 rectangles for cells. Also, note that in such a case, the first improvement possibility (with bitset) can still be used.
Summarizing the above, both improvements can be combined and they allow the data structure to have a limited, small memory footprint, good performance, and perfect damage resolution as long as there
are not too many damage rectangles. And if the number of input rectangles exceeds the limit, the data structure can still fall-back to a grid-based approach and maintain very good results. In practice, the situations
where the input damage rectangles are not exceeding CR (e.g. 32) are very common, and hence the above improvements are very important.
Overall, the grid-based approach with the above improvements has proven to be the best solution for all the embedded devices tried so far, and therefore, such a Damage implementation is a baseline solution used in
WPE and GTK WebKit when UnifyDamagedRegions runtime preference is not enabled — which means it works by default in WPE WebKit.
The former sections demonstrated various approaches to implementing the Damage data structure meant to store damage information. The summary of the results is presented in the table below:
While all the solutions have various pros and cons, the Bounding box and Grid-basedDamage implementations are the most lightweight and hence are most useful in generic use cases.
On typical embedded devices — where CPUs are quite powerful compared to GPUs — both above solutions are acceptable, so the final choice can be determined based on the actual use case. If the actual web application
often yields clustered damage information, the Bounding boxDamage implementation should be preferred. Otherwise (majority of use cases), the Grid-basedDamage implementation will work better.
On the other hand, on desktop-class devices – where CPUs are far less powerful than GPUs – the only acceptable solution is Bounding boxDamage as it has a minimal overhead while it sill provides some
decent damage resolution.
The above are the reasons for the default Damage implementations used by desktop-oriented GTK WebKit port (Bounding boxDamage) and embedded-device-oriented WPE WebKit (Grid-basedDamage).
When it comes to non-generic situations such as unusual hardware, specific applications etc. it’s always recommended to do a proper evaluation to determine which solution is the best fit. Also, the Damage implementations
other than the two mentioned above should not be ruled out, as in some exotic cases, they may give much better results.
WebKitGTK has a bunch of different confusing API versions. Here are the three API versions that are currently supported by upstream:
webkitgtk-6.0: This is WebKitGTK for GTK 4 (and libsoup 3), introduced in WebKitGTK 2.40. This is what’s built by default if you build WebKit with -DPORT=GTK.
webkit2gtk-4.1: This is WebKitGTK for GTK 3 and libsoup 3, introduced in WebKitGTK 2.32. Get this by building with -DPORT=GTK -DUSE_GTK3=ON.
webkit2gtk-4.0: This is WebKitGTK for GTK 3 and libsoup 2, introduced in WebKitGTK 2.6. Get this by building with -DPORT=GTK -DUSE_GTK3=ON -DUSE_SOUP2=ON.
webkitgtk-6.0 contains a bunch of API changes, and all deprecated APIs were removed. If you’re upgrading to webkitgtk-6.0, then you’re also upgrading your application from GTK 3 to GTK 4, and have to adapt to much bigger GTK API changes anyway, so this seemed like a good opportunity to break compatibility and fix old mistakes for the first time in a very long time.
webkit2gtk-4.1 is exactly the same as webkit2gtk-4.0, except for the libsoup API version that it links against.
webkit2gtk-4.0 is — remarkably — mostly API stable since it was released in September 2014. Some particular C APIs have been deprecated and don’t work properly anymore, but no stable C APIs have been removed during this time, and library ABI is maintained. (Caveat: WebKitGTK used to have unstable DOM APIs, some of which were removed before the DOM API was eventually stabilized. Nowadays, the DOM APIs are all stable but deprecated in webkit2gtk-4.1 and webkit2gtk-4.0, and removed in webkitgtk-6.0.)
If you are interested in history, here are the older API versions that do not matter anymore:
webkit2gtk-5.0: This was an unstable API version used during development of the GTK 4 API, intended for WebKit developers rather than application developers. It was obsoleted by webkitgtk-6.0.
webkit2gtk-3.0: original API version of WebKitGTK for GTK 3 and libsoup 2, obsoleted by webkit2gtk-4.0. This was the original “WebKit 2” API version, which was only used by a few applications before it was removed one decade ago (history).
webkitgtk-3.0: note the missing “2”, this is “WebKit 1” (predating the modern multiprocess architecture) for GTK 3. This API version was widely-used on Linux, and its removal one decade ago precipitated a security crisis which I called The Great API Break. (This crisis was worth it. Modern WebKit’s multiprocess architecture is far more secure than the old single-process architecture.)
webkitgtk-1.0: the original WebKitGTK API version, this is “WebKit 1” for GTK 2. This API version was also widely-used on Linux before it was removed in The Great API Break.
Fedora and RHEL users, are you confused by all the different confusing downstream package names? Here is your map:
webkitgtk6.0, webkit2gtk4.1, and webkit2gtk4.0: This is the current binary package naming in Fedora, corresponding precisely to the WebKitGTK API version to reduce confusion.
webkit2gtk3: old name for webkit2gtk4.0, still used in RHEL 9 and RHEL 8
webkitgtk4: even older name for webkit2gtk4.0, still used in RHEL 7
webkitgtk3: this is the webkitgtk-3.0 API version, still used in RHEL 7
webkitgtk: this is webkitgtk-1.0, used in RHEL 6
Notably, webkit2gtk4.0, webkit2gtk3, and webkitgtk4 are all the same thing.
With the release of GStreamer 1.26, we now have playback support for Versatile Video Coding (VVC/H.266). In this post, I’ll describe the pieces of the puzzle that enable this, the contributions that led to it, and hopefully provide a useful guideline to adding a new video codec in GStreamer.
With GStreamer 1.26 and the relevant plugins enabled, one can play multimedia files containing VVC content, for example, by using gst-play-1.0:
gst-play-1.0 vvc.mp4
By using gst-play-1.0, a pipeline using playbin3 will be created and the appropriate elements will be auto-plugged to decode and present the VVC content. Here’s what such a pipeline looks like:
Although the pipeline is quite large, the specific bits we’ll focus on in this blog are inside parsebin and decodebin3:
qtdemux → ... → h266parse → ... → avdec_h266
I’ll explain what each of those elements is doing in the next sections.
To store multiple kinds of media (e.g. video, audio and captions) in a way that keeps them synchronized, we typically make use of container formats. This process is usually called muxing, and in order to play back the file we perform de-muxing, which separates the streams again. That is what the qtdemux element is doing in the pipeline above, by extracting the audio and video streams from the input MP4 file and exposing them as the audio_0 and video_0 pads.
Support for muxing and demuxing VVC streams in container formats was added to:
qtmux and qtdemux: for ISOBMFF/QuickTime/MP4 files (often saved with the .mp4 extension)
mpegtsmux and tsdemux: for MPEG transport stream (MPEG-TS) files (often saved with the .ts extension)
Besides the fact that the demuxers are used for playback, by also adding support to VVC in the muxer elements we are then also able to perform remuxing: changing the container format without transcoding the underlying streams.
Some examples of simplified re-muxing pipelines (only taking into account the VVC video stream):
But why do we need h266parse when re-muxing from Matroska to MPEG-TS? That’s what I’ll explain in the next section.
Parsing and converting between VVC bitstream formats #
Video codecs like H.264, H.265, H.266 and AV1 may have different stream formats, depending on which container format is used to transport them. For VVC specifically, there are two main variants, as shown in the caps for h266parse:
Pad Templates: SINK template:'sink' Availability: Always Capabilities: video/x-h266
byte-stream or so-called Annex-B format (as in Annex B from the VVC specification): it separates the NAL units by start code prefixes (0x000001 or 0x00000001), and is the format used in MPEG-TS, or also when storing VVC bitstreams in files without containers (so-called “raw bitstream files”).
ℹ️ Note: It’s also possible to play raw VVC bitstream files with gst-play-1.0. That is achieved by the typefind element detecting the input file as VVC and playbin taking care of auto-plugging the elements.
vvc1 and vvi1: those formats use length field prefixes before each NAL unit. The difference between the two formats is the way that parameter sets (e.g. SPS, PPS, VPS NALs) are stored, and reflected in the codec_data field in GStreamer caps. For vvc1, the parameter sets are stored as container-level metadata, while vvi1 allows for the parameter sets to be stored also in the video bitstream.
The alignment field in the caps signals whether h266parse will collect multiple NALs into an Access Unit (AU) for a single GstBuffer, where an AU is the smallest unit for a decodable video frame, or whether each buffer will carry only one NAL.
That explains why we needed the h266parse when converting from MKV to MPEG-TS: it’s converting from vvc1/vvi1 to byte-stream! So the gst-launch-1.0 command with more explicit caps would be:
FFmpeg 7.1 has a native VVC decoder which is considered stable. In GStreamer 1.26, we have allowlisted that decoder in gst-libav, and it is now exposed as the avdec_h266 element.
Intel has added the vah266dec element in GStreamer 1.26, which enables hardware-accelerated VVC decoding on Intel Lunar Luke CPUs. However, it still has rank of 0 in GStreamer 1.26, so in order to test it out, one would need to, for example, manually set GST_PLUGIN_FEATURE_RANK.
Similar to h266parse, initially vah266dec was added with support for only the byte-stream format. I implemented support for the vvc1 and vvi1 modes in the base h266decoder class, which fixes the support for them in vah266dec as well. However, it hasn’t yet been merged and I don’t expect it to be backported to 1.26, so likely it will only be available in GStreamer 1.28.
Here’s a quick demo of vah266dec in action on an ASUS ExpertBook P5. In this screencast, I perform the following actions:
Run vainfo and display the presence of VVC decoding profile
gst-inspect vah266dec
export GST_PLUGIN_FEATURE_RANK='vah266dec:max'
Start playback of six simultaneous 4K@60 DASH VVC streams. The stream in question is the classic Tears of Steel, sourced from the DVB VVC test streams.
Run nvtop, showing GPU video decoding & CPU usage per process.
A tool that is handy for testing the new decoder elements is Fluster. It simplifies the process of testing decoder conformance and comparing decoders by using test suites that are adopted by the industry. It’s worth checking it out, and it’s already common practice to test new decoders with this test framework. I added the GStreamer VVC decoders to it: vvdec, avdec_h266 and vah266dec.
We’re still missing the ability to encode VVC video in GStreamer. I have a work-in-progress branch that adds the vvenc element, by using VVenC and safe Rust bindings (similarly to the vvdec element), but it still needs some work. I intend to work on it during the GStreamer Spring Hackfest 2025 to make it ready to submit upstream 🤞
In my previous post, when I introduced the switch to Skia for 2D rendering, I explained that we replaced Cairo with Skia keeping mostly the same architecture. This alone was an important improvement in performance, but still the graphics implementation was designed for Cairo and CPU rendering. Once we considered the switch to Skia as stable, we started to work on changes to take more advantage of Skia and GPU rendering to improve the performance even more. In this post I’m going to present some of those improvements and other not directly related to Skia and GPU rendering.
Explicit fence support
This is related to the DMA-BUF renderer used by the GTK port and WPE when using the new API. The composited buffer is shared as a DMA-BUF between the web and UI processes. Once the web process finished the composition we created a fence and waited for it, to make sure that when the UI process was notified that the composition was done the buffer was actually ready. This approach was safe, but slow. In 281640@main we introduced support for explicit fencing to the WPE port. When possible, an exportable fence is created, so that instead of waiting for it immediately, we export it as a file descriptor that is sent to the UI process as part of the message that notifies that a new frame has been composited. This unblocks the web process as soon as composition is done. When supported by the platform, for example in WPE under Wayland when the zwp_linux_explicit_synchronization_v1 protocol is available, the fence file descriptor is passed to the platform implementation. Otherwise, the UI process asynchronously waits for the fence by polling the file descriptor before passing the buffer to the platform. This is what we always do in the GTK port since 281744@main. This change improved the score of all MotionMark tests, see for example multiply.
Enable MSAA when available
In 282223@main we enabled the support for MSAA when possible in the WPE port only, because this is more important for embedded devices where we use 4 samples providing good enough quality with a better performance. This change improved the Motion Mark tests that use 2D canvas like canvas arcs, paths and canvas lines. You can see here the change in paths when run in a RaspberryPi 4 with WPE 64 bits.
Avoid textures copies in accelerated 2D canvas
As I also explained in the previous post, when 2D canvas is accelerated we now use a dedicated layer that renders into a texture that is copied to be passed to the compositor. In 283460@main we changed the implementation to use a CoordinatedPlatformLayerBufferNativeImage to handle the canvas texture and avoid the copy, directly passing the texture to the compositor. This improved the MotionMark tests that use 2D canvas. See canvas arcs, for example.
Introduce threaded GPU painting mode
In the initial implementation of the GPU rendering mode, layers were painted in the main thread. In 287060@main we moved the rendering task to a dedicated thread when using the GPU, with the same threaded rendering architecture we have always used for CPU rendering, but limited to 1 worker thread. This improved the performance of several MotionMark tests like images, suits and multiply. See images.
Update default GPU thread settings
Parallelization is not so important for GPU rendering compared to CPU, but still we realized that we got better results by increasing a bit the amount of worker threads when doing GPU rendering. In 290781@main we increased the limit of GPU worker threads to 2 for systems with at least 4 CPU cores. This improved mainly images and suits in MotionMark. See suits.
Hybrid threaded CPU+GPU rendering mode
We had either GPU or CPU worker threads for layer rendering. In systems with 4 CPU cores or more we now have 2 GPU worker threads. When those 2 threads are busy rendering, why not using the CPU to render other pending tiles? And the same applies when doing CPU rendering, when all workers are busy, could we use the GPU to render other pending tasks? We tried and turned out to be a good idea, especially in embedded devices. In 291106@main we introduced the hybrid mode, giving priority to GPU or CPU workers depending on the default rendering mode, and also taking into account special cases like on HiDPI, where we are always scaling, and we always prefer the GPU. This improved multiply, images and suits. See images.
Use Skia API for display list implementation
When rendering with Cairo and threaded rendering enabled we use our own implementation of display lists specific to Cairo. When switching to Skia we thought it was a good idea to use the WebCore display list implementation instead, since it’s cross-platform implementation shared with other ports. But we realized this implementation is not yet ready to support multiple threads, because it holds references to WebCore objects that are not thread safe. Main thread might change those objects before they have been processed by painting threads. So, we decided to try to use the Skia API (SkPicture) that supports recording in the main thread and replaying from worker threads. In 292639@main we replaced the WebCore display list usage by SkPicture. This was expected to be a neutral change in terms of performance but it surprisingly improved several MotionMark tests like leaves, multiply and suits. See leaves.
Use Damage to track the dirty region of GraphicsLayer
Every time there’s a change in a GraphicsLayer and it needs to be repainted, it’s notified and the area that changed is included so that we only render the parts of the layer that changed. That’s what we call the layer dirty region. It can happen that when there are many small updates in a layer we end up with lots of dirty regions on every layer flush. We used to have a limit of 32 dirty regions per layer, so that when more than 32 are added we just united them into the first dirty area. This limit was removed because we always unite the dirty areas for the same tiles when processing the updates to prepare the rendering tasks. However, we also tried to avoid handling the same dirty region twice, so every time a new dirty region was added we iterated the existing regions to check if it was already present. Without the 32 regions limit that means we ended up iterating a potentially very long list on every dirty region addition. The damage propagation feature uses a Damage class to efficiently handle dirty regions, so we thought we could reuse it to track the layer dirty region, bringing back the limit but uniting in a more efficient way than using always the first dirty area of the list. It also allowed to remove check for duplicated area in the list. This change was added in 292747@main and improved the performance of MotionMark leaves and multiply tests. See leaves.
Record all dirty tiles of a layer once
After the switch to use SkPicture for the display list implementation, we realized that this API would also allow to record the graphics layer once, using the bounding box of the dirty region, and then replay multiple times on worker threads for every dirty tile. Recording can be a very heavy operation, specially when there are shadows or filters, and it was always done for every tile due to the limitations of the previous display list implementation. In 292929@main we introduced the change with improvements in MotionMark leaves and multiply tests. See multiply.
MotionMark results
I’ve shown here the improvements of these changes in some of the MotionMark tests. I have to say that some of those changes also introduced small regressions in other tests, but the global improvement is still noticeable. Here is a table with the scores of all tests before these improvements and current main branch run by WPE MiniBrowser in a RaspberryPi 4 (64bit).
Test
Score July 2024
Score April 2025
Multiply
501.17
684.23
Canvas arcs
140.24
828.05
Canvas lines
1613.93
3086.60
Paths
375.52
4255.65
Leaves
319.31
470.78
Images
162.69
267.78
Suits
232.91
445.80
Design
33.79
64.06
What’s next?
There’s still quite a lot of room for improvement, so we are already working on other features and exploring ideas to continue improving the performance. Some of those are:
Damage tracking: this feature is already present, but disabled by default because it’s still work in progress. We currently use the damage information to only paint the areas of every layer that changed. But then we always compose a whole frame inside WebKit that is passed to the UI process to be presented on screen. It’s possible to use the damage information to improve both, the composition inside WebKit and the presentation of the composited frame on the screen. For more details about this feature read Pawel’s awesome blog post about it.
Use DMA-BUF for tile textures to improve pixel transfer operations: We currently use DMA-BUF buffers to share the composited frame between the web and UI process. We are now exploring the idea of using DMA-BUF also for the textures used by the WebKit compositor to generate the frame. This would allow to improve the performance of pixel transfer operations, for example when doing CPU rendering we need to upload the dirty regions from main memory to a compositor texture on every composition. With DMA-BUF backed textures we can map the buffer into main memory and paint with the CPU directly into the mapped buffer.
Compositor synchronization: We plan to try to improve the synchronization of the WebKit compositor with the system vblank and the different sources of composition (painted layers, video layers, CSS animations, WebGL, etc.)
Damage propagation is an optional WPE/GTK WebKit feature that — when enabled — reduces browser’s GPU utilization at the expense of increased CPU and memory utilization. It’s very useful especially in the context of low- and mid-end
embedded devices, where GPUs are most often not too powerful and thus become a performance bottleneck in many applications.
In computer graphics, the damage term is usually used in the context of repeatable rendering and means essentially “the region of a rendered scene that changed and requires repainting”.
In the context of WebKit, the above definition may be specialized a bit as WebKit’s rendering engine is about rendering web content to frames (passed further to the platform) in response to changes within a web page.
Thus the definition of WebKit’s damage refers, more specifically, to “the region of web page view that changed since previous frame and requires repainting”.
On the implementation level, the damage is almost always a collection of rectangles that cover the changed region. This is exactly the case for WPE and GTK WebKit ports.
To better understand what the above means, it’s recommended to carefully examine the below screenshot of GTK MiniBrowser as it depicts the rendering of the poster circle demo
with the damage visualizer activated:
In the image above, one can see the following elements:
the web page view — marked with a rectangle stroked to magenta color,
the damage — marked with red rectangles,
the browser elements — everything that lays above the rectangle stroked to a magenta color.
What the above image depicts in practice, is that during that particular frame rendering, the area highlighted red (the damage) has changed and needs to be repainted. Thus — as expected — only the moving parts of the demo require repainting.
It’s also worth emphasizing that in that case, it’s also easy to see how small fraction of the web page view requires repainting. Hence one can imagine the gains from the reduced amount of painting.
Normally, the job of the rendering engine is to paint the contents of a web page view to a frame (or buffer in more general terms) and provide such rendering result to the platform on every scene rendering iteration —
which usually is 60 times per second.
Without the damage propagation feature, the whole frame is marked as changed (the whole web page view) always. Therefore, the platform has to perform the full update of the pixels it has 60 times per second.
While in most of the use cases, the above approach is good enough, in the case of embedded devices with less powerful GPUs, this can be optimized. The basic idea is to produce the frame along with the damage information i.e. a hint for
the platform on what changed within the produced frame. With the damage provided (usually as an array of rectangles), the platform can optimize a lot of its operations as — effectively — it can
perform just a partial update of its internal memory. In practice, this usually means that fewer pixels require updating on the screen.
For the above optimization to work, the damage has to be calculated by the rendering engine for each frame and then propagated along with the produced frame up to its final destination. Thus the damage propagation can be summarized
as continuous damage calculation and propagation throughout the web engine.
Once the general idea has been highlighted, it’s possible to examine the damage propagation in more detail. Before reading further, however, it’s highly recommended for the reader to go carefully through the
famous “WPE Graphics architecture” article that gives a good overview of the WebKit graphics pipeline in general and which introduces the basic terminology
used in that context.
The information on the visual changes within the web page view has to travel a very long way before it reaches the final destination. As it traverses the thread and process boundaries in an orderly manner, it can be summarized
as forming a pipeline within the broader graphics pipeline. The image below presents an overview of such damage propagation pipeline:
This pipeline starts with the changes to the web page view visual state (RenderTree) being triggered by one of many possible sources. Such sources may include:
User interactions — e.g. moving mouse cursor around (and hence hovering elements etc.), typing text using keyboard etc.
Web API usage — e.g. the web page changing DOM, CSS etc.
multimedia — e.g. the media player in a playing state,
and many others.
Once the changes are induced for certain RenderObjects, their visual impact is calculated and encoded as rectangles called dirty as they
require re-painting within a GraphicsLayer the particular RenderObject
maps to. At this point, the visual changes may simply be called layer damage as the dirty rectangles are stored in the layer coordinate space and as they describe what changed within that certain layer since the last frame was rendered.
The next step in the pipeline is passing the layer damage of each GraphicsLayer
(GraphicsLayerCoordinated) to the WebKit’s compositor. This is done along with any other layer
updates and is mostly covered by the CoordinatedPlatformLayer.
The “coordinated” prefix of that name is not without meaning. As threaded accelerated compositing is usually used nowadays, passing the layer damage to the WebKit’s compositor must be coordinated between the main thread and
the compositor thread.
When the layer damage of each layer is passed to the WebKit’s compositor, it’s stored in the TextureMapperLayer that corresponds to the given
layer’s CoordinatedPlatformLayer. With that — and with all other layer-level updates — the
WebKit’s compositor can start computing the frame damage i.e. damage that is the final damage to be passed to the very end of the pipeline.
The first step to building frame damage is to process the layer updates. Layer updates describe changes of various layer properties such as size, position, transform, opacity, background color, etc. Many of those updates
have a visual impact on the final frame, therefore a portion of frame damage must be inferred from those changes. For example, a layer’s transform change that effectively changes the layer position means that the layer
visually disappears from one place and appears in the other. Thus the frame damage has to account for both the layer’s old and new position.
Once the layer updates are processed, WebKit’s compositor has a full set of information to take the layer damage of each layer into account. Thus in the second step, WebKit’s compositor traverses the tree formed out of
TextureMapperLayer objects and collects their layer damages. Once the layer damage of a certain layer
is collected, it’s transformed from the layer coordinate space into a global coordinate space so that it can be added to the frame damage directly.
After those two steps, the frame damage is ready. At this point, it can be used for a couple of extra use cases:
for WebKit’s compositor itself to perform some extra optimizations — as will be explained in the WebKit’s compositor optimizations section,
for layout tests.
Eventually — regardless of extra uses — the WebKit’s compositor composes the frame and sends it (a handle to it) to the UI Process along with frame damage using the IPC mechanism.
In the UI process, there are basically two options determining frame damage destiny — it can be either consumed or ignored — depending on the platform-facing implementation. At the moment of writing:
At the moment of writing, the damage propagation feature is run-time-disabled by default (PropagateDamagingInformation feature flag) and compile-time enabled by default for GTK and WPE (with new platform API) ports.
Overall, the feature works pretty well in the majority of real-world scenarios. However, there are still some uncovered code paths that lead to visual glitches. Therefore it’s fair to say the feature is still a work in progress.
The work, however, is pretty advanced. Moreover, the feature is set to a testable state and thus it’s active throughout all the layout test runs on CI.
Not only the feature is tested by every layout test that tests any kind of rendering, but it also has quite a lot of dedicated layout tests.
Not to mention the unit tests covering the Damage class.
In terms of functionalities, when the feature is enabled it:
activates the damage propagation pipeline and hence propagates the damage up to the platform,
When the feature is enabled, the main goal is to activate the damage propagation pipeline so that eventually the damage can be provided to the platform. However, in reality, a substantial part of the pipeline is always active
regardless of the features being enabled or compiled. This part of the pipeline ends before the damage reaches
CoordinatedPlatformLayer and is always active because it was used for layer-level optimizations for a long time.
More specifically — this part of the pipeline existed long before the damage propagation feature and was using layer damage to optimize the layer painting to the intermediate surfaces.
Because of the above, when the feature is enabled, only the part of the pipeline that starts with CoordinatedPlatformLayer
is activated. It is, however, still a significant portion of the pipeline and therefore it implies additional CPU/memory costs.
When the feature is activated and the damage flows through the WebKit’s compositor, it creates a unique opportunity for the compositor to utilize that information and reduce the amount of painting/compositing it has to perform.
At the moment of writing, the GTK/WPE WebKit’s compositor is using the damage to optimize the following:
to apply global glScissor to define the smallest possible clipping rect for all the painting it does — thus reducing the amount of painting,
to reduce the amount of painting when compositing the tiles of the layers using tiled backing stores.
Detailed descriptions of the above optimizations are well beyond the scope of this article and thus will be provided in one of the next articles on the subject of damage propagation.
As mentioned in the above sections, the feature only works in the GTK and the new-platform-API-powered WPE ports. This means that:
In the case of GTK, one can use MiniBrowser or any up-to-date GTK-WebKit-derived browser to test the feature.
In the case of WPE with the new WPE platform API the cog browser cannot be used as it uses the old API. Therefore, one has to use MiniBrowser
with the --use-wpe-platform-api argument to activate the new WPE platform API.
Moreover, as the feature is run-time-disabled by default, it’s necessary to activate it. In the case of MiniBrowser, the switch is --features=+PropagateDamagingInformation.
For quick testing, it’s highly recommended to use the latest revision of WebKit@main with wkdev SDK container and with GTK port.
Assuming one has set up the container, the commands to build and run GTK’s MiniBrowser are as follows:
It’s also worth mentioning that WEBKIT_SHOW_DAMAGE=1 environment variable disables damage-driven GTK/WPE WebKit’s compositor optimizations and therefore some glitches that are seen without the envvar, may not be seen
when it is set. The URL to this presentation is a great example to explore various glitches that are yet to be fixed. To trigger them, it’s enough to navigate
around the presentation using top/right/down/left arrows.
This article was meant to scratch the surface of the broad, damage propagation topic. While it focused mostly on introducing basic terminology and describing the damage propagation pipeline in more detail,
it briefly mentioned or skipped completely the following aspects of the feature:
the problem of storing the damage information efficiently,
the damage-driven optimizations of the GTK/WPE WebKit’s compositor,
the most common use cases for the feature,
the benchmark results on desktop-class and embedded devices.
Therefore, in the next articles, the above topics will be examined to a larger extent.
The new WPE platform API is still not released and thus it’s not yet officially announced. Some information on it, however, is provided by
this presentation prepared for a WebKit contributors meeting.
The platform that the WebKit renders to depends on the WebKit port:
in case of GTK port, the platform is GTK so the rendering is done to GtkWidget,
in case of WPE port with new WPE platform API, the platform is one of the following:
wayland — in that case rendering is done to the system’s compositor,
DRM — in that case rendering is done directly to the screen,
headless — in that case rendering is usually done into memory buffer.
WebKit has grown into a massive codebase throughout the years. To make developers’ lives easier, it offers various subsystems and integrations.
One such subsystem is a logging subsystem that offers the recording of textual logs describing an execution of the internal engine parts.
The logging subsystem in WebKit (as in any computer system), is usually used for both debugging and educational purposes. As WebKit is a widely-used piece of software that runs on
everything ranging from desktop-class devices up to low-end embedded devices, it’s not uncommon that logging is sometimes the only way for debugging when various limiting
factors come into play. Such limiting factors don’t have to be only technical - it may also be that the software runs on some restricted systems and direct debugging is not allowed.
Requirements for efficient work with textual logs #
Regardless of the reasons why logging is used, once the set of logs is produced, one can work with it according to the particular need.
From my experience, efficient work with textual logs requires a tool with the following capabilities:
Ability to search for a particular substring or regular expression.
Ability to filter text lines according to the substring or regular expressions.
Ability to highlight particular substrings.
Ability to mark certain lines for separate examination (with extra notes if possible).
Ability to save and restore the current state of work.
While all text editors should be able to provide requirement 1, requirements 2-5 are usually more tricky and text editors won’t support them out of the box.
Fortunately, any modern extensible text editor should be able to support requirements 2-5 after some extra configuration.
Throughout the following sections, I use Emacs, the classic “extensible, customizable, free/libre text editor”, to showcase how it can be set up and used to meet
the above criteria and to make work with logs a gentle experience.
Emacs, just like any other text editor, provides the support for requirement 1 from the previous section out of the box.
To support requirement 2, it requires some extra mode. My recommendation for that is loccur - the minor mode
that acts just like a classic grep *nix utility yet directly in the editor. The benefit of that mode (over e.g. occur)
is that it works in-place. Therefore it’s very ergonomic and - as I’ll show later - it works well in conjunction with bookmarking mode.
Installation of loccur is very simple and can be done from within the built-in package manager:
M-x package-install RET loccur RET
With loccur installed, one can immediately start using it by calling M-x loccur RET <regex> RET. The figure below depicts the example of filtering:
highlight-symbol - the package with utility functions for text highlighting #
To support requirement 3, Emacs also requires the installation of extra module. In that case my recommendation is highlight-symbol
that is a simple set of functions that enables basic text fragment highlighting on the fly.
Installation of this module is also very simple and boils down to:
M-x package-install RET highlight-symbol RET
With the above, it’s very easy to get results like in the figure below:
just by moving the cursor around and using C-c h to toggle the highlight of the text at the current cursor position.
bm - the package with utility functions for buffer lines bookmarking #
Finally, to support requirements 4 and 5, Emacs requires one last extra package. This time my recommendation is bm
that is quite a powerful set of utilities for text bookmarking.
In this case, installation is also very simple and is all about:
M-x package-install RET bm RET
In a nutshell, the bm package brings some visual capabilities like in the figure below:
as well as non-visual capabilities that will be discussed in further sections.
Once all the necessary modules are installed, it’s worth to spend some time on configuration. With just a few simple tweaks it’s possible to make the work with logs
simple and easily reproducible.
To not influence other workflows, I recommend attaching as much configuration as possible to any major mode and setting that mode as a default for
files with certain extensions. The configuration below uses a major mode called text-mode as the one for working with logs and associates all the files with a
suffix .log with it. Moreover, the most critical commands of the modes installed in the previous sections are binded to the key shortcuts. The one last
thing is to enable truncating the lines ((set-default 'truncate-lines t)) and highlighting the line that the cursor is currently at ((hl-line-mode 1)).
To show what the workflow of Emacs is with the above configuration and modules, some logs are required first. It’s very easy to
get some logs out of WebKit, so I’ll additionally get some GStreamer logs as well. For that, I’ll build a WebKit GTK port from the latest revision of WebKit repository.
To make the build process easier, I’ll use the WebKit container SDK.
The above command disables the ENABLE_JOURNALD_LOG build option so that logs are printed to stderr. This will result in the WebKit and GStreamer logs being bundled together as intended.
Once the build is ready, one can run any URL to get the logs. I’ve chosen a YouTube conformance tests suite from 2021 and selected test case “39. PlaybackRateChange”
to get some interesting entries from multimedia-related subsystems:
Once the logs are collected, one can open them using Emacs and start making sense out of them by gradually exploring the flow of execution. In the below exercise, I intend to understand
what happened from the multimedia perspective during the execution of the test case “39. PlaybackRateChange”.
The first step is usually to find the most critical lines that mark more/less the area in the file where the interesting things happen. In that case I propose using M-x loccur RET CONSOLE LOG RET to check what the
console logs printed by the application itself are. Once some lines are filtered, one can use bm-toggle command (C-c t) to mark some lines for later examination (highlighted as orange):
For practicing purposes I propose exiting the filtered view M-x loccur RET and trying again to see what events the browser was dispatching e.g. using M-x loccur RET on node node 0x7535d70700b0 VIDEO RET:
In general, the combination of loccur and substring/regexp searches should be very convenient to quickly explore various types of logs along with marking them for later. In case of very important log
lines, one can additionally use bm-bookmark-annotate command to add extra notes for later.
Once some interesting log lines are marked, the most basic thing to do is to jump between them using bm-previous (C-c n) and bm-next (C-c p). However, the true power of bm mode comes with
the use of M-x bm-show RET to get the view containing only the lines marked with bm-toggle (originally highlighted orange):
This view is especially useful as it shows only the lines deliberately marked using bm-toggle and allows one to quickly jump to them in the original file. Moreover, the lines are displayed in
the order they appear in the original file. Therefore it’s very easy to see the unified flow of the system and start making sense out of the data presented. What’s even more interesting,
the view contains also the line numbers from the original file as well as manually added annotations if any. The line numbers are especially useful as they may be used for resuming the work
after ending the Emacs session - which I’ll describe further in this section.
When the *bm-bookmarks* view is rendered, the only problem left is that the lines are hard to read as they are displayed using a single color. To overcome that problem one can use the macros from
the highlight-symbol package using the C-c h shortcut defined in the configuration. The result of highlighting some strings is depicted in the figure below:
With some colors added, it’s much easier to read the logs and focus on essential parts.
On some rare occasions it may happen that it’s necessary to close the Emacs session yet the work with certain log file is not done and needs to be resumed later. For that, the simple trick is to open the current
set of bookmarks with M-x bm-show RET and then save that buffer to the file. Personally, I just create a file with the same name as log file yet with .bm prefix - so for log.log it’s log.log.bm.
Once the session is resumed, it is enough to open both log.log and log.log.bm files side by side and create a simple ad-hoc macro to use line numbers from log.log.bm to mark them again in the log.log
file:
As shown in the above gif, within a few seconds all the marks are applied in the buffer with log.log file and the work can resume from that point i.e. one can jump around using bm, add new marks etc.
Although the above approach may not be ideal for everybody, I find it fairly ergonomic, smooth, and covering all the requirements I identified earlier.
I’m certain that editors other than Emacs can be set up to allow the same or very similar flow, yet any particular configurations are left for the reader to explore.
CSS Anchor Positioning is a novel CSS specification module
that allows positioned elements to size and position themselves relative to one or more anchor elements anywhere on the web page.
In simpler terms, it is a new web platform API that simplifies advanced relative-positioning scenarios such as tooltips, menus, popups, etc.
To better understand the true power it brings, let’s consider a non-trivial layout presented in Figure 1:
In the past, creating a context menu with position: fixed and positioned relative to the button required doing positioning-related calculations manually.
The more complex the layout, the more complex the situation. For example, if the table in the above example was in a scrollable container,
the position of the context menu would have to be updated manually on every scroll event.
With the CSS Anchor Positioning the solution to the above problem becomes trivial and requires 2 parts:
The <button> element must be marked as an anchor element by adding anchor-name: --some-name.
The context menu element must position itself using the anchor() function: left: anchor(--some-name right); top: anchor(--some-name bottom).
The above is enough for the web engine to understand that the context menu element’s left and top must be positioned to the anchor element’s right and bottom.
With that, the web engine can carry out the job under the hood, so the result is as in Figure 2:
As the above demonstrates, even with a few simple API pieces, it’s now possible to address very complex scenarios in a very elegant fashion from the web developer’s perspective.
Moreover, CSS Anchor Positioning offers even more than that. There are numerous articles with great examples such as
this MDN article,
this css-tricks article,
or this chrome blog post, but the long story short is that
both positioning and sizing elements relative to anchors are now very simple.
The first draft of the specification was published in early 2023,
which in the web engines field is not so long time ago.
Therefore - as one can imagine - not all the major web engines support it yet. The first (and so far the only) web engine
to support CSS Anchor Positioning was Chromium (see the introduction blog post) -
thus the information on caniuse.com.
However, despite the information visible on the WPT results page,
the other web engines are currently implementing it (see the meta bug for Gecko and
bug list
for WebKit). The lack of progress on the WPT results page is due to the feature not being enabled by default yet in those cases.
From the commits visible publicly, one can deduce that the work on CSS Anchor Positioning in WebKit has been started by Apple early 2024.
The implementation was initiated by adding a core part - support for anchor-name, position-anchor, and anchor(). Those 2 properties and function are enough to start using the feature
in real-world scenarios as well as more sophisticated WPT tests.
The work on the above had been finished by the end of Q3 2024, and then - in Q4 2024 - the work significantly intensified. A parsing/computing support has been added for numerous
properties and functions and moreover, a lot of new functionalities and bug fixes landed afterwards. One could expect some more things to land by the end of the year even if there’s
not much time left.
Overall, the implementation is in progress and is far from being done, but can already be tested in many real-world scenarios.
This can be done using custom WebKit builds (across various OSes) or using Safari Technology Preview on Mac.
The precondition for testing is, however, that the runtime preference called CSSAnchorPositioning is enabled.
Since the CSS Anchor Positioning in WebKit is still work in progress, and since the demand for the set of features this module brings is high, I’ve been privileged to contribute
a little to the implementation myself. My work so far has been focused around the parts of API that allow creating menu-like elements becoming visible on demand.
The first challenge with the above was to fix various problems related to toggling visibility status such as:
The obvious first step towards addressing the above was to isolate elegant scenarios to reproduce the above. In the process, I’ve created some test cases, and added them to WPT.
With tests in place, I’ve imported them into WebKit’s source tree and proceeded with actual bug fixing.
The result was the fix for the above crash, and the fix for the layout being broken.
With that in place, the visibility of menu-like elements can be changed without any problems now.
The second challenge was about the missing features allowing automatic alignment to the anchor. In a nutshell, to get the alignment like in the Figure 3:
there are 2 possibilities:
The position-area CSS property can be used: position-area: bottom center;.
At first, I wasn’t aware of the anchor-center and hence I’ve started initial work towards supporting position-area.
Once I became aware, however, I’ve switched my focus to implementing anchor-center and left the above for Apple to continue - not to block them.
Until now, both the initial and core parts of anchor-center implementation have landed.
It means, the basic support is in place.
Despite anchor-center layout tests passing, I’ve already discovered some problems such as:
and I anticipate more problems may appear once the testing intensifies.
To address the above, I’ll be focusing on adding extra WPT coverage along with fixing the problems one by one. The key is to
make sure that at the end of the day, all the unexpected problems are covered with WPT test cases. This way, other web engines
will also benefit.
With WebKit’s implementation of CSS Anchor Positioning in its current shape, the work can be very much parallel. Assuming that Apple will keep
working on that at the same pace as they did for the past few months, I wouldn’t be surprised if CSS Anchor Positioning would be pretty much
done by the end of 2025. If the implementation in Gecko doesn’t stall, I think one can also expect a lot of activity around testing in the
WPT. With that, the quality of implementation across the web engines should improve, and eventually (perhaps in 2026?) the CSS Anchor Positioning
should reach the state of full interoperability.
It’s been more than 2 years since the last time I wrote something here, and in that time a lot of things happened. Among those, one of the main highlights was me moving back to Igalia‘s WebKit team, but this time I moved as part of Igalia’s support infrastructure to help with other types of tasks such as general coordination, team facilitation and project management, among other things.
On top of those things, I’ve been also presenting our work around WebKit in different venues, such as in the Embedded Open Source Summit or in the Embedded Recipes conference, for instance. Of course, that included presenting our work in the WebKit community as part of the WebKit Contributors Meeting, a small and technically focused event that happens every year, normally around the Bay Area (California). That’s often a pretty dense presentation where, over the course of 30-40 minutes, we go through all the main areas that we at Igalia contribute to in WebKit, trying to summarize our main contributions in the previous 12 months. This includes work not just from the WebKit team, but also from other ones such as our Web Platform, Compilers or Multimedia teams.
This is a long read, so maybe grab a cup of your favorite beverage first…
Igalia and WebKit
So first of all, what is the relationship between Igalia and the WebKit project?
In a nutshell, we are the lead developers and the maintainers of the two Linux-based WebKit ports, known as WebKitGTK and WPE. These ports share a common baseline (e.g. GLib, GStreamer, libsoup) and also some goals (e.g. performance, security), but other than that their purpose is different, with WebKitGTK being aimed at the Linux desktop, while WPE is mainly focused on embedded devices.
This means that, while WebKitGTK is the go-to solution to embed Web content in GTK applications (e.g. GNOME Web/Epiphany, Evolution), and therefore integrates well with that graphical toolkit, WPE does not even provide a graphical toolkit since its main goal is to be able to run well on embedded devices that often don’t even have a lot of memory or processing power, or not even the usual mechanisms for I/O that we are used to in desktop computers. This is why WPE’s architecture is designed with flexibility in mind with a backends-based architecture, why it aims for using as few resources as possible, and why it tries to depend on as few libraries as possible, so you can integrate it virtually in any kind of embedded Linux platform.
Besides that port-specific work, which is what our WebKit and Multimedia teams focus a lot of their effort on, we also contribute at a different level in the port-agnostic parts of WebKit, mostly around the area of Web standards (e.g. contributing to Web specifications and to implement them) and the Javascript engine. This work is carried out by our Web Platform and Compilers team, which tirelessly contribute to the different parts of WebCore and JavaScriptCore that affect not just the WebKitGTK and WPE ports, but also the rest of them to a bigger or smaller degree.
Last but not least, we also devote a considerable amount of our time to other topics such as accessibility, performance, bug fixing, QA... and also to make sure WebKit works well on 32-bit devices, which is an important thing for a lot of WPE users out there.
Who are our users?
At Igalia we distinguish 4 main types of users of the WebKitGTK and WPE ports of WebKit:
Port users: this category would include anyone that writes a product directly against the port’s API, that is, apps such as a desktop Web browser or embedded systems that rely on a fullscreen Web view to render its Web-based content (e.g. digital signage systems).
Platform providers: in this category we would have developers that build frameworks with one of the Linux ports at its core, so that people relying on such frameworks can leverage the power of the Web without having to directly interface with the port’s API. RDK could be a good example of this use case, with WPE at the core of the so-called Thunder plugin (previously known as WPEFramework).
Web developers: of course, Web developers willing to develop and test their applications against our ports need to be considered here too, as they come with a different set of needs that need to be fulfilled, beyond rendering their Web content (e.g. using the Web Inspector).
End users: And finally, the end user is the last piece of the puzzle we need to pay attention to, as that’s what makes all this effort a task worth undertaking, even if most of them most likely don’t need what WebKit is, which is perfectly fine :-)
We like to make this distinction of 4 possible types of users explicit because we think it’s important to understand the complexity of the amount of use cases and the diversity of potential users and customers we need to provide service for, which is behind our decisions and the way we prioritize our work.
Strategic goals
Our main goal is that our product, the WebKit web engine, is useful for more and more people in different situations. Because of this, it is important that the platform is homogeneous and that it can be used reliably with all the engines available nowadays, and this is why compatibility and interoperability is a must, and why we work with the the standards bodies to help with the design and implementation of several Web specifications.
With WPE, it is very important to be able to run the engine in small embedded devices, and that requires good performance and being efficient in multiple hardware architectures, as well as great flexibility for specific hardware, which is why we provided WPE with a backend-based architecture, and reduced dependencies to a minimum.
Then, it is also important that the QA Infrastructure is good enough to keep the releases working and with good quality, which is why I regularly maintain, evolve and keep an eye on the EWS and post-commit bots that keep WebKitGTK and WPE building, running and passing the tens of thousands of tests that we need to check continuously, to ensure we don’t regress (or that we catch issues soon enough, when there’s a problem). Then of course it’s also important to keep doing security releases, making sure that we release stable versions with fixes to the different CVEs reported as soon as possible.
Finally, we also make sure that we keep evolving our tooling as much as possible (see for instance the release of the new SDK earlier this year), as well as improving the documentation for both ports.
Last, all this effort would not be possible if not because we also consider a goal of us to maintain an efficient collaboration with the rest of the WebKit community in different ways, from making sure we re-use and contribute to other ports as much code as possible, to making sure we communicate well in all the forums available (e.g. Slack, mailing list, annual meeting).
Contributions to WebKit in numbers
Well, first of all the usual disclaimer: number of commits is for sure not the best possible metric, and therefore should be taken with a grain of salt. However, the point here is not to focus too much on the actual numbers but on the more general conclusions that can be extracted from them, and from that point of view I believe it’s interesting to take a look at this data at least once a year.
With that out of the way, it’s interesting to confirm that once again we are still the 2nd biggest contributor to WebKit after Apple, with ~13% of the commits landed in this past 12-month period. More specifically, we landed 2027 patches out of the 15617 ones that took place during the past year, only surpassed by Apple and their 12456 commits. The remaining 1134 patches were landed mostly by Sony, followed by RedHat and several other contributors.
Now, if we remove Apple from the picture, we can observe how this year our contributions represented ~64% of all the non-Apple commits, a figure that grew about ~11% compared to the past year. This confirms once again our commitment to WebKit, a project we started contributing about 14 years ago already, and where we have been systematically being the 2nd top contributor for a while now.
Main areas of work
The 10 main areas we have contributed to in WebKit in the past 12 months are the following ones:
Web platform
Graphics
Multimedia
JavaScriptCore
New WPE API
WebKit on Android
Quality assurance
Security
Tooling
Documentation
In the next sections I’ll talk a bit about what we’ve done and what we’re planning to do next for each of them.
Web Platform
content-visibility:auto
This feature allows skipping painting and rendering of off-screen sections, particularly useful to avoid the browser spending time rendering parts in large pages, as content outside of the view doesn’t get rendered until it gets visible.
We completed the implementation and it’s now enabled by default.
Navigation API
This is a new API to manage browser navigation actions and examine history, which we started working on in the past cycle. There’s been a lot of work happening here and, while it’s not finished yet, the current plan is that Apple will continue working on that in the next months.
hasUAVisualTransition
This is an attribute of the NavigateEvent interface, which is meant to be True if the User Agent has performed a visual transition before a navigation event. It was something that we have also finished implementing and is now also enabled by default.
On top of that we also moved the X25519 feature to the “prepare to ship” stage.
Trusted Types
This work is related to reducing DOM-based XSS attacks. Here we finished the implementation and this is now pending to be enabled by default.
MathML
We continued working on the MathML specification by working on the support for padding, border and margin, as well as by increasing the WPT score by ~5%.
The plan for next year is to continue working on core features and improve the interaction with CSS.
Cross-root ARIA
Web components have accessibility-related issues with native Shadow DOM as you cannot reference elements with ARIA attributes across boundaries. We haven’t worked on this in this period, but the plan is to work in the next months on implementing the Reference Target proposal to solve those issues.
Canvas Formatted Text
Canvas has not a solution to add formatted and multi-line text, so we would like to also work on exploring and prototyping the Canvas Place Element proposal in WebKit, which allows better text in canvas and more extended features.
Graphics
Completed migration from Cairo to Skia for the Linux ports
The results in the end were pretty overwhelming and we decided to give Skia a go, and we are happy to say that, as of today, the migration has been completed: we covered all the use cases in Cairo, achieving feature parity, and we are now working on implementing new features and improvements built on top of Skia (e.g. GPU-based 2D rendering).
On top of that, Skia is now the default backend for WebKitGTK and WPE since 2.46.0, released on September 17th, so if you’re building a recent version of those ports you’ll be already using Skia as their 2D rendering backend. Note that Skia is using its GPU-based backend only on desktop environments, on embedded devices the situation is trickier and for now the default is the CPU-based Skia backend, but we are actively working to narrow the gap and to enable GPU-based rendering also on embedded.
Architecture changes with buffer sharing APIs (DMABuf)
We did a lot of work here, such as a big refactoring of the fencing system to control the access to the buffers, or the continued work towards integrating with Apple’s DisplayLink infrastructure.
On top of that, we also enabled more efficient composition using damaging information, so that we don’t need to pass that much information to the compositor, which would slow the CPU down.
Enablement of the GPUProcess
On this front, we enabled by default the compilation for WebGL rendering using the GPU process, and we are currently working in performance review and enabling it for other types of rendering.
New SVG engine (LBSE: Layer-Based SVG Engine)
If you are not familiar with this, here the idea is to make sure that we reuse the graphics pipeline used for HTML and CSS rendering, and use it also for SVG, instead of having its own pipeline. This means, among other things, that SVG layers will be supported as a 1st-class citizen in the engine, enabling HW-accelerated animations, as well as support for 3D transformations for individual SVG elements.
On this front, on this cycle we added support for the missing features in the LBSE, namely:
Implemented support for gradients & patterns (applicable to both fill and stroke)
Implemented support for clipping & masking (for all shapes/text)
Implemented support for markers
Helped review implementation of SVG filters (done by Apple)
Besides all this, we also improved the performance of the new layer-based engine by reducing repaints and re-layouts as much as possible (further optimizations still possible), narrowing the performance gap with the current engine for MotionMark. While we are still not at the same level of performance as the current SVG engine, we are confident that there are several key places where, with the right funding, we should be able to improve the performance to at least match the current engine, and therefore be able to push the new engine through the finish line.
General overhaul of the graphics pipeline, touching different areas (WIP):
On top of everything else commented above, we also worked on a general refactor and simplification of the graphics pipeline. For instance, we have been working on the removal of the Nicosia layer now that we are not planning to have multiple rendering implementations, among other things.
Multimedia
DMABuf-based sink for HW-accelerated video
We merged the DMABuf-based sink for HW-accelerated video in the GL-based GStreamer sink.
WebCodecs backend
We completed the implementation of audio/video encoding and decoding, and this is now enabled by default in 2.46. As for the next steps, we plan to keep working on the integration of WebCodecs with WebGL and WebAudio.
GStreamer-based WebRTC backends
We continued working on GstWebRTC, bringing it to a point where it can be used in production in some specific use cases, and we will still be working on this in the next months.
Other
Besides the points above, we also added an optional text-to-speech backend based on libspiel to the development branch, and worked on general maintenance around the support for Media Source Extensions (MSE) and Encrypted Media Extensions (EME), which are crucial for the use case of WPE running in set-top-boxes, and is a permanent task we will continue to work on in the next months.
JavaScriptCore
ARMv7/32-bit support:
A lot of work happened around 32-bit support in JavaScriptCore, especially around WebAssembly (WASM): we ported the WASM BBQJIT and ported/enabled concurrent JIT support, and we also completed 80% of the implementation for the OMG optimization level of WASM, which we plan to finish in the next months. If you are unfamiliar with what the OMG and BBQ optimization tiers in WASM are, I’d recommend you to take a look at this article in webkit.org: “Assembling WebAssembly“.
We also contributed to the JIT-less WASM, which is very useful for embedded systems that can’t support JIT for security or memory related constraints, and also did some work on the In-Place Interpreter (IPInt), which is a new version of the WASM Low-level interpreter (LLInt) that uses less memory and executes WASM bytecode directly without translating it to LLInt bytecode (and should therefore be faster to execute).
Last, we also contributed most of the implementation for the WASM GC, with the exception of some Kotlin tests.
As for the next few months, we plan to investigate and optimize heap/JIT memory usage in 32-bit, as well as to finish several other improvements on ARMv7 (e.g. IPInt).
New WPE API
The new WPE API is a new API that aims at making it easier to use WPE in embedded devices, by removing the hassle of having to handle several libraries in tandem (i.e. WPEWebKit, libWPE and WPEBackend-FDO, for instance), available from WPE’s releases page, and providing a more modern API in general, better aimed at the most common use cases of WPE.
A lot of effort happened this year along these lines, including the fact that we finally upstreamed and shipped its initial implementation with WPE 2.44, back in the first half of the year. Now, while we recommend users to give it a try and report feedback as much as possible, this new API is still not set in stone, with regular development still ongoing, so if you have the chance to try it out and share your experience, comments are welcome!
Besides shipping its initial implementation, we also added support for external platforms, so that other ones can be loaded beyond the Wayland, DRM and “headless” ones, which are the default platforms already included with WPE itself. This means for instance that a GTK4 platform, or another one for RDK could be easily used with WPE.
Then of course a lot of API additions were included in the new API in the latest months:
Screens management API: API to handle different screens, ask the display for the list of screens with their device scale factor, refresh rate, geometry…
Top level management API: This API allows a greater degree of control, for instance by allowing more than one WebView for the same top level, as well as allowing to retrieve properties such as size, scale or state (i.e. full screen, maximized…).
Maximized and minimized windows API: API to maximize/minimize a top level and monitor its state. mainly used by WebDriver.
Preferred DMA-BUF formats API: enables asking the platform (compositor or DRM) for the list of preferred formats and their intended use (scanout/rendering).
Input methods API: allows platforms to provide an implementation to handle input events (e.g. virtual keyboard, autocompletion, auto correction…).
Gestures API: API to handle gestures (e.g. tap, drag).
Buffer damaging: WebKit generates information about the areas of the buffer that actually changed and we pass that to DRM or the compositor to optimize painting.
Pointer lock API: allows the WebView to lock the pointer so that the movement of the pointing device (e.g. mouse) can be used for a different purpose (e.g. first-person shooters).
Last, we also added support for testing automation, and we can support WebDriver now in the new API.
With all this done so far, the plan now is to complete the new WPE API, with a focus on the Settings API and accessibility support, write API tests and documentation, and then also add an external platform to support GTK4. This is done on a best-effort basis, so there’s no specific release date.
WebKit on Android
This year was also a good year for WebKit on Android, also known as WPE Android, as this is a project that sits on top of WPE and its public API (instead of developing a fully-fledged WebKit port).
In case you’re not familiar with this, the idea here is to provide a WebKit-based alternative to the Chromium-based Web view on Android devices, in a way that leverages HW acceleration when possible and that it integrates natively (and nicely) with the several Android subsystems, and of course with Android’s native mainloop. Note that this is an experimental project for now, so don’t expect production-ready quality quite yet, but hopefully something that can be used to start experimenting with selected use cases.
Anyway, as for the changes that happened in the past 12 months, here is a summary:
Updated WPE Android to WPE 2.46 and NDK 27 LTS
Added support for WebDriver and included WPT test suites
Added support for instrumentation tests, and integrated with the GitHub CI
Added support for the remote Web inspector, very useful for debugging
Enabled the Skia backend, bringing HW-accelerated 2D rendering to WebKit on Android
Implemented prompt delegates, allowing implementing things such as alert dialogs
Implemented WPEView client interfaces, allowing responding to things such as HTTP errors
Packaged a WPE-based Android WebView in its own library and published in Maven Central. This is a massive improvement as now apps can use WPE Android by simply referencing the library from the gradle files, no need to build everything on their own.
Other changes: enabled HTTP/2 support (via the migration to libsoup3), added support for the device scale factor, improved the virtual on-screen keyboard, general bug fixing…
On top of that, we published 3 different blog posts covering different topics, from a general intro to a more deep dive explanation of the internals, and showing some demos. You can check them out in Jani’s blog at https://blogs.igalia.com/jani
As for the future, we’ll focus on stabilization and regular maintenance for now, and then we’d like to work towards achieving production-ready quality for specific cases if possible.
Quality Assurance
On the QA front, we had a busy year but in general we could highlight the following topics.
Fixed a lot of API tests failures in the bots that were limiting our test coverage.
Fixed lots of assertions-related crashes in the bots, which were slowing down the bots as well as causing other types of issues, such as bots exiting early due too many failures.
Enabled assertions in the release bots, which will help prevent crashes in the future, as well as with making our debug bots healthier.
Moved all the WebKitGTK and WPE bots to building now with Skia instead of Cairo. This means that all the bots running tests are now using Skia, and there’s only one bot still using Cairo to make sure that the compilation is not broken, but that bot does not run tests.
Moved all the WebKitGTK bots to use GTK4 by default. As with the move to Skia, all the WebKit bots running tests now use GTK4 and the only one remaining building with GTK3 does not run tests, it only makes sure we don’t break the GTK3 compilation for now.
Working on moving all the bots to use the new SDK. This is still work in progress and will likely be completed during 2025 as it’s needed to implement several changes in the infrastructure that will take some time.
General gardening and bot maintenance
In the next months, our main focus would be a revamp of the QA infrastructure to make sure that we can get all the bots (including the debug ones) to a healthier state, finish the migration of all the bots to the new SDK and, ideally, be able to bring back the ready-to-use WPE images that we used to have available in wpewebkit.org.
Security
The current release cadence has been working well, so we continue issuing major releases every 6 months (March, September), and then minor and unstable development releases happening on-demand when needed.
Last, we also shortened the time before including security fixes in stable releases this year, and we have removed support for libsoup2 from WPE, as that library is no longer maintained.
Tooling & Documentation
On tooling, the main piece of news is that this year we released the initial version of the new SDK, which is developed on top of OCI-based containers. This new SDK fixes the issues with the current existing approaches based on JHBuild and flatpak, where one of them was great for development but poor for testing and QA, and the other one was great for testing and QA, but not very convenient for development.
As for documentation, we didn’t do as much as we would have liked here, but we still landed a few contributions in docs.webkit.org, mostly related to WebKitGTK (e.g. Releases and Versioning, Security Updates, Multimedia). We plan to do more on this regard in the next months, though, mostly by writing/publishing more documentation and perhaps also some tutorials.
Final thoughts
This has been a fairly long blog post but, as you can see, it’s been quite a year for WebKit here at Igalia, with many exciting changes happening at several fronts, and so there was quite a lot of stuff to comment on here. This said, you can always check the slides of the presentation in the WebKit Contributors Meeting here if you prefer a more concise version of the same content.
In any case, what’s clear it’s that the next months are probably going to be quite interesting as well with all the work that’s already going on in WebKit and its Linux ports, so it’s possible that in 12 months from now I might be writing an equally long essay. We’ll see.
The <video> element implementation in WebKit does its job by using a multiplatform player that relies on a platform-specific implementation. In the specific case of glib platforms, which base their multimedia on GStreamer, that’s MediaPlayerPrivateGStreamer.
The player private can have 3 buffering modes:
On-disk buffering: This is the typical mode on desktop systems, but is frequently disabled on purpose on embedded devices to avoid wearing out their flash storage memories. All the video content is downloaded to disk, and the buffering percentage refers to the total size of the video. A GstDownloader element is present in the pipeline in this case. Buffering level monitoring is done by polling the pipeline every second, using the fillTimerFired() method.
In-memory buffering: This is the typical mode on embedded systems and on desktop systems in case of streamed (live) content. The video is downloaded progressively and only the part of it ahead of the current playback time is buffered. A GstQueue2 element is present in the pipeline in this case. Buffering level monitoring is done by listening to GST_MESSAGE_BUFFERING bus messages and using the buffering level stored on them. This is the case that motivates the refactoring described in this blog post, what we actually wanted to correct in Broadcom platforms, and what motivated the addition of hysteresis working on all the platforms.
Local files: Files, MediaStream sources and other special origins of video don’t do buffering at all (no GstDownloadBuffering nor GstQueue2 element is present on the pipeline). They work like the on-disk buffering mode in the sense that fillTimerFired() is used, but the reported level is relative, much like in the streaming case. In the initial version of the refactoring I was unaware of this third case, and only realized about it when tests triggered the assert that I added to ensure that the on-disk buffering method was working in GST_BUFFERING_DOWNLOAD mode.
The current implementation (actually, its wpe-2.38 version) was showing some buffering problems on some Broadcom platforms when doing in-memory buffering. The buffering levels monitored by MediaPlayerPrivateGStreamer weren’t accurate because the Nexus multimedia subsystem used on Broadcom platforms was doing its own internal buffering. Data wasn’t being accumulated in the GstQueue2 element of playbin, because BrcmAudFilter/BrcmVidFilter was accepting all the buffers that the queue could provide. Because of that, the player private buffering logic was erratic, leading to many transitions between “buffer completely empty” and “buffer completely full”. This, it turn, caused many transitions between the HaveEnoughData, HaveFutureData and HaveCurrentData readyStates in the player, leading to frequent pauses and unpauses on Broadcom platforms.
So, one of the first thing I tried to solve this issue was to ask the Nexus PlayPump (the subsystem in charge of internal buffering in Nexus) about its internal levels, and add that to the levels reported by GstQueue2. There’s also a GstMultiqueue in the pipeline that can hold a significant amount of buffers, so I also asked it for its level. Still, the buffering level unstability was too high, so I added a moving average implementation to try to smooth it.
All these tweaks only make sense on Broadcom platforms, so they were guarded by ifdefs in a first version of the patch. Later, I migrated those dirty ifdefs to the new quirks abstraction added by Phil. A challenge of this migration was that I needed to store some attributes that were considered part of MediaPlayerPrivateGStreamer before. They still had to be somehow linked to the player private but only accessible by the platform specific code of the quirks. A special HashMap attribute stores those quirks attributes in an opaque way, so that only the specific quirk they belong to knows how to interpret them (using downcasting). I tried to use move semantics when storing the data, but was bitten by object slicing when trying to move instances of the superclass. In the end, moving the responsibility of creating the unique_ptr that stored the concrete subclass to the caller did the trick.
Even with all those changes, undesirable swings in the buffering level kept happening, and when doing a careful analysis of the causes I noticed that the monitoring of the buffering level was being done from different places (in different moments) and sometimes the level was regarded as “enough” and the moment right after, as “insufficient”. This was because the buffering level threshold was one single value. That’s something that a hysteresis mechanism (with low and high watermarks) can solve. So, a logical level change to “full” would only happen when the level goes above the high watermark, and a logical level change to “low” when it goes under the low watermark level.
For the threshold change detection to work, we need to know the previous buffering level. There’s a problem, though: the current code checked the levels from several scattered places, so only one of those places (the first one that detected the threshold crossing at a given moment) would properly react. The other places would miss the detection and operate improperly, because the “previous buffering level value” had been overwritten with the new one when the evaluation had been done before. To solve this, I centralized the detection in a single place “per cycle” (in updateBufferingStatus()), and then used the detection conclusions from updateStates().
So, with all this in mind, I refactored the buffering logic as https://commits.webkit.org/284072@main, so now WebKit GStreamer has a buffering code much more robust than before. The unstabilities observed in Broadcom devices were gone and I could, at last, close Issue 1309.
WebKitGTK and WPEWebKit recently released a new stable version 2.46. This version includes important changes in the graphics implementation.
Skia
The most important change in 2.46 is the introduction of Skia to replace Cairo as the 2D graphics renderer. Skia supports rendering using the GPU, which is now the default, but we also use it for CPU rendering using the same threaded rendering model we had with Cairo. The architecture hasn’t changed much for GPU rendering: we use the same tiled rendering approach, but buffers for dirty regions are rendered in the main thread as textures. The compositor waits for textures to be ready using fences and copies them directly to the compositor texture. This was the simplest approach that already resulted in much better performance, specially in the desktop with more powerful GPUs. In embedded systems, where GPUs are not so powerful, it’s still better to use the CPU with several rendering threads in most of the cases. It’s still too early to announce anything, but we are already experimenting with different models to improve the performance even more and make a better usage of the GPU in embedded devices.
Skia has received several GCC specific optimizations lately, but it’s always more optimized when built with clang. The optimizations are more noticeable in performance when using the CPU for rendering. For this reason, since version 2.46 we recommend to build WebKit with clang for the best performance. GCC is still supported, of course, and performance when built with GCC is quite good too.
HiDPI
Even though there aren’t specific changes about HiDPI in 2.46, users of high resolution screens using a device scale factor bigger than 1 will notice much better performance thanks to scaling being a lot faster on the GPU.
Accelerated canvas
The 2D canvas can be accelerated independently on whether the CPU or the GPU is used for painting layers. In 2.46 there’s a new setting WebKitSettings:enable-2d-canvas-acceleration to control the 2D canvas acceleration. In some embedded devices the combination of CPU rendering for layer tiles and GPU for the canvas gives the best performance. The 2D canvas is normally rendered into an image buffer that is then painted in the layer as an image. We changed that for the accelerated case, so that the canvas is now rendered into a texture that is copied to a compositor texture to be directly composited instead of painted into the layer as an image. In 2.46 the offscreen canvas is enabled by default.
There are more cases where accelerating the canvas is not desired, for example when the canvas size is not big enough it’s faster to use the GPU. Also when there’s going to be many operations to “download” pixels from GPU. Since this is not always easy to predict, in 2.46 we added support for the willReadFrequently canvas setting, so that when set by the application when creating the canvas it causes the canvas to be always unaccelerated.
Filters
All the CSS filters are now implemented using Skia APIs, and accelerated when possible. The most noticeable change here is that sites using blur filters are no longer slow.
Color spaces
Skia brings native support for color spaces, which allows us to greatly simplify the color space handling code in WebKit. WebKit uses color spaces in many scenarios – but especially in case of SVG and filters. In case of some filters, color spaces are necessary as some operations are simpler to perform in linear sRGB. The good example of that is feDiffuseLighting filter – it yielded wrong visual results for a very long time in case of Cairo-based implementation as Cairo doesn’t have a support for color spaces. At some point, however, Cairo-based WebKit implementation has been fixed by converting pixels to linear in-place before applying the filter and converting pixels in-place back to sRGB afterwards. Such a workarounds are not necessary anymore as with Skia, all the pixel-level operations are handled in a color-space-transparent way as long as proper color space information is provided. This not only impacts the results of some filters that are now correct, but improves performance and opens new possibilities for acceleration.
Font rendering
Font rendering is probably the most noticeable visual change after the Skia switch with mixed feedback. Some people reported that several sites look much better, while others reported problems with kerning in other sites. In other cases it’s not really better or worse, it’s just that we were used to the way fonts were rendered before.
Damage tracking
WebKit already tracks the area of the layers that has changed to paint only the dirty regions. This means that we only repaint the areas that changed but the compositor incorporates them and the whole frame is always composited and passed to the system compositor. In 2.46 there’s experimental code to track the damage regions and pass them to the system compositor in addition to the frame. Since this is experimental it’s disabled by default, but can be enabled with the runtime feature PropagateDamagingInformation. There’s also UnifyDamagedRegions feature that can be used in combination with PropagateDamagingInformation to unify the damage regions into one before passing it to the system compositor. We still need to analyze the impact of damage tracking in performance before enabling it by default. We have also started an experiment to use the damage information in WebKit compositor and avoid compositing the entire frame every time.
GPU info
Working on graphics can be really hard in Linux, there are too many variables that can result in different outputs for different users: the driver version, the kernel version, the system compositor, the EGL extensions available, etc. When something doesn’t work for some people and work for others, it’s key for us to gather as much information as possible about the graphics stack. In 2.46 we have added more useful information to webkit://gpu, like the DMA-BUF buffer format and modifier used (for GTK port and WPE when using the new API). Very often the symptom is the same, nothing is rendered in the web view, even when the causes could be very different. For those cases, it’s even more difficult to gather the info because webkit://gpu doesn’t render anything either. In 2.46 it’s possible to load webkit://gpu/stdout to get the information as a JSON directly in stdout.
Sysprof
Another common symptom for people having problems is that a particular website is slow to render, while for others it works fine. In these cases, in addition to the graphics stack information, we need to figure out where we are slower and why. This is very difficult to fix when you can’t reproduce the problem. We added initial support for profiling in 2.46 using sysprof. The code already has some marks so that when run under sysprof we get useful information about timings of several parts of the graphics pipeline.
Next
This is just the beginning, we are already working on changes that will allow us to make a better use of both the GPU and CPU for the best performance. We have also plans to do other changes in the graphics architecture to improve synchronization, latency and security. Now that we have adopted sysprof for profiling, we are also working on improvements and new tools.
Move semantics can be very useful to transfer ownership of resources, but as many other C++ features, it’s one more double edge sword that can harm yourself in new and interesting ways if you don’t read the small print.
For instance, if object moving involves super and subclasses, you have to keep an extra eye on what’s actually happening. Consider the following classes A and B, where the latter inherits from the former:
#include <stdio.h>
#include <utility>
#define PF printf("%s %p\n", __PRETTY_FUNCTION__, this)
class A {
public:
A() { PF; }
virtual ~A() { PF; }
A(A&& other)
{
PF;
std::swap(i, other.i);
}
int i = 0;
};
class B : public A {
public:
B() { PF; }
virtual ~B() { PF; }
B(B&& other)
{
PF;
std::swap(i, other.i);
std::swap(j, other.j);
}
int j = 0;
};
If your project is complex, it would be natural that your code involves abstractions, with part of the responsibility held by the superclass, and some other part by the subclass. Consider also that some of that code in the superclass involves move semantics, so a subclass object must be moved to become a superclass object, then perform some action, and then moved back to become the subclass again. That’s a really bad idea!
Consider this usage of the classes defined before:
int main(int, char* argv[]) {
printf("Creating B b1\n");
B b1;
b1.i = 1;
b1.j = 2;
printf("b1.i = %d\n", b1.i);
printf("b1.j = %d\n", b1.j);
printf("Moving (B)b1 to (A)a. Which move constructor will be used?\n");
A a(std::move(b1));
printf("a.i = %d\n", a.i);
// This may be reading memory beyond the object boundaries, which may not be
// obvious if you think that (A)a is sort of a (B)b1 in disguise, but it's not!
printf("(B)a.j = %d\n", reinterpret_cast<B&>(a).j);
printf("Moving (A)a to (B)b2. Which move constructor will be used?\n");
B b2(reinterpret_cast<B&&>(std::move(a)));
printf("b2.i = %d\n", b2.i);
printf("b2.j = %d\n", b2.j);
printf("^^^ Oops!! Somebody forgot to copy the j field when creating (A)a. Oh, wait... (A)a never had a j field in the first place\n");
printf("Destroying b2, a, b1\n");
return 0;
}
If you’ve read the code, those printfs will have already given you some hints about the harsh truth: if you move a subclass object to become a superclass object, you’re losing all the subclass specific data, because no matter if the original instance was one from a subclass, only the superclass move constructor will be used. And that’s bad, very bad. This problem is called object slicing. It’s specific to C++ and can also happen with copy constructors. See it with your own eyes:
Creating B b1
A::A() 0x7ffd544ca690
B::B() 0x7ffd544ca690
b1.i = 1
b1.j = 2
Moving (B)b1 to (A)a. Which move constructor will be used?
A::A(A&&) 0x7ffd544ca6a0
a.i = 1
(B)a.j = 0
Moving (A)a to (B)b2. Which move constructor will be used?
A::A() 0x7ffd544ca6b0
B::B(B&&) 0x7ffd544ca6b0
b2.i = 1
b2.j = 0
^^^ Oops!! Somebody forgot to copy the j field when creating (A)a. Oh, wait... (A)a never had a j field in the first place
Destroying b2, a, b1
virtual B::~B() 0x7ffd544ca6b0
virtual A::~A() 0x7ffd544ca6b0
virtual A::~A() 0x7ffd544ca6a0
virtual B::~B() 0x7ffd544ca690
virtual A::~A() 0x7ffd544ca690
Why can something that seems so obvious become such a problem, you may ask? Well, it depends on the context. It’s not unusual for the codebase of a long lived project to have started using raw pointers for everything, then switching to using references as a way to get rid of null pointer issues when possible, and finally switch to whole objects and copy/move semantics to get rid or pointer issues (references are just pointers in disguise after all, and there are ways to produce null and dangling references by mistake). But this last step of moving from references to copy/move semantics on whole objects comes with the small object slicing nuance explained in this post, and when the size and all the different things to have into account about the project steals your focus, it’s easy to forget about this.
So, please remember: never use move semantics that convert your precious subclass instance to a superclass instance thinking that the subclass data will survive. You can regret about it and create difficult to debug problems inadvertedly.
We all think we’re smart enough to not be tricked by a phishing attempt, right? Unfortunately, I know for certain that I’m not, because I entered my GitHub password into a lookalike phishing website a year or two ago. Oops! Fortunately, I noticed right away, so I simply changed my unique, never-reused password and moved on. But if the attacker were smarter, I might have never noticed. (This particular attack website was relatively unsophisticated and proxied only an unauthenticated view of GitHub, a big clue that something was wrong. Update: I want to be clear that it would have been very easy for the attacker to simply redirect me to the real github.com after stealing my credentials, in which case I would not have noticed the attack and would not have known to change my password.)
You might think multifactor authentication is the best defense against phishing. Nope. Although multifactor authentication is a major security improvement over passwords alone, and the particular attack that tricked me did not attempt to subvert multifactor authentication, it’s actually unfortunately pretty easy for phishers to defeat most multifactor authentication if they wish to do so:
Multifactor authentication based on phone calls is also insecure (because SIM swapping isn’t going away; determined attackers will steal your phone number if it’s an obstacle to them)
Multifactor authentication based on authenticator apps (using TOTP or HOTP) is much better in general, but still fails against phishing. When you paste your one-time access code into a phishing website, the phishing website can simply “proxy” the access code you kindly provided to them by submitting it to the real website. This only allows authenticating once, but once is usually enough.
Fortunately, there is a solution: passkeys. Based on FIDO2 and WebAuthn, passkeys resist phishing because the authentication process depends on the domain of the service that you’re actually connecting to. If you think you’re visiting https://example.com, but you’re actually visiting a copycat website with a Cyrillic а instead of Latin a, then no worries: the authentication will fail, and the frustrated attacker will have achieved nothing.
The most popular form of passkey is local biometric authentication running on your phone, but any hardware security key (e.g. YubiKey) is also a good bet.
target.com Is More Secure than Your Bank!
I am not joking when I say that target.com is more secure than your bank (which is probably still relying on SMS or phone calls, and maybe even allows you to authenticate using easily-guessable security questions):
target.com is introducing passkeys!
Good job for supporting passkeys, Target.
It’s probably perfectly fine for Target to support passkeys alongside passwords indefinitely. Higher-security websites that want to resist phishing (e.g. your employer’s SSO service) should consider eventually allowing only passkeys.
No Passkeys in WebKitGTK
Unfortunately for GNOME users, WebKitGTK does not yet support WebAuthn, so passkeys will not work in GNOME Web (Epiphany). That’s my browser of choice, so I’ve never touched a passkey before and don’t actually know how well they work in practice. Maybe do as I say and not as I do? If you require high security, you will unfortunately need to use Firefox or Chrome instead, at least for the time being.
Why Was Michael Visiting a Fake github.com?
The fake github.com appeared higher than the real github.com in the DuckDuckGo search results for whatever I was looking for at the time. :(
In recent months I’ve been privileged to work on the transition from Cairo to Skia for 2D graphics rendering in WPE and GTK WebKit ports. Big
reworks like this are a great opportunity to explore all kinds of graphics-related APIs. One of the broader APIs in this area is the CanvasRenderingContext2D API from HTML
Canvas. It’s a fairly straightforward yet extensive API allowing one to perform all kinds of drawing operations on the canvas. The comprehensiveness, however, comes at the expense of
some complex situations the web engine needs to handle under the hood. One such situation was the issue I was working on recently regarding broken test cases
involving drawing shadows when using Skia in WebKit. What makes it complex is that some problems are still visible due to multiple web engine layers being involved, but despite that I was eventually able to address the
broken test cases.
In the next few sections I’m going to introduce the parts of the API that are involved in the problems while in the sections closer to the end I will gradually showcase the problems and explore potential paths toward fixing the entire situation.
Drawing on Canvas2D with globalCompositeOperation#
The Canvas2D API offers multiple methods for drawing various primitives such as rectangles, arcs, text etc. On top of that, it allows one to control compositing and clipping
using the globalCompositeOperation property. The idea is very simple - the user of an API can change the property using one of the predefined
compositing operations and immediately after that, all new drawing operations will behave according to the rules the particular compositing operation specifies:
canvas2DContext.fillRect(...);// Draws rect on top of existing content (default). canvas2DContext.globalCompositeOperation ='destination-atop'; canvas2DContext.fillRect(...);// Draws rect according to 'destination-atop'.
There are many compositing operations, but I’ll be focusing mostly on the ones having source and destination in their names.
The source and destination terms refer to the new content to be drawn and the existing (already-drawn) content respectively.
The images below present some examples of compositing operations in action:
When drawing primitives using the Canvas2D API one can use shadow* properties
to enable drawing of shadows along with any content that is being drawn. The usage is very simple - one has to alter at least one property such as e.g. shadowOffsetX to make the shadow visible:
canvas2DContext.shadowColor ="#0f0"; canvas2DContext.shadowOffsetX =10; // From now on, any draw call will have a green shadow attached.
the above combined with simple code to draw a circle produces a following effect:
Things are getting interesting once one starts thinking about how globalCompositeOperation may affect the way shadows are drawn. When I thought about it for the first time, I imagined at least 3 possibilities:
Shadow and shadow origin are both treated as one entity (shadow always below the origin) and thus are drawn together.
Shadow and shadow origin are combined and then drawn as a one entity.
Shadow and shadow origin are drawn separately - shadow first, then the content.
When I confronted the above with the drawing model and shadows specification,
it turned out the last guess was the correct one. The specification basically says that the shadow should be computed first, then composited within the clipping region over the current canvas content, and finally, the shadow origin should be composited
within the clipping region over the current canvas content (the original canvas content combined with shadow).
The above can be confirmed visually using few examples (generated using chromium browser v126.0.6478.126):
The source-over operation shows the drawing order - destination first, shadow second, and shadow origin third.
The destination-over operation shows the reversed drawing order - destination first, shadow second (below destination), and shadow origin third (below destination and shadow).
The source-atop operation is more tricky as it behaves like source-over but with clipping to the destination content - therefore, destination is drawn first, then clipping is set to destination, then the shadow is drawn,
and finally the shadow origin is drawn.
The destination-atop operation is even more tricky as it behaves like destination-over yet with the clipping region always being different. That difference can be seen on the image below that presents intermediate states of canvas
after each drawing step:
The initial state shows a canvas after drawing the destination on it.
The after drawing shadow state, shows a shadow drawn below the destination. In this case, the clipping is set to new content (shadow), and hence the part of destination that is not “atop” shadow is being clipped out.
The after drawing shadow origin state, shows the final state after drawing the shadow origin below the previous canvas content (new destination) that is at this point “a shadow combined with destination”. Similarly as in the previous step,
the clipping is set to the new content (shadow origin), and hence any part of new destination that is not “atop” the shadow origin is being clipped out.
Whenever one realizes the drawing of shadows with globalCompositeOperation in general may be tricky, then one must also consider that when it comes to particular browser engines, the things are even more tricky as virtually no graphics library
provides an API that matches the Canvas2D API 1-to-1. This means that depending on the graphics library used, the browser engine must implement more or less integration parts
here and there. For example, one can imagine that some graphics library may not have native support for shadows - that would mean the browser engine has to prepare shadows itself by e.g. drawing shadow origin (no matter how complex) on extra
surface, changing color, blurring etc. so that it can be used as a whole once prepared.
Having said the above, one would expect that all the above aspects should be tested and implemented really well. After all, whenever the subject matter becomes complicated, extra care is required. It turns out, however, this is not necessarily the
case when it comes to globalCompositeOperation and shadows. As for the testing part, there are very few tests
(2d.shadow.composite*) in WPT (Web Platform Tests) covering the use cases described above. It’s also not much better for internal web engine test suites. As for implementations, there’s a substantial amount of
discrepancy.
To show exactly what’s the situation, the examples from section Shadows meet globalCompositeOperation
can be used again. This time using browsers representing different web engines:
Chromium 126.0.6478.126
Firefox 128.0
Gnome Web (Epiphany) 45.0 (WebKit/Cairo)
WPE MiniBrowser build from WebKit@098c58dd13bf40fc81971361162e21d05cb1f74a (WebKit/Skia)
Safari 17.1 (WebKit/Core Graphics)
Servo release from 2024/07/04
Ladybird build from 2024/06/29
First of all, it’s evident that experimental browsers such as servo and ladybird are falling behind the competition - servo doesn’t seem to support shadows at all, while ladybird doesn’t support anything other than drawing a rect filled with color.
Second, the non-experimental browsers are pretty stable in terms of covering most of the combinations presented above.
Finally, the most tricky combination above seems to be the one including destination-atop - in that case almost every mainstream browser renders different results:
Chromium is the only one rendering correctly.
Firefox and Epiphany are pretty close, but both are suffering from a similar glitch where the red part is covered by the part of destination that should be clipped out already.
WPE MiniBrowser and Safari are both rendering in correct order, but the clipping is wrong.
Until now, the discrepancies don’t seem to be very dramatic, and hence it’s time to present more sophisticated examples that are an extended
version of the test case from the WebKit source tree:
Chromium 126.0.6478.126
Firefox 128.0
Gnome Web (Epiphany) 45.0 (WebKit/Cairo)
WPE MiniBrowser build from WebKit@098c58dd13bf40fc81971361162e21d05cb1f74a (WebKit/Skia)
Safari 17.1 (WebKit/Core Graphics)
Servo release from 2024/07/04
Ladybird build from 2024/06/29
Other than destination-out, xor, and a few simple operations presented before, all the operations presented above pose serious problems to the majority of browsers. The only browser that is correct in all the cases
(to the best of my understanding) is Chromium that is using rendering engine called blink which in turn uses the Skia library. One may wonder if perhaps it’s Skia that’s responsible for the Chromium success,
but given the above results where e.g. WPE MiniBrowser uses Skia as well, it’s evident that the problems lay above the particular graphics library.
Looking at the operations and browsers that render incorrectly, it’s clearly visible that even small problems - with either ordering of draw calls or clipping - lead to spectacularly broken results. The pinnacle of misery is the source-out
operation that is the most variable one across browsers. One has to admit, however, that WPE MiniBrowser is slightly closer to being correct than others.
Fixing the above problems is a long journey. After all, every single web engine has to be fixed in its own, specific way. If the specification would be a problem - it would be the obvious way to start. However, as mentioned in the section
Shadows meet globalCompositeOperation, the specification, is pretty clear on how drawing, shadows, and globalCompositeOperation come together. In such case, the next obvious place to
start improving things is a WPT test suite.
What makes WPT outstanding is that it is a de facto standard cross-browser test suite for testing the web platform stack. Thus the test suite is developed as an open collaboration effort by developers from around the globe and hence is very broad
in terms of specification coverage. What’s also important, the test results are actively evaluated against the popular browser engines and published under wpt.fyi, therefore putting some pressure on web engine developers
to fix the problems so that they keep up with competition.
Granted the above, extending WPE test suite by adding test cases to cover globalCompositeOperation operations combined with shadows is the reasonable first step towards the unification of browser implementations. This can be done either by
directly contributing tests to WPT, or by creating an issue. Personally, I’ve decided to file an issue first (WPT#46544) and to add
tests once I have some time. I haven’t contributed to WPT yet, but I’m excited to work with it soon. Once I land my first pull request, I’ll start fixing WebKit and I won’t hesitate to post some updates on this blog.
In this post I’ll try to document the journey starting from a WebKit issue and
ending up improving third-party projects that WebKitGTK and WPEWebKit depend on.
I’ve been working on WebKit’s GStreamer backends for a while. Usually some new
feature needed on WebKit side would trigger work …
In the previous post I talked about the plans of the WebKit ports currently using Cairo to switch to Skia for 2D rendering. Apple ports don’t use Cairo, so they won’t be switching to Skia. I understand the post title was confusing, I’m sorry about that. The original post has been updated for clarity.
In recent years we have had an ongoing effort to improve graphics performance of the WebKit GTK and WPE ports. As a result of this we shipped features like threaded rendering, the DMA-BUF renderer, or proper vertical retrace synchronization (VSync). While these improvements have helped keep WebKit competitive, and even perform better than other engines in some scenarios, it has been clear for a while that we were reaching the limits of what can be achieved with a CPU based 2D renderer.
There was an attempt at making Cairo support GPU rendering, which did not work particularly well due to the library being designed around stateful operation based upon the PostScript model—resulting in a convenient and familiar API, great output quality, but hard to retarget and with some particularly slow corner cases. Meanwhile, other web engines have moved more work to the GPU, including 2D rendering, where many operations are considerably faster.
We checked all the available 2D rendering libraries we could find, but none of them met all our requirements, so we decided to try writing our own library. At the beginning it worked really well, with impressive results in performance even compared to other GPU based alternatives. However, it proved challenging to find the right balance between performance and rendering quality, so we decided to try other alternatives before continuing with its development. Our next option had always been Skia. The main reason why we didn’t choose Skia from the beginning was that it didn’t provide a public library with API stability that distros can package and we can use like most of our dependencies. It still wasn’t what we wanted, but now we have more experience in WebKit maintaining third party dependencies inside the source tree like ANGLE and libwebrtc, so it was no longer a blocker either.
In December 2023 we made the decision of giving Skia a try internally and see if it would be worth the effort of maintaining the project as a third party module inside WebKit. In just one month we had implemented enough features to be able to run all MotionMark tests. The results in the desktop were quite impressive, getting double the score of MotionMark global result. We still had to do more tests in embedded devices which are the actual target of WPE, but it was clear that, at least in the desktop, with this very initial implementation that was not even optimized (we kept our current architecture that is optimized for CPU rendering) we got much better results. We decided that Skia was the option, so we continued working on it and doing more tests in embedded devices. In the boards that we tried we also got better results than CPU rendering, but the difference was not so big, which means that with less powerful GPUs and with our current architecture designed for CPU rendering we were not that far from CPU rendering. That’s the reason why we managed to keep WPE competitive in embeeded devices, but Skia will not only bring performance improvements, it will also simplify the code and will allow us to implement new features . So, we had enough data already to make the final decision of going with Skia.
In February 2024 we reached a point in which our Skia internal branch was in an “upstreamable” state, so there was no reason to continue working privately. We met with several teams from Google, Sony, Apple and Red Hat to discuss with them about our intention to switch from Cairo to Skia, upstreaming what we had as soon as possible. We got really positive feedback from all of them, so we sent an email to the WebKit developers mailing list to make it public. And again we only got positive feedback, so we started to prepare the patches to import Skia into WebKit, add the CMake integration and the initial Skia implementation for the WPE port that already landed in main.
We will continue working on the Skia implementation in upstream WebKit, and we also have plans to change our architecture to better support the GPU rendering case in a more efficient way. We don’t have a deadline, it will be ready when we have implemented everything currently supported by Cairo, we don’t plan to switch with regressions. We are focused on the WPE port for now, but at some point we will start working on GTK too and other ports using cairo will eventually start getting Skia support as well.
When the post has not description: field, this first paragraph is the excerpt but we want it to be rendered using markdown.
The rest of the post content is not relevant for this particular case.
This is a short PSA post announcing the return of the GNOME Web Canary builds.
Read on for the crunchy details.
A couple years ago I was blogging about the GNOME Web Canary
flavor.
In summary this special build of GNOME Web provides a preview of the upcoming
version of …
When accelerated compositing support was added to WebKitGTK, there was only X11. Our first approach was quite simple, we sent the web view widget Xwindow ID to the web process to be used as rendering target using GLX. This was very efficient, but soon we realized it broke the GTK rendering model so it was not possible to use a web view inside a GtkOverlay, for example, to show status messages on top. The solution was to use a redirected Xcomposite window in the web process, and use its ID as the render target using GLX. The pixmap ID of the redirected Xcomposite window was sent to the UI process to be painted in the web view widget using a Cairo Xlib surface. Since the rendering happens in the web process, this approach required to use Xdamage to monitor when the redirected Xcomposite window was updated to schedule a web view redraw.
Wayland support
To support accelerated compositing under Wayland we initially added a nested Wayland compositor running in the UI process. The web process connected to the nested Wayland compositor and created a surface to be used as the rendering target using EGL. The good thing about this approach compared to the X11 one, is that we can create an EGLImage from Wayland buffers and use a GDK GL context to paint the contents in the web view. This is more efficient than X11 because we can use OpenGL both in web and UI processes.
WPE, when using the fdo backend, uses the same approach of running a nested Wayland compositor, but in a more efficient way, using DMABUF instead of Wayland buffers when available. So, we decided to use libwpe in the GTK port only for rendering under Wayland, and eventually remove our Wayland compositor implementation.
Before the removal of the custom Wayland compositor we had all these possible combinations:
UI Process
X11: Cairo Xlib surface
Wayland: EGL
Web Process
X11: GLX using redirected Xwindow
Wayland (nested Wayland compositor): EGL using Wayland surface
Wayland (libwpe): EGL using libwpe to get the Wayland surface
To reduce a bit the differences, and to make it easier to support WebGL with ANGLE we decided to change X11 to prefer EGL if possible, falling back to GLX only if EGL failed.
GTK4
GTK4 was released and we added support for it. The fact that GTK4 uses GL by default should make the rendering more efficient in accelerated compositing mode. This is definitely true under Wayland, because we are using a GL context already, so we just keep passing a texture to GTK to paint the contents in the web view. However, in the case of X11 we still have a Cairo Xlib surface that GTK paints into a Cairo image surface to be uploaded to the GPU. With GTK4 now we have two more combinations in the UI process side X11 + GTK3, X11 + GTK4, Wayland + GTK3 and Wayland + GTK4.
Reducing all the combinations to (almost) one: DMABUF
All these combinations to support the different platforms made it quite difficult to maintain, every time we get a bug report about something not working in accelerated compositing mode we have to figure out the combination actually used by the reporter, GTK3 or GTK4? X11 or Wayland? using EGL or GLX? custom Wayland compositor or libwpe? driver? version? etc.
We are already using DMABUF in WebKit for different things like WebGL and media rendering, so we thought that we could also use it for sharing the rendered buffer between the web and UI processes. That would be a more efficient solution but it would also drastically reduce the amount of combinations to maintain. The web process always uses the surfaceless platform, so it doesn’t matter if it’s under Wayland or X11. Then we create a surfaceless context as the render target and use EGL and GBM APIs to export the contents as a DMABUF buffer. The UI process imports the DMABUF buffer using EGL and GBM too, to be passed to GTK as a texture that is painted in the web view.
This theoretically recudes all the previous combinations to just one (note that we removed GLX support entirely, making EGL a requirement for accelerated compositing), but there’s a problem under X11: GTK3 doesn’t support EGL on X11 and GTK4 defaults to EGL but falls back to GLX if it doesn’t find an EGL config that perfectly matches the screen visual. In my system it never finds that EGL config because mesa doesn’t expose any 32 bit depth config. So, in the case of GTK3 we have to manually download the buffer to CPU and paint normally using Cairo, but in the case of GTK4 + GLX, GTK uploads the buffer again to be painted using GLX. I don’t think it’s possible to force GTK to use EGL from the API, but at least you can use GDK_DEBUG=gl-egl.
WebKitGTK 2.41.1
WebKitGTK 2.41.1 is the first unstable release of this cycle and already includes the DMABUF support that is used by default. We encourage everybody to try it out and provide feedback or report any issue. Please, export the contents of webkit://gpu and attach it to the bug report when reporting any problem related to graphics. To check if the issue is a regression of the DMABUF implementation you can use WEBKIT_DISABLE_DMABUF_RENDERER=1 to use the WPE renderer or X11 instead. This environment variable and the WPE render/X11 code will be eventually removed if DMABUF works fine.
WPE
If this approach works fine we plan to use something similar for the WPE port and get rid of the nested Wayland compositor there too.
With the release of WebKitGTK 2.40.0, WebKitGTK now finally provides a stable API and ABI for GTK 4 applications. The following API versions are provided:
webkit2gtk-4.0: this API version uses GTK 3 and libsoup 2. It is obsolete and users should immediately port to webkit2gtk-4.1. To get this with WebKitGTK 2.40, build with -DPORT=GTK -DUSE_SOUP2=ON.
webkit2gtk-4.1: this API version uses GTK 3 and libsoup 3. It contains no other changes from webkit2gtk-4.0 besides the libsoup version. With WebKitGTK 2.40, this is the default API version that you get when you build with -DPORT=GTK. (In 2.42, this might require a different flag, e.g. -DUSE_GTK3=ON, which does not exist yet.)
webkitgtk-6.0: this API version uses GTK 4 and libsoup 3. To get this with WebKitGTK 2.40, build with -DPORT=GTK -DUSE_GTK4=ON. (In 2.42, this might become the default API version.)
WebKitGTK 2.38 had a different GTK 4 API version, webkit2gtk-5.0. This was an unstable/development API version and it is gone in 2.40, so applications using it will break. Fortunately, that should be very few applications. If your operating system ships GNOME 42, or any older version, or the new GNOME 44, then no applications use webkit2gtk-5.0 and you have no extra work to do. But for operating systems that ship GNOME 43, webkit2gtk-5.0 is used by gnome-builder, gnome-initial-setup, and evolution-data-server:
For evolution-data-server 3.46, use this patch which applies on evolution-data-server 3.46.4.
For gnome-initial-setup 43, use this patch which applies on gnome-initial-setup 43.2. (Update: for your convenience, this patch will be included in gnome-initial-setup 43.3.)
For gnome-builder 43, all required changes are present in version 43.7.
Remember, patching is only needed for GNOME 43. Other versions of GNOME will have no problems with WebKitGTK 2.40.
There is no proper online documentation yet, but in the meantime you can view the markdown source for the migration guide to help you with porting your applications. Although the API is now stable and it is close to feature parity with the GTK 3 version, there are some problems to be aware of:
No support for accessibility. The GTK and WebKitGTK developers are collaborating on a plan to fix this, and I hope this will be ready for WebKitGTK 2.42.
Various smaller regressions here and there. The GTK 4 version is almost as stable as GTK 3, and now is a good time to start using it. As with any interesting new software, there is still some work to do.
Big thanks to everyone who helped make this possible.
Some time ago we at Igalia embarked on the journey to ship
a GStreamer-powered WebRTC backend. This is
a long journey, it is not over, but we made some progress …
Leverage agile frameworks to provide a robust synopsis for high level overviews. Iterative approaches to corporate strategy foster collaborative thinking to further the overall value proposition. Organically grow the holistic world view of disruptive innovation via workplace diversity and empowerment.
Bring to the table win-win survival strategies to ensure proactive domination. At the end of the day, going forward, a new normal that has evolved from generation X is on the runway heading towards a streamlined cloud solution. User generated content in real-time will have multiple touchpoints for offshoring.
Capitalize on low hanging fruit to identify a ballpark value added activity to beta test. Override the digital divide with additional clickthroughs from DevOps. Nanotechnology immersion along the information highway will close the loop on focusing solely on the bottom line.
Leverage agile frameworks to provide a robust synopsis for high level overviews. Iterative approaches to corporate strategy foster collaborative thinking to further the overall value proposition. Organically grow the holistic world view of disruptive innovation via workplace diversity and empowerment.
Bring to the table win-win survival strategies to ensure proactive domination. At the end of the day, going forward, a new normal that has evolved from generation X is on the runway heading towards a streamlined cloud solution. User generated content in real-time will have multiple touchpoints for offshoring.
// this is a command functionmyCommand(){ let counter =0; counter++; }
// Test with a line break above this line. console.log('Test');
Bring to the table win-win survival strategies to ensure proactive domination. At the end of the day, going forward, a new normal that has evolved from generation X is on the runway heading towards a streamlined cloud solution. User generated content in real-time will have multiple touchpoints for offshoring.
// this is a command
function myCommand() {
let counter = 0;
counter++;
}
// Test with a line break above this line.
console.log('Test');
Capitalize on low hanging fruit to identify a ballpark value added activity to beta test. Override the digital divide with additional clickthroughs from DevOps. Nanotechnology immersion along the information highway will close the loop on focusing solely on the bottom line.
Today, WebKit in Linux operating systems is much more secure than it used to be. The problems that I previously discussed in this old, formerly-popular blog post are nowadays a thing of the past. Most major Linux operating systems now update WebKitGTK and WPE WebKit on a regular basis to ensure known vulnerabilities are fixed. (Not all Linux operating systems include WPE WebKit. It’s basically WebKitGTK without the dependency on GTK, and is the best choice if you want to use WebKit on embedded devices.) All major operating systems have removed older, insecure versions of WebKitGTK (“WebKit 1”) that were previously a major security problem for Linux users. And today WebKitGTK and WPE WebKit both provide a webkit_web_context_set_sandbox_enabled() API which, if enabled, employs Linux namespaces to prevent a compromised web content process from accessing your personal data, similar to Flatpak’s sandbox. (If you are a developer and your application does not already enable the sandbox, you should fix that!)
Unfortunately, QtWebKit has not benefited from these improvements. QtWebKit was removed from the upstream WebKit codebase back in 2013. Its current status in Fedora is, unfortunately, representative of other major Linux operating systems. Fedora currently contains two versions of QtWebKit:
The qtwebkit package contains upstream QtWebKit 2.3.4 from 2014. I believe this is used by Qt 4 applications. For avoidance of doubt, you should not use applications that depend on a web engine that has not been updated in eight years.
The newer qt5-qtwebkit contains Konstantin Tokarev’s fork of QtWebKit, which is de facto the new upstream and without a doubt the best version of QtWebKit available currently. Although it has received occasional updates, most recently 5.212.0-alpha4 from March 2020, it’s still based on WebKitGTK 2.12 from 2016, and the release notes bluntly state that it’s not very safe to use. Looking at WebKitGTK security advisories beginning with WSA-2016-0006, I manually counted 507 CVEs that have been fixed in WebKitGTK 2.14.0 or newer.
These CVEs are mostly (but not exclusively) remote code execution vulnerabilities. Many of those CVEs no doubt correspond to bugs that were introduced more recently than 2.12, but the exact number is not important: what’s important is that it’s a lot, far too many for backporting security fixes to be practical. Since qt5-qtwebkit is two years newer than qtwebkit, the qtwebkit package is no doubt in even worse shape. And because QtWebKit does not have any web process sandbox, any remote code execution is game over: an attacker that exploits QtWebKit gains full access to your user account on your computer, and can steal or destroy all your files, read all your passwords out of your password manager, and do anything else that your user account can do with your computer. In contrast, with WebKitGTK or WPE WebKit’s web process sandbox enabled, attackers only get access to content that’s mounted within the sandbox, which is a much more limited environment without access to your home directory or session bus.
In short, it’s long past time for Linux operating systems to remove QtWebKit and everything that depends on it. Do not feed untrusted data into QtWebKit. Don’t give it any HTML that you didn’t write yourself, and certainly don’t give it anything that contains injected data. Uninstall it and whatever applications depend on it.
Update: I forgot to mention what to do if you are a developer and your application still uses QtWebKit. You should ensure it uses the most recent release of QtWebEngine for Qt 6. Do not use old versions of Qt 6, and do not use QtWebEngine for Qt 5.
These articles are an interesting read not only if you're working on
WebKit, but also if you are curious on how a modern browser engine
works and some of the moving parts beneath the surface. So go check them out!
On a related note, the WebKit team is always on the lookout for talent
to join us. Experience with WebKit or browsers is not necessarily a
must, as we know from experience that anyone with a strong C/C++
background and enough curiosity will be able to ramp up and start
contributing soon enough. If these articles spark your curiosity,
feel free to reach out to me to find out more
or to
apply directly!
This article begins a series of technical writeups on the
architecture of WPE, and we hope to publish during the rest of the
year further articles breaking down different components of WebKit,
including graphics and other subsystems, that will surely be
of great help for those interested in getting more familiar
with WebKit and its internals.
Today I am happy to unveil GNOME Web Canary which aims to provide bleeding edge,
most likely very unstable builds of Epiphany, depending on daily builds of the
WebKitGTK development version. Read on to know more about this.
Until recently the GNOME Web browser was available for end-users in two …
This is the last post of the series showing interesting debugging tools, I hope you have found it useful. Don’t miss the custom scripts at the bottom to process GStreamer logs, help you highlight the interesting parts and find the root cause of difficult bugs. Here are also the previous posts of the series:
This is useful to know why a particular package isn’t found and what are the default values for PKG_CONFIG_PATH when it’s not defined. For example:
Adding directory '/usr/local/lib/x86_64-linux-gnu/pkgconfig' from PKG_CONFIG_PATH
Adding directory '/usr/local/lib/pkgconfig' from PKG_CONFIG_PATH
Adding directory '/usr/local/share/pkgconfig' from PKG_CONFIG_PATH
Adding directory '/usr/lib/x86_64-linux-gnu/pkgconfig' from PKG_CONFIG_PATH
Adding directory '/usr/lib/pkgconfig' from PKG_CONFIG_PATH
Adding directory '/usr/share/pkgconfig' from PKG_CONFIG_PATH
If we have tuned PKG_CONFIG_PATH, maybe we also want to add the default paths. For example:
SYSROOT=~/sysroot-x86-64
export PKG_CONFIG_PATH=${SYSROOT}/usr/local/lib/pkgconfig:${SYSROOT}/usr/lib/pkgconfig
# Add also the standard pkg-config paths to find libraries in the system
export PKG_CONFIG_PATH=${PKG_CONFIG_PATH}:/usr/local/lib/x86_64-linux-gnu/pkgconfig:\
/usr/local/lib/pkgconfig:/usr/local/share/pkgconfig:/usr/lib/x86_64-linux-gnu/pkgconfig:\
/usr/lib/pkgconfig:/usr/share/pkgconfig
# This tells pkg-config where the "system" pkg-config dir is. This is useful when cross-compiling for other
# architecture, to avoid pkg-config using the system .pc files and mixing host and target libraries
export PKG_CONFIG_LIBDIR=${SYSROOT}/usr/lib
# This could have been used for cross compiling:
#export PKG_CONFIG_SYSROOT_DIR=${SYSROOT}
Man in the middle proxy for WebKit
Sometimes it’s useful to use our own modified/unminified files with a 3rd party service we don’t control. Mitmproxy can be used as a man-in-the-middle proxy, but I haven’t tried it personally yet. What I have tried (with WPE) is this:
Add an /etc/hosts entry to point the host serving the files we want to change to an IP address controlled by us.
Configure a web server to provide the files in the expected path.
:bulb: Pro tip: If you have to debug minified/obfuscated JavaScript code and don’t have a deobfuscated version to use in a man-in-the-middle fashion, use http://www.jsnice.org/ to deobfuscate it and get meaningful variable names.
Bandwidth control for a dependent device
If your computer has a “shared internet connection” enabled in Network Manager and provides access to a dependent device , you can control the bandwidth offered to that device. This is useful to trigger quality changes on adaptive streaming videos from services out of your control.
This can be done using tc, the Traffic Control tool from the Linux kernel. You can use this script to automate the process (edit it to suit to your needs).
Useful scripts to process GStreamer logs
I use these scripts in my daily job to look for strange patterns in GStreamer logs that help me to find the cause of the bugs I’m debugging:
h: Highlights each expression in the command line in a different color.
mgrep: Greps (only) for the lines with the expressions in the command line and highlights each expression in a different color.
filter-time: Gets a subset of the log lines between a start and (optionally) an end GStreamer log timestamp.
highlight-threads: Highlights each thread in a GStreamer log with a different color. That way it’s easier to follow a thread with the naked eye.
remove-ansi-colors: Removes the color codes from a colored GStreamer log.
aha: ANSI-HTML-Adapter converts plain text with color codes to HTML, so you can share your GStreamer logs from a web server (eg: for bug discussion). Available in most distros.
gstbuffer-leak-analyzer: Analyzes a GStreamer log and shows unbalances in the creation/destruction of GstBuffer and GstMemory objects.
In this new post series, I’ll show you how both existing and ad-hoc tools can be helpful to find the root cause of some problems. Here are also the older posts of this series in case you find them useful:
Use strace to know which config/library files are used by a program
If you’re becoming crazy supposing that the program should use some config and it seems to ignore it, just use strace to check what config files, libraries or other kind of files is the program actually using. Use the grep rules you need to refine the search:
First, try to strace -e trace=signal -p 1234 the killed process.
If that doesn’t work (eg: because it’s being killed with the uncatchable SIGKILL signal), then you can resort to modifying the kernel source code (signal.c) to log the calls to kill():
If you ever find yourself with little time in front of a stubborn build system and, no matter what you try, you can’t get the right flags to the compiler, think about putting something (a wrapper) between the build system and the compiler. Example for g++:
#!/bin/bash
main() {
# Build up arg[] array with all options to be passed
# to subcommand.
i=0
for opt in "$@"; do
case "$opt" in
-O2) ;; # Removes this option
*)
arg[i]="$opt" # Keeps the others
i=$((i+1))
;;
esac
done
EXTRA_FLAGS="-O0" # Adds extra option
echo "g++ ${EXTRA_FLAGS} ${arg[@]}" # >> /tmp/build.log # Logs the command
/usr/bin/ccache g++ ${EXTRA_FLAGS} "${arg[@]}" # Runs the command
}
main "$@"
Make sure that the wrappers appear earlier than the real commands in your PATH.
The make wrapper can also call remake instead. Remake is fully compatible with make but has features to help debugging compilation and makefile errors.
The source code shown below must be placed in the .h where the class to be debugged is defined. It’s written in a way that doesn’t need to rebuild RefCounted.h, so it saves a lot of build time. It logs all refs, unrefs and adoptPtrs, so that any anomaly in the refcounting can be traced and investigated later. To use it, just make your class inherit from LoggedRefCounted instead of RefCounted.
Example output:
void WTF::adopted(WTF::LoggedRefCounted<T>*) [with T = WebCore::MediaSourceClientGStreamerMSE]: this=0x673c07a4, refCount 1
void WTF::adopted(WTF::LoggedRefCounted<T>*) [with T = WebCore::MediaSourceClientGStreamerMSE]: this=0x673c07a4, refCount 1
^^^ Two adopts, this is not good.
void WTF::LoggedRefCounted<T>::ref() [with T = WebCore::MediaSourceClientGStreamerMSE]: this=0x673c07a4, refCount 1 --> ...
void WTF::LoggedRefCounted<T>::ref() [with T = WebCore::MediaSourceClientGStreamerMSE]: this=0x673c07a4, refCount ... --> 2
void WTF::LoggedRefCounted<T>::deref() [with T = WebCore::MediaSourceClientGStreamerMSE]: this=0x673c07a4, refCount 2 --> ...
void WTF::LoggedRefCounted<T>::deref() [with T = WebCore::MediaSourceClientGStreamerMSE]: this=0x673c07a4, refCount ... --> 1
void WTF::adopted(WTF::LoggedRefCounted<T>*) [with T = WebCore::MediaSourceClientGStreamerMSE]: this=0x673c07a4, refCount 1
void WTF::LoggedRefCounted<T>::deref() [with T = WebCore::MediaSourceClientGStreamerMSE]: this=0x673c07a4, refCount 1 --> ...
void WTF::LoggedRefCounted<T>::deref() [with T = WebCore::MediaSourceClientGStreamerMSE]: this=0x673c07a4, refCount 1 --> ...
^^^ Two recursive derefs, not good either.
It only works #if ENABLE(DEVELOPER_MODE), so you might want to remove those ifdefs if you’re building in Release mode.
Log tracers
In big pipelines (e.g. playbin) it can be very hard to find what element is replying to a query or handling an event. Even using gdb can be extremely tedious due to the very high level of recursion. My coworker Alicia commented that using log tracers is more helpful in this case.
GST_TRACERS=log enables additional GST_TRACE() calls all accross GStreamer. The following example logs entries and exits into the query function.
GST_TRACERS=log GST_DEBUG='query:TRACE'
The names of the logging categories are somewhat inconsistent:
log (the log tracer itself)
GST_BUFFER
GST_BUFFER_LIST
GST_EVENT
GST_MESSAGE
GST_STATES
GST_PADS
GST_ELEMENT_PADS
GST_ELEMENT_FACTORY
query
bin
The log tracer code is in subprojects/gstreamer/plugins/tracers/gstlog.c.
The thread id is generated by Linux and can take values higher than 1-9, just like PIDs. This thread number is useful to know which function calls are issued by the same thread, avoiding confusion between threads.
And use it like this in all the functions you want to trace:
void somefunction() {
MYTRACER();
// Some other code...
}
The constructor will log when the execution flow enters into the function and the destructor will log when the flow exits.
Setting breakpoints from C
In the C code, just call raise(SIGINT) (simulate CTRL+C, normally the program would finish).
And then, in a previously attached gdb, after breaking and having debugging all you needed, just continue the execution by ignoring the signal or just plainly continuing:
(gdb) signal 0
(gdb) continue
There’s a way to do the same but attaching gdb after the raise. Use raise(SIGSTOP) instead (simulate CTRL+Z). Then attach gdb, locate the thread calling raise and switch to it:
(gdb) thread apply all bt
[now search for "raise" in the terminal log]
Thread 36 (Thread 1977.2033): #1 0x74f5b3f2 in raise () from /home/enrique/buildroot/output2/staging/lib/libpthread.so.0
(gdb) thread 36
Now, from a terminal, send a continuation signal: kill -SIGCONT 1977. Finally instruct gdb to single-step only the current thread (IMPORTANT!) and run some steps until all the raises have been processed:
(gdb) set scheduler-locking on
(gdb) next // Repeat several times...
Know the name of a GStreamer function stored in a pointer at runtime
Just use this macro:
GST_DEBUG_FUNCPTR_NAME(func)
Detecting memory leaks in WebKit
RefCountedLeakCounter is a tool class that can help to debug reference leaks by printing this kind of messages when WebKit exits:
This is the continuation of the GStreamer WebKit debugging tricks post series. In the next three posts, I’ll focus on what we can get by doing some little changes to the source code for debugging purposes (known as “instrumenting”), but before, you might want to check the previous posts of the series:
Know all the env vars read by a program by using LD_PRELOAD to intercept libc calls
// File getenv.c
// To compile: gcc -shared -Wall -fPIC -o getenv.so getenv.c -ldl
// To use: export LD_PRELOAD="./getenv.so", then run any program you want
// See http://www.catonmat.net/blog/simple-ld-preload-tutorial-part-2/
#define _GNU_SOURCE
#include <stdio.h>
#include <dlfcn.h>
// This function will take the place of the original getenv() in libc
char *getenv(const char *name) {
printf("Calling getenv(\"%s\")\n", name);
char *(*original_getenv)(const char*);
original_getenv = dlsym(RTLD_NEXT, "getenv");
return (*original_getenv)(name);
}
See the breakpoints with command example to know how to get the same using gdb. Check also Zan’s libpine for more features.
Track lifetime of GObjects by LD_PRELOADing gobject-list
The gobject-list project, written by Thibault Saunier, is a simple LD_PRELOAD library for tracking the lifetime of GObjects. When loaded into an application, it prints a list of living GObjects on exiting the application (unless the application crashes), and also prints reference count data when it changes. SIGUSR1 or SIGUSR2 can be sent to the application to trigger printing of more information.
Overriding the behaviour of a debugging macro
The usual debugging macros aren’t printing messages? Redefine them to make what you want:
First arguments (channel, msg) are captured intependently
The remaining args are captured in __VA_ARGS__
do while(false) is a trick to avoid {braces} and make the code block work when used in if/then/else one-liners
#channel expands LOG(MyChannel,....) as printf("%s: ", "MyChannel"). It’s called “stringification”.
## __VA_ARGS__ expands the variable argument list as a comma-separated list of items, but if the list is empty, it eats the comma after “msg”, preventing syntax errors
Print the compile-time type of an expression
Use typeid(<expression>).name(). Filter the ouput through c++filt -t:
Abusing the compiler to know all the places where a function is called
If you want to know all the places from where the GstClockTime toGstClockTime(float time) function is called, you can convert it to a template function and use static_assert on a wrong datatype like this (in the .h):
Note that T=float is different to integer (is_integral). It has nothing to do with the float time parameter declaration.
You will get compile-time errors like this on every place the function is used:
WebKitMediaSourceGStreamer.cpp:474:87: required from here
GStreamerUtilities.h:84:43: error: static assertion failed: Don't call toGstClockTime(float)!
Use pragma message to print values at compile time
Sometimes is useful to know if a particular define is enabled:
#include <limits.h>
#define _STR(x) #x
#define STR(x) _STR(x)
#pragma message "Int max is " STR(INT_MAX)
#ifdef WHATEVER
#pragma message "Compilation goes by here"
#else
#pragma message "Compilation goes by there"
#endif
...
The code above would generate this output:
test.c:6:9: note: #pragma message: Int max is 0x7fffffff
#pragma message "Int max is " STR(INT_MAX)
^~~~~~~
test.c:11:9: note: #pragma message: Compilation goes by there
#pragma message "Compilation goes by there"
^~~~~~~
This post is a continuation of a series of blog posts about the most interesting debugging tricks I’ve found while working on GStreamer WebKit on embedded devices. These are the other posts of the series published so far:
Sometimes the symbol names aren’t printed in the stack memdump. You can do this trick to iterate the stack and print the symbols found there (take with a grain of salt!):
(gdb) set $i = 0
(gdb) p/a *((void**)($sp + 4*$i++))
[Press ENTER multiple times to repeat the command]
$46 = 0xb6f9fb17 <_dl_lookup_symbol_x+250>
$58 = 0xb40a9001 <g_log_writer_standard_streams+128>
$142 = 0xb40a877b <g_return_if_fail_warning+22>
$154 = 0xb65a93d5 <WebCore::MediaPlayerPrivateGStreamer::changePipelineState(GstState)+180>
$164 = 0xb65ab4e5 <WebCore::MediaPlayerPrivateGStreamer::playbackPosition() const+420>
...
Many times it’s just a matter of gdb not having loaded the unstripped version of the library. /proc/<PID>/smaps and info proc mappings can help to locate the library providing the missing symbol. Then we can load it by hand.
For instance, for this backtrace:
#0 0x740ad3fc in syscall () from /home/enrique/buildroot-wpe/output/staging/lib/libc.so.6
#1 0x74375c44 in g_cond_wait () from /home/enrique/buildroot-wpe/output/staging/usr/lib/libglib-2.0.so.0
#2 0x6cfd0d60 in ?? ()
In a shell, we examine smaps and find out that the unknown piece of code comes from libgstomx:
Now we load the unstripped .so in gdb and we’re able to see the new symbol afterwards:
(gdb) add-symbol-file /home/enrique/buildroot-wpe/output/build/gst-omx-custom/omx/.libs/libgstomx.so 0x6cfc1000
(gdb) bt
#0 0x740ad3fc in syscall () from /home/enrique/buildroot-wpe/output/staging/lib/libc.so.6
#1 0x74375c44 in g_cond_wait () from /home/enrique/buildroot-wpe/output/staging/usr/lib/libglib-2.0.so.0
#2 0x6cfd0d60 in gst_omx_video_dec_loop (self=0x6e0c8130) at gstomxvideodec.c:1311
#3 0x6e0c8130 in ?? ()
Useful script to prepare the add-symbol-file:
cat /proc/715/smaps | grep '[.]so' | sed -e 's/-[0-9a-f]*//' | { while read ADDR _ _ _ _ LIB; do echo "add-symbol-file $LIB 0x$ADDR"; done; }
The “figuring out corrupt ARM stacktraces” post has some additional info about how to use addr2line to translate memory addresses to function names on systems with a hostile debugging environment.
Debugging a binary without debug symbols
There are times when there’s just no way to get debug symbols working, or where we’re simply debugging on a release version of the software. In those cases, we must directly debug the assembly code. The gdb text user interface (TUI) can be used to examine the disassebled code and the CPU registers. It can be enabled with these commands:
layout asm
layout regs
set print asm-demangle
Some useful keybindings in this mode:
Arrows: scroll the disassemble window
CTRL+p/n: Navigate history (previously done with up/down arrows)
CTRL+b/f: Go backward/forward one character (previously left/right arrows)
CTRL+d: Delete character (previously “Del” key)
CTRL+a/e: Go to the start/end of the line
This screenshot shows how we can infer that an empty RefPtr is causing a crash in some WebKit code.
Wake up an unresponsive gdb on ARM
Sometimes, when you continue (‘c’) execution on ARM there’s no way to stop it again unless a breakpoint is hit. But there’s a trick to retake the control: just send a harmless signal to the process.
kill -SIGCONT 1234
Know which GStreamer thread id matches with each gdb thread
Sometimes you need to match threads in the GStreamer logs with threads in a running gdb session. The simplest way is to ask it to GThread for each gdb thread:
(gdb) set output-radix 16
(gdb) thread apply all call g_thread_self()
This will print a list of gdb threads and GThread*. We only need to find the one we’re looking for.
Generate a pipeline dump from gdb
If we have a pointer to the pipeline object, we can call the function that dumps the pipeline:
I’ve been developing and debugging desktop and mobile applications on embedded devices over the last decade or so. The main part of this period I’ve been focused on the multimedia side of the WebKit ports using GStreamer, an area that is a mix of C (glib, GObject and GStreamer) and C++ (WebKit).
Over these years I’ve had to work on ARM embedded devices (mobile phones, set-top-boxes, Raspberry Pi using buildroot) where most of the environment aids and tools we take for granted on a regular x86 Linux desktop just aren’t available. In these situations you have to be imaginative and find your own way to get the work done and debug the issues you find in along the way.
I’ve been writing down the most interesting tricks I’ve found in this journey and I’m sharing them with you in a series of 7 blog posts, one per week. Most of them aren’t mine, and the ones I learnt in the begining of my career can even seem a bit naive, but I find them worth to share anyway. I hope you find them as useful as I do.
Breakpoints with command
You can break on a place, run some command and continue execution. Useful to get logs:
break getenv
command
# This disables scroll continue messages
# and supresses output
silent
set pagination off
p (char*)$r0
continue
end
break grl-xml-factory.c:2720 if (data != 0)
command
call grl_source_get_id(data->source)
# $ is the last value in the history, the result of
# the previous call
call grl_media_set_source (send_item->media, $)
call grl_media_serialize_extended (send_item->media,
GRL_MEDIA_SERIALIZE_FULL)
continue
end
Nearly five years ago, when I was in grad school, I stumbled across the paper Collaboration in the open-source arena: The WebKit case when trying to figure out what I would do for a course project in network theory (i.e. graph theory, not computer networking; I’ll use the words “graph” and “network” interchangeably). The paper evaluates collaboration networks, which are graphs where collaborators are represented by nodes and relationships between collaborators are represented by edges. Our professor had used collaboration networks as examples during lecture, so it seemed at least mildly relevant to our class, and I wound up writing a critique on this paper for the class project. In this paper, the authors construct collaboration networks for WebKit by examining the project’s changelog files to define relationships between developers. They perform “community detection” to visually group developers who work closely together into separate clusters in the graphs. Then, the authors use those graphs to arrive at various conclusions about WebKit (e.g. “[e]ven if Samsung and Apple are involved in expensive patent wars in the courts and stopped collaborating on hardware components, their contributions remained strong and central within the WebKit open source project,” regarding the period from 2008 to 2013).
At the time, I contacted the authors to let them know about some serious problems I found with their work. Then I left the paper sitting in a short-term to-do pile on my desk, where it has been sitting since Obama was president, waiting for me to finally write this blog post. Unfortunately, nearly five years later, the authors’ email addresses no longer work, which is not very surprising after so long — since I’m no longer a student, the email I originally used to contact them doesn’t work anymore either — so I was unable to contact them again to let them know that I was finally going to publish this blog post. Anyway, suffice to say that the conclusions of the paper were all correct; however, the networks used to arrive at those conclusions suffered from three different mistakes, each of which was, on its own, serious enough to invalidate the entire work.
So if the analysis of the networks was bogus, how did the authors arrive at correct conclusions anyway? The answer is confirmation bias. The study was performed by visually looking at networks and then coming to non-rigorous conclusions about the networks, and by researching the WebKit community to learn what is going on with the major companies involved in the project. The authors arrived at correct conclusions because they did a good job at the latter, then saw what they wanted to see in the graphs.
I don’t want to be too harsh on the authors of this paper, though, because they decided to publish their raw data and methodology on the internet. They even published the python scripts they used to convert WebKit changelogs into collaboration graphs. Had they not done so, there is no way I would have noticed the third (and most important) mistake that I’ll discuss below, and I wouldn’t have been able to confirm my suspicions about the second mistake. You would not be reading this right now, and likely nobody would ever have realized the problems with the paper. The authors of most scientific papers are not nearly so transparent: many researchers today consider their source code and raw data to be either proprietary secrets to be guarded, or simply not important enough to merit publication. The authors of this paper deserve to be commended, not penalized, for their openness. Mistakes are normal in research papers, and open data is by far the best way for us to be able to detect mistakes when they happen.
A collaboration network from the paper. The paper reports that this network represents collaboration between September 2008 (when Google began contributing to WebKit) and February 2011 (the departure of Nokia from the project). Because the authors posted their data online, I noticed that this was a mistake in the paper: the graph actually represents the period between February 2011 and July 2012. The paper’s analysis of this graph is therefore questionable, but note this was only a minor mistake compared to the three major mistakes that impact this network. Note the suspiciously-high number of unaffiliated (“Other”) contributors in a corporate-dominated project.
The rest of this blog post is a simplified version of my original school paper from 2016. I’ve removed maybe half the original content, including some flowery academic language and unnecessary references to class material (e.g. “community detection was performed using fast modularity maximization to generate an alternate visualization of the network,” good for high scores on class papers, not so good for blog posts). But rewriting everything to be informal takes a long time, and I want to finish this today so it’s not still on my desk five more years from now, so the rest of this blog post is still going to be much more formal than normal. Oh well. Tone shift now!
We (“we” means “I”) examine various methodological issues discovered by analyzing the paper. The first section discusses the effects on the collaboration network of choosing a poor definition of collaboration. The second section discusses a major source of error in detecting the company affiliation of many contributors. The third section describes a serious mistake in the data collection process. Each of these issues is quite severe, and any one alone calls into question the validity of the entire study. It must be noted that such issues are not necessarily unique to this paper, and must be kept in mind for all future studies that utilize collaboration networks.
Mistake #1: Poorly-defined Collaboration
The precise definition used to model collaboration has tremendous impact on the usefulness of the resultant collaboration network. Many collaboration networks are built using definitions of collaboration that are self-evidently useful, where there is little doubt that edges in the network represent real-world collaboration. The paper adopts an approach to building collaboration networks where developers are represented by nodes, and an edge exists between two nodes if the corresponding developers modified the same source code file during the time period under consideration for the construction of the network. However, it is not clear that this definition of collaboration is actually useful. Consider that it is a regular occurrence for developers who do not know each other and may have never communicated to modify the same files. Consider also that modifying a common file does not necessarily reflect any shared interest in a particular portion of the software project. For instance, a file might be modified when making an interface change in another file, or when fixing a build error occurring on a particular platform. Such occurrences are, in fact, extremely common in the WebKit project. Additionally, consider that there exist particular source code files that are unusually central to the project, and must be modified more frequently than other files. It is highly likely that almost all developers will at one point or another make some change in such a file, and therefore be connected via a collaboration edge to all other developers who have ever modified that file. (My original critique shows a screenshot of the revision history of WebPageProxy.cpp, to demonstrate that the developers modifying this file were working on unrelated projects.)
It is true, as assumed by the paper, that particular developers work on different portions of the WebKit source code, and collaborate more with particular other developers. For instance, developers who work for the same company typically, though not always, collaborate most with other developers from that same company. However, the paper’s naive definition of collaboration should ensure that most developers will be considered to have collaborated equally with most other developers, regardless of the actual degree of collaboration. For instance, consider developers A and B who regularly collaborate on a particular source file. Now, developer C, who works on a platform that does not use this file and would not ordinarily need to modify it, makes a change to some cross-platform interface in another file that requires updating this file. Developer C is now considered to have collaborated with developers A and B on this file! Clearly, this is not a desirable result, as developers A and B have collaborated far more on the development of the file. Moreover, consider that an edge exists between two developers in the collaboration network if they have ever both modified any file anywhere in WebKit during the time period under review; then we can expect to form a network that is almost complete (a “full” graph where edges exists between most nodes). It is evident that some method of weighting collaboration between different contributors would be desirable, as the unweighted collaboration network does not seem useful.
One might argue that the networks presented in the paper clearly show developers exist in subcommunities on the peripheries of the network, that the network is clearly not complete, and that therefore this definition of collaboration sufficed, at least to some extent. However, this is only due to another methodological error in the study. Mistake #3, discussed later, explains how the study managed to produce collaboration networks with noticeable subcommunities despite these issues.
We note that the authors chose this same definition of collaboration in their more recent work on OpenStack, so there exist multiple studies using this same flawed definition of collaboration. We speculate that this definition of collaboration is unlikely to be more suitable for OpenStack or for other software projects than it is for WebKit. The software engineering research community must explore alternative models of collaboration when undertaking future studies of software development collaboration networks in order to more accurately reflect collaboration.
Mistake #2: Misdetected Contributor Affiliation
One difficulty when building collaboration networks is the need to correctly match each contributor with the correct company affiliation. Although many free software projects are dominated by unaffiliated contributors, others, like WebKit, are primarily developed by paid contributors. Looking at the number of times a particular email domain appears in WebKit changelog entries made during 2015, most contributors commit using corporate emails, but many developers commit to WebKit using personal email accounts, such as Gmail accounts; additionally, many developers use generic webkit.org email aliases, which were previously available to active WebKit contributors. These developers may or may not be affiliated with companies that contribute to the project. Use of personal email addresses is a source of inaccuracy when constructing collaboration networks, as it results in an undercount of corporate contributions. We can expect this issue has led to serious inaccuracies in the reported collaboration networks.
This substantial source of error is neither mentioned nor accounted for; all contributors using such email accounts were therefore miscategorized as unaffiliated. However, the authors clearly recognized this issue, as it has been accounted for in their more recent work covering OpenStack by cross-referencing email addresses from git revision history with a database containing corporate affiliations maintained by the OpenStack Foundation. Unfortunately, no such effort was made for the WebKit data set.
The WebKit project was previously dominated by contributors with chromium.org email domains. This domain is equivalent to webkit.org in that it can be used by contributors to the Chromium project regardless of corporate affiliation; however, most contributors with Chromium emails are actually Google employees. The high use of Chromium emails by Google employees appears to have led to a dramatic — by roughly an entire order of magnitude — undercount of Google’s contributors to the WebKit project, as only contributors with google.com emails were considered to be Google employees. The vast majority of Google employees used chromium.org emails, and so were counted as unaffiliated developers. This explains the extraordinarily high number of unaffiliated developers in the networks presented by the paper, despite the fact that WebKit development is, in reality, dominated by corporate contributors.
Mistake #3: Missing Most Changelog Data
The paper incorrectly claims to have gathered its data from both WebKit’s Subversion revision history and from its changelog files. We must draw a distinction between changelog entries and Subversion revision history. Changelog entries are inserted into changelog files that are committed into the Subversion repository; they are completely separate from the Subversion history. Each subproject within the WebKit project has its own set of changelog files used to record changes under the corresponding directory.
In fact, the paper processed only the changelog files. This was actually a good choice, as WebKit’s changelog files are much more accurate than the Subversion history, for two reasons. Firstly, it is easy for a contributor to change the email address entered into a changelog file, e.g. after a change in company affiliation. However, it is difficult to change the email address used to commit to Subversion, as this requires requesting a new Subversion account from the Subversion administrator; accordingly, contributors are more likely to use older email addresses, lacking accurate company affiliation, in Subversion revisions than in changelog files. Secondly, many Subversion revisions are not directly committed by contributors, but rather are actually committed by the commit queue bot, which runs various tests before committing the revision. Subversion revisions are also, more rarely, committed by a completely different contributor than the patch author. In both cases, the proper contributor’s name will appear in only the changelog file, and not the Subversion data. Some developers are dramatically more likely to use the commit queue than others. Various other reviews of WebKit contribution history that examine data from Subversion history rather than from changelog files are flawed for this reason. Fortunately, by relying on changelog files rather than Subversion metadata, the authors avoid this problem.
Unfortunately, a serious error was made in processing the changelog data. WebKit has many different sets of changelog files, stored in various project subdirectories (JavaScriptCore, WebCore, WebKit, etc.), as well as toplevel changelogs stored in the root directory of the project. Regrettably, the authors were unaware of the changelogs in subdirectories, and based their analysis only on the toplevel changelogs, which contain only changes that occurred in subdirectories that lack their own changelog files. In practice, this inadvertently restricted the scope of the analysis to a very small minority of changes, primarily to build system files, manual tests, and the WebKit website. That is, the reported collaboration networks do not reflect collaboration on any actual source code files. All source code files are contained in subdirectories with their own changelog files, and therefore no source code files were actually considered in the analysis of collaboration on source code changes.
We speculate that the analysis’s focus on build system files likely exaggerates the effects of clustering in the network, as different companies used different build systems and thus were less likely to edit the build systems used by other companies, and that an analysis based on the correct data would display less of a clustering effect. Certainly, there would be dramatically more edges in the already-dense networks, because an edge exists between two developers if there exists any one file in WebKit that both developers have modified. Omitting all of the source code files from the analysis therefore dramatically reduces the likelihood of edges existing between nodes in the network.
Conclusion
We found that the original study was impacted by an unsuitable definition of collaboration used to build the collaboration networks, severe errors in counting contributor affiliation (including the classification of most Google employees as unaffiliated developers), and the omission of almost all the required data from the analysis, including all data on modifications to source code files. The authors constructed and studied essentially meaningless networks. Nevertheless, the authors were able to derive many accurate conclusions about the WebKit project from their inaccurate collaboration networks. Such conclusions illustrate the dangers of seeking to find particular meanings or explanations through visual inspection of collaboration networks. Researchers must work forwards from the collaboration networks to arrive at their conclusions, rather than backwards by attempting to match the networks to conclusions gained from prior knowledge.
Original Report
Wow, OK, you actually read this far? Since this blog post criticizes an academic paper, and since this blog post does not include various tables and examples that support my arguments, I’ve attached my original analysis in full. It is a boring, student-quality grad school project written with the objective of scoring the highest-possible grade in a class rather than for clarity, and you probably don’t want to look at it unless you are investigating the paper in detail. (If you download that, note that I no longer work for Igalia, and the paper was not authorized by Igalia either; I used my company email to disclose my affiliation and maybe impress my professor a little.) Phew, now I can finally remove this from my desk!
Over the past few months the WebKit development team has been working on
modernizing support for the WebAudio specification. This post highlights some
of the changes that were recently merged, focusing on the GStreamer ports.
My fellow WebKit colleague, Chris Dumez, has been very active lately, updating
the WebAudio implementation …
In this line of work, we all stumble at least once upon a problem
that turns out to be extremely elusive and very tricky to narrow down
and solve. If we&aposre lucky, we might have everything at our
disposal to diagnose the problem but sometimes that&aposs not the
case – and in embedded development it&aposs often not the
case. Add to the mix proprietary drivers, lack of debugging symbols, a
bug that&aposs very hard to reproduce under a controlled environment,
and weeks in partial confinement due to a pandemic and what you have
is better described as a very long lucid nightmare. Thankfully,
even the worst of nightmares end when morning comes, even if sometimes
morning might be several days away. And when the fix to the problem is
in an inimaginable place, the story is definitely one worth
telling.
The problem
It all started with one
of Igalia&aposs customers deploying
a WPE WebKit-based browser in
their embedded devices. Their CI infrastructure had detected a problem
caused when the browser was tasked with creating a new webview (in
layman terms, you can imagine that to be the same as opening a new tab
in your browser). Occasionally, this view would never load, causing
ongoing tests to fail. For some reason, the test failure had a
reproducibility of ~75% in the CI environment, but during manual
testing it would occur with less than a 1% of probability. For reasons
that are beyond the scope of this post, the CI infrastructure was not
reachable in a way that would allow to have access to running
processes in order to diagnose the problem more easily. So with only
logs at hand and less than a 1/100 chances of reproducing the bug
myself, I set to debug this problem locally.
Diagnosis
The first that became evident was that, whenever this bug would
occur, the WebKit feature known as web extension (an
application-specific loadable module that is used to allow the program
to have access to the internals of a web page, as well to enable
customizable communication with the process where the page contents
are loaded – the web process) wouldn&apost work. The browser would be
forever waiting that the web extension loads, and since that wouldn&apost
happen, the expected page wouldn&apost load. The first place to look into
then is the web process and to try to understand what is preventing
the web extension from loading. Enter here, our good friend GDB, with
less than spectacular results thanks to stripped libraries.
#0 0x7500ab9c in poll () from target:/lib/libc.so.6
#1 0x73c08c0c in ?? () from target:/usr/lib/libEGL.so.1
#2 0x73c08d2c in ?? () from target:/usr/lib/libEGL.so.1
#3 0x73c08e0c in ?? () from target:/usr/lib/libEGL.so.1
#4 0x73bold6a8 in ?? () from target:/usr/lib/libEGL.so.1
#5 0x75f84208 in ?? () from target:/usr/lib/libWPEWebKit-1.0.so.2
#6 0x75fa0b7e in ?? () from target:/usr/lib/libWPEWebKit-1.0.so.2
#7 0x7561eda2 in ?? () from target:/usr/lib/libWPEWebKit-1.0.so.2
#8 0x755a176a in ?? () from target:/usr/lib/libWPEWebKit-1.0.so.2
#9 0x753cd842 in ?? () from target:/usr/lib/libWPEWebKit-1.0.so.2
#10 0x75451660 in ?? () from target:/usr/lib/libWPEWebKit-1.0.so.2
#11 0x75452882 in ?? () from target:/usr/lib/libWPEWebKit-1.0.so.2
#12 0x75452fa8 in ?? () from target:/usr/lib/libWPEWebKit-1.0.so.2
#13 0x76b1de62 in ?? () from target:/usr/lib/libWPEWebKit-1.0.so.2
#14 0x76b5a970 in ?? () from target:/usr/lib/libWPEWebKit-1.0.so.2
#15 0x74bee44c in g_main_context_dispatch () from target:/usr/lib/libglib-2.0.so.0
#16 0x74bee808 in ?? () from target:/usr/lib/libglib-2.0.so.0
#17 0x74beeba8 in g_main_loop_run () from target:/usr/lib/libglib-2.0.so.0
#18 0x76b5b11c in ?? () from target:/usr/lib/libWPEWebKit-1.0.so.2
#19 0x75622338 in ?? () from target:/usr/lib/libWPEWebKit-1.0.so.2
#20 0x74f59b58 in __libc_start_main () from target:/lib/libc.so.6
#21 0x0045d8d0 in _start ()
From all threads in the web process, after much tinkering around it
slowly became clear that one of the places to look into is
that poll()
call. I will spare you the details related to what other threads were
doing, suffice to say that whenever the browser would hit the bug,
there was a similar stacktrace in one thread, going
through libEGL to a
call to poll() on top of the stack, that would never
return. Unfortunately, a stripped EGL driver coming from a proprietary
graphics vendor was a bit of a showstopper, as it was the inability to
have proper debugging symbols running inside the device (did you know
that a non-stripped WebKit library binary with debugging symbols can
easily get GDB and your device out of memory?). The best one could do
to improve that was to use the
gcore
feature in GDB, and extract a core from the device for post-mortem
analysis. But for some reason, such a stacktrace wouldn&apost give
anything interesting below the poll() call to understand
what&aposs being polled here. Did I say this was tricky?
What polls?
Because WebKit is a multiprocess web engine, having system calls
that signal, read, and write in sockets communicating with other
processes is an everyday thing. Not knowing what a poll()
call is doing and who is it that it&aposs trying to listen to, not
very good. Because the call is happening under the EGL library, one
can presume that it&aposs graphics related, but there are still
different possibilities, so trying to find out what is this polling is
a good idea.
A trick I learned while debugging this is that, in absence of
debugging symbols that would give a straightforward look into
variables and parameters, one can examine the CPU registers and try to
figure out from them what the parameters to function calls are. Let&aposs
do that with poll(). First, its signature.
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
Now, let's examine the registers.
(gdb) f 0
#0 0x7500ab9c in poll () from target:/lib/libc.so.6
(gdb) info registers
r0 0x7ea55e58 2124766808
r1 0x1 1
r2 0x64 100
r3 0x0 0
r4 0x0 0
Registers r0, r1, and r2
contain poll()&aposs three
parameters. Because r1 is 1, we know that there is only
one file descriptor being polled. fds is a pointer to an
array with one element then. Where is that first element? Well, right
there, in the memory pointed to directly by
r0. What does struct pollfd look like?
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};
What we are interested in here is the contents of fd,
the file descriptor that is being polled. Memory alignment is again in
our side, we don&apost need any pointer arithmetic here. We can
inspect directly the register r0 and find out what the
value of fd is.
(gdb) print *0x7ea55e58
$3 = 8
So we now know that the EGL library is polling the file descriptor
with an identifier of 8. But where is this file descriptor coming
from? What is on the other end? The /proc file system can
be helpful here.
# pidof WPEWebProcess
1944 1196
# ls -lh /proc/1944/fd/8
lrwx------ 1 x x 64 Oct 22 13:59 /proc/1944/fd/8 -> socket:[32166]
So we have a socket. What else can we find out about it? Turns out,
not much without
the unix_diag
kernel module, which was not available in our device. But we are
slowly getting closer. Time to call another good friend.
Where GDB fails, printf() triumphs
Something I have learned from many years working with a project as
large as WebKit, is that debugging symbols can be very difficult to
work with. To begin with, it takes ages to build WebKit with them.
When cross-compiling, it&aposs even worse. And then, very often the
target device doesn&apost even have enough memory to load the symbols
when debugging. So they can be pretty useless. It&aposs then when
just
using fprintf()
and logging useful information can simplify things. Since we know that
it&aposs at some point during initialization of the web process that
we end up stuck, and we also know that we&aposre polling a file
descriptor, let&aposs find some early calls in the code of the web
process and add some
fprintf() calls with a bit of information, specially in
those that might have something to do with EGL. What can we find out
now?
Oct 19 10:13:27.700335 WPEWebProcess[92]: Starting
Oct 19 10:13:27.720575 WPEWebProcess[92]: Initializing WebProcess platform.
Oct 19 10:13:27.727850 WPEWebProcess[92]: wpe_loader_init() done.
Oct 19 10:13:27.729054 WPEWebProcess[92]: Initializing PlatformDisplayLibWPE (hostFD: 8).
Oct 19 10:13:27.730166 WPEWebProcess[92]: egl backend created.
Oct 19 10:13:27.741556 WPEWebProcess[92]: got native display.
Oct 19 10:13:27.742565 WPEWebProcess[92]: initializeEGLDisplay() starting.
Two interesting findings from the fprintf()-powered
logging here: first, it seems that file descriptor 8 is one known to
libwpe
(the general-purpose library that powers the WPE WebKit port). Second,
that the last EGL API call right before the web process hangs
on poll() is a call
to eglInitialize(). fprintf(),
thanks for your service.
Number 8
We now know that the file descriptor 8 is coming from WPE and is
not internal to the EGL library. libwpe gets this file descriptor from
the UI process,
as one
of the many creation parameters that are passed via IPC to the
nascent process in order to initialize it. Turns out that this file
descriptor in particular, the so-called host client file descriptor,
is the one that the freedesktop backend of libWPE, from here onwards
WPEBackend-fdo,
creates when a new client is set to connect to its Wayland display. In
a nutshell, in presence of a new client, a Wayland display is supposed
to create a pair of connected sockets, create a new client on the
Display-side, give it one of the file descriptors, and pass the other
one to the client process. Because this will be useful later on,
let&aposs see how is
that currently
implemented in WPEBackend-fdo.
int pair[2];
if (socketpair(AF_UNIX, SOCK_STREAM | SOCK_CLOEXEC, 0, pair) 0)
return -1;
int clientFd = dup(pair[1]);
close(pair[1]);
wl_client_create(m_display, pair[0]);
The file descriptor we are tracking down is the client file
descriptor, clientFd. So we now know what&aposs going on in this socket:
Wayland-specific communication. Let&aposs enable Wayland debugging next,
by running all relevant process with WAYLAND_DEBUG=1. We&aposll get back
to that code fragment later on.
A Heisenbug is a Heisenbug is a Heisenbug
Turns out that enabling Wayland debugging output for a few
processes is enough to alter the state of the system in such a way
that the bug does not happen at all when doing manual
testing. Thankfully the CI&aposs reproducibility is much higher, so
after waiting overnight for the CI to continuously run until it hit
the bug, we have logs. What do the logs say?
WPEWebProcess[41]: initializeEGLDisplay() starting.
-> wl_display@1.get_registry(new id wl_registry@2)
-> wl_display@1.sync(new id wl_callback@3)
So the EGL library is trying to fetch the Wayland
registry and it&aposs doing a wl_display_sync() call
afterwards, which will block until the server responds. That&aposs
where the blocking poll() call comes from. So, it turns
out, the problem is not necessarily on this end of the Wayland socket,
but perhaps on the other side, that is, in the so-called UI process
(the main browser process). Why is the Wayland display not
replying?
The loop
Something that is worth mentioning before we move on is how the
WPEBackend-fdo Wayland display integrates with the system. This
display is a nested display, with each web view a client, while it is
itself a client of the system&aposs Wayland display. This can be a bit
confusing if you&aposre not very familiar with how Wayland works, but
fortunately there is
good
documentation about Wayland elsewhere.
The way that the Wayland display in the UI process of a WPEWebKit
browser is integrated with the rest of the program, when it uses
WPEBackend-fdo, is through the
GLib
main event loop. Wayland itself has an event loop implementation
for servers, but for a GLib-powered application it can be useful to
use GLib&aposs and integrate Wayland&aposs event processing with the different
stages of the GLib main loop. That is precisely how WPEBackend-fdo is
handling its clients&apos events. As discussed earlier, when a new client
is created a pair of connected sockets are created and one end is
given to Wayland to control communication with the
client. GSourceFunc
functions are used to integrate Wayland with the application main
loop. In these functions, we make sure that whenever there are pending
messages to be sent to clients, those are sent, and whenever any of
the client sockets has pending data to be read, Wayland reads from
them, and to dispatch the events that might be necessary in response
to the incoming data. And here is where things start getting really
strange, because after doing a bit of
fprintf()-powered debugging inside the Wayland-GSourceFuncs functions,
it became clear that the Wayland events from the clients were never
dispatched, because the dispatch()GSourceFunc was not being called,
as if there was nothing coming from any Wayland client. But how is
that possible, if we already know that the web process client is
actually trying to get the Wayland registry?
To move forward, one needs to understand how the GLib main loop
works, in particular, with Unix file descriptor sources. A very brief
summary of this is that, during an iteration of the main loop, GLib
will poll file descriptors to see if there are any interesting events
to be reported back to their respective sources, in which case the
sources will decide whether to trigger the dispatch()
phase. A simple source might decide in its dispatch()
method to directly read or write from/to the file descriptor; a
Wayland display source (as in our case), will
call wl_event_loop_dispatch() to do this for us.
However, if the source doesn&apost find any interesting events, or if
the source decides that it doesn&apost want to handle them,
the dispatch() invocation will not happen. More on the
GLib main event loop in
its API
documentation.
So it seems that for some reason the dispatch() method is not being
called. Does that mean that there are no interesting events to read
from? Let&aposs find out.
System call tracing
Here we resort to another helpful
tool, strace. With strace
we can try to figure out what is happening when the main loop polls
file descriptors. The strace output is huge (because it
takes easily over a hundred attempts to reproduce this), but we know
already some of the calls that involve file descriptors from the code
we looked at above, when the client is created. So we can use those
calls as a starting point in when searching through the several MBs of
logs. Fast-forward to the relevant logs.
What we see there is, first, WPEBackend-fdo creating a new socket
pair (128, 130) and then, when file descriptor 130 is passed to
wl_client_create() to
create a new client, Wayland adds that file descriptor to its
epoll() instance
for monitoring clients, which is referred to by file descriptor 34. This way, whenever there are
events in file descriptor 130, we will hear about them in file descriptor 34.
So what we would expect to see next is that, after the web process
is spawned, when a Wayland client is created using the passed file
descriptor and the EGL driver requests the Wayland registry from the
display, there should be a POLLIN event coming in file
descriptor 34 and, if the dispatch() call for the source
was called,
a epoll_wait()
call on it, as that is
what wl_event_loop_dispatch()
would do when called from the source&aposs dispatch()
method. But what do we have instead?
strace can be a bit cryptic, so let&aposs explain
those two function calls. The first one is a poll in a series of file
descriptors (including 30 and 34) for POLLIN events. The
return value of that call tells us that there is a POLLIN
event in file descriptor 34 (the Wayland display epoll()
instance for clients). But unintuitively, the call right after is
trying to read a message from socket 30 instead, which we know
doesn&apost have any pending data at the moment, and consequently
returns an error value with an errno
of EAGAIN (Resource temporarily unavailable).
Why is the GLib main loop triggering a read from 30 instead of 34?
And who is 30?
We can answer the latter question first. Breaking on a running UI
process instance at the right time shows who is reading from
the file descriptor 30:
#1 0x70ae1394 in wl_os_recvmsg_cloexec (sockfd=30, msg=msg@entry=0x700fea54, flags=flags@entry=64)
#2 0x70adf644 in wl_connection_read (connection=0x6f70b7e8)
#3 0x70ade70c in read_events (display=0x6f709c90)
#4 wl_display_read_events (display=0x6f709c90)
#5 0x70277d98 in pwl_source_check (source=0x6f71cb80)
#6 0x743f2140 in g_main_context_check (context=context@entry=0x2111978, max_priority=, fds=fds@entry=0x6165f718, n_fds=n_fds@entry=4)
#7 0x743f277c in g_main_context_iterate (context=0x2111978, block=block@entry=1, dispatch=dispatch@entry=1, self=)
#8 0x743f2ba8 in g_main_loop_run (loop=0x20ece40)
#9 0x00537b38 in ?? ()
So it&aposs also Wayland, but on a different level. This
is the Wayland client source (remember that the browser is also a
Wayland client?), which is installed
by cog (a thin browser
layer on top of WPE WebKit that makes writing browsers easier to do)
to process, among others, input events coming from the parent Wayland
display. Looking
at the cog code, we can see that the
wl_display_read_events()
call happens only if GLib reports that there is
a G_IO_IN
(POLLIN) event in its file descriptor, but we already
know that this is not the case, as per the strace
output. So at this point we know that there are two things here that
are not right:
A FD source with a G_IO_IN condition is not being dispatched.
A FD source without a G_IO_IN condition is being dispatched.
Someone here is not telling the truth, and as a result the main loop
is dispatching the wrong sources.
The loop (part II)
It is at this point that it would be a good idea to look at what
exactly the GLib main loop is doing internally in each of its stages
and how it tracks the sources and file descriptors that are polled and
that need to be processed. Fortunately, debugging symbols for GLib are
very small, so debugging this step by step inside the device is rather
easy.
Let&aposs look at how the main loop decides which sources
to dispatch, since for some reason it&aposs dispatching the wrong ones.
Dispatching happens in
the g_main_dispatch()
method. This method goes over a list of pending source dispatches and
after a few checks and setting the stage, the dispatch method for the
source gets called. How is a source set as having a pending dispatch?
This happens in
g_main_context_check(),
where the main loop checks the results of the polling done in this
iteration and runs the check() method for sources that
are not ready yet so that they can decide whether they are ready to be
dispatched or not. Breaking into the Wayland display source, I know
that
the check()
method is called. How does this method decide to be dispatched or
not?
In this lambda function we&aposre returning TRUE or
FALSE, depending on whether the revents
field in
the GPollFD
structure have been filled during the polling stage of this iteration
of the loop. A return value of TRUE indicates the main
loop that we want our source to be dispatched. From
the strace output, we know that there is a
POLLIN (or G_IO_IN) condition, but we also know that the main loop is
not dispatching it. So let&aposs look at what&aposs in this GPollFD structure.
For this, let&aposs go back to g_main_context_check() and inspect the array
of GPollFD structures that it received when called. What do we find?
That&aposs the result of the poll() call! So far so good. Now the method
is supposed to update the polling records it keeps and it uses when
calling each of the sources check() functions. What do these records
hold?
We&aposre not interested in the first record quite yet, but clearly
there&aposs something odd here. The polling records are showing a
different value in the revent fields for both 30 and 34. Are these
records updated correctly? Let&aposs look at the algorithm that is doing
this update, because it will be relevant later on.
pollrec = context->poll_records;
i = 0;
while (pollrec && i n_fds)
{
while (pollrec && pollrec->fd->fd == fds[i].fd)
{
if (pollrec->priority = max_priority)
{
pollrec->fd->revents =
fds[i].revents & (pollrec->fd->events | G_IO_ERR | G_IO_HUP | G_IO_NVAL);
}
pollrec = pollrec->next;
}
i++;
}
In simple words, what this algorithm is doing is to traverse
simultaneously the polling records and the GPollFD array,
updating the polling records revents with the results of
polling. From
reading how
the pollrec linked list is built internally, it&aposs
possible to see that it&aposs purposely sorted by increasing file
descriptor identifier value. So the first item in the list will have
the record for the lowest file descriptor identifier, and so on. The
GPollFD array is also built in this way, allowing for a
nice optimization: if more than one polling record – that is, more
than one polling source – needs to poll the same file descriptor,
this can be done at once. This is why this otherwise O(n^2) nested
loop can actually be reduced to linear time.
One thing stands out here though: the linked list is only advanced
when we find a match. Does this mean that we always have a match
between polling records and the file descriptors that have just been
polled? To answer that question we need to check how is the array of
GPollFD structures
filled. This
is done in g_main_context_query(), as we hinted
before. I&aposll spare you the details, and just focus on what seems
relevant here: when is a poll record not used to fill
a GPollFD?
Interesting! If a polling record belongs to a source whose priority
is lower than the maximum priority that the current iteration is
going to process, the polling record is skipped. Why is this?
In simple terms, this happens because each iteration of the main
loop finds out the highest priority between the sources that are ready
in the prepare() stage, before polling, and then only
those file descriptor sources with at least such a a priority are
polled. The idea behind this is to make sure that high-priority
sources are processed first, and that no file descriptor sources with
lower priority are polled in vain, as they shouldn&apost be
dispatched in the current iteration.
GDB tells me that the maximum priority in this iteration is
-60. From an earlier GDB output, we also know that there&aposs a
source for a file descriptor 19 with a priority 0.
Since 19 is lower than 30 and 34, we know that this record is
before theirs in the linked list (and so it happens, it&aposs the
first one in the list too). But we know that, because its priority is
0, it is too low to be added to the file descriptor array to be
polled. Let&aposs look at the loop again.
pollrec = context->poll_records;
i = 0;
while (pollrec && i n_fds)
{
while (pollrec && pollrec->fd->fd == fds[i].fd)
{
if (pollrec->priority = max_priority)
{
pollrec->fd->revents =
fds[i].revents & (pollrec->fd->events | G_IO_ERR | G_IO_HUP | G_IO_NVAL);
}
pollrec = pollrec->next;
}
i++;
}
The first polling record was skipped during the update of
the GPollFD array, so the condition pollrec
&& pollrec->fd->fd == fds[i].fd is never going to
be satisfied, because 19 is not in the array. The
innermost while() is not entered, and as such
the pollrec list pointer never moves forward to the next
record. So no polling record is updated here, even if we have
updated revent information from the polling results.
What happens next should be easy to see. The check()
method for all polled sources are called with
outdated revents. In the case of the source
for file descriptor 30, we wrongly tell it there&aposs a
G_IO_IN condition, so it asks the main loop to call
dispatch it triggering a a wl_connection_read() call in a
socket with no incoming data. For the source with file descriptor 34,
we tell it that there&aposs no incoming data and
its dispatch() method is not invoked, even when on the
other side of the socket we have a client waiting for data to come and
blocking in the meantime. This explains what we see in
the strace output above. If the source with file
descriptor 19 continues to be ready and with its priority unchanged,
then this situation repeats in every further iteration of the main
loop, leading to a hang in the web process that is forever waiting
that the UI process reads its socket pipe.
The bug – explained
I have been using GLib for a very long time, and I have only fixed
a couple of minor bugs in it over the years. Very few actually,
which is why it was very difficult for me to come to accept that I
had found a bug in one of the most reliable and complex parts of the
library. Impostor syndrome is a thing and it really gets in the way.
But in a nutshell, the bug in the GLib main loop is that the very
clever linear update of registers is missing something very important:
it should skip to the first polling record matching before attempting
to update its revents. Without this, in the presence of a
file descriptor source with the lowest file descriptor identifier and
also a lower priority than the cutting priority in the current main
loop iteration, revents in the polling registers are not
updated and therefore the wrong sources can be dispatched. The
simplest patch to avoid this, would look as follows.
i = 0;
while (pollrec && i n_fds)
{
+ while (pollrec && pollrec->fd->fd != fds[i].fd)
+ pollrec = pollrec->next;
+
while (pollrec && pollrec->fd->fd == fds[i].fd)
{
if (pollrec->priority = max_priority)
Once we find the first matching record, let&aposs update all consecutive
records that also match and need an update, then let&aposs skip to the
next record, rinse and repeat. With this two-line patch, the web
process was finally unlocked, the EGL display initialized properly,
the web extension and the web page were loaded, CI tests starting
passing again, and this exhausted developer could finally put his mind
to rest.
A complete
patch, including improvements to the code comments around this
fascinating part of GLib and also a minimal test case reproducing the
bug have already been reviewed by the GLib maintainers and merged to
both stable and development branches. I expect that at
least some GLib sources will start being called in a
different (but correct) order from now on, so keep an eye on your
GLib sources. :-)
Standing on the shoulders of giants
At this point I should acknowledge that without the support from my
colleagues in the WebKit team in Igalia, getting to the bottom of this
problem would have probably been much harder and perhaps my sanity
would have been at stake. I want to
thank Adrián
and &Zcaronan for
their input on Wayland, debugging techniques, and for allowing me to
bounce back and forth ideas and findings as I went deeper into this
rabbit hole, helping me to step out of dead-ends, reminding me to use
tools out of my everyday box, and ultimately, to be brave enough to
doubt GLib&aposs correctness, something that much more often than not I
take for granted.
Thanks also to Philip
and Sebastian for their
feedback and prompt code review!
It’s that time of year again: a new GNOME release, and with it, a new Epiphany. The pace of Epiphany development has increased significantly over the last few years thanks to an increase in the number of active contributors. Most notably, Jan-Michael Brummer has solved dozens of bugs and landed many new enhancements, Alexander Mikhaylenko has polished numerous rough edges throughout the browser, and Andrei Lisita has landed several significant improvements to various Epiphany dialogs. That doesn’t count the work that Igalia is doing to maintain WebKitGTK, the WPE graphics stack, and libsoup, all of which is essential to delivering quality Epiphany releases, nor the work of the GNOME localization teams to translate it to your native language. Even if Epiphany itself is only the topmost layer of this technology stack, having more developers working on Epiphany itself allows us to deliver increased polish throughout the user interface layer, and I’m pretty happy with the result. Let’s take a look at what’s new.
Intelligent Tracking Prevention
Intelligent Tracking Prevention (ITP) is the headline feature of this release. Safari has had ITP for several years now, so if you’re familiar with how ITP works to prevent cross-site tracking on macOS or iOS, then you already know what to expect here. If you’re more familiar with Firefox’s Enhanced Tracking Protection, or Chrome’s nothing (crickets: chirp, chirp!), then WebKit’s ITP is a little different from what you’re used to. ITP relies on heuristics that apply the same to all domains, so there are no blocklists of naughty domains that should be targeted for content blocking like you see in Firefox. Instead, a set of innovative restrictions is applied globally to all web content, and a separate set of stricter restrictions is applied to domains classified as “prevalent” based on your browsing history. Domains are classified as prevalent if ITP decides the domain is capable of tracking your browsing across the web, or non-prevalent otherwise. (The public-friendly terminology for this is “Classification as Having Cross-Site Tracking Capabilities,” but that is a mouthful, so I’ll stick with “prevalent.” It makes sense: domains that are common across many websites can track you across many websites, and domains that are not common cannot.)
ITP is enabled by default in Epiphany 3.38, as it has been for several years now in Safari, because otherwise only a small minority of users would turn it on. ITP protections are designed to be effective without breaking too many websites, so it’s fairly safe to enable by default. (You may encounter a few broken websites that have not been updated to use the Storage Access API to store third-party cookies. If so, you can choose to turn off ITP in the preferences dialog.)
For a detailed discussion covering ITP’s tracking mitigations, see Tracking Prevention in WebKit. I’m not an expert myself, but the short version is this: full third-party cookie blocking across all websites (to store a third-party cookie, websites must use the Storage Access API to prompt the user for permission); cookie-blocking latch mode (“once a request is blocked from using cookies, all redirects of that request are also blocked from using cookies”); downgraded third-party referrers (“all third-party referrers are downgraded to their origins by default”) to avoid exposing the path component of the URL in the referrer; blocked third-party HSTS (“HSTS […] can only be set by the first-party website […]”) to stop abuse by tracker scripts; detection of cross-site tracking via link decoration and 24-hour expiration time for all cookies created by JavaScript on the landing page when detected; a 7-day expiration time for all other cookies created by JavaScript (yes, this applies to first-party cookies); and a 7-day extendable lifetime for all other script-writable storage, extended whenever the user interacts with the website (necessary because tracking companies began using first-party scripts to evade the above restrictions). Additionally, for prevalent domains only, domains engaging in bounce tracking may have cookies forced to SameSite=strict, and Verified Partitioned Cache is enabled (cached resources are re-downloaded after seven days and deleted if they fail certain privacy tests). Whew!
WebKit has many additional privacy protections not tied to the ITP setting and therefore not discussed here — did you know that cached resources are partioned based on the first-party domain? — and there’s more that’s not very well documented which I don’t understand and haven’t mentioned (tracker collusion!), but that should give you the general idea of how sophisticated this is relative to, say, Chrome (chirp!). Thanks to John Wilander from Apple for his work developing and maintaining ITP, and to Carlos Garcia for getting it working on Linux. If you’re interested in the full history of how ITP has evolved over the years to respond to the changing threat landscape (e.g. tracking prevention tracking), see John’s WebKit blog posts. You might also be interested in WebKit’s Tracking Prevention Policy, which I believe is the strictest anti-tracking stance of any major web engine. TL;DR: “we treat circumvention of shipping anti-tracking measures with the same seriousness as exploitation of security vulnerabilities. If a party attempts to circumvent our tracking prevention methods, we may add additional restrictions without prior notice.” No exceptions.
Updated Website Data Preferences
As part of the work on ITP, you’ll notice that Epiphany’s cookie storage preferences have changed a bit. Since ITP enforces full third-party cookie blocking, it no longer makes sense to have a separate cookie storage preference for that, so I replaced the old tri-state cookie storage setting (always accept cookies, block third-party cookies, block all cookies) with two switches: one to toggle ITP, and one to toggle all website data storage.
Previously, it was only possible to block cookies, but this new setting will additionally block localStorage and IndexedDB, web features that allow websites to store arbitrary data in your browser, similar to cookies. It doesn’t really make much sense to block cookies but allow other types of data storage, so the new preferences should better enforce the user’s intent behind disabling cookies. (This preference does not yet block media keys, service workers, or legacy offline web application cache, but it probably should.) I don’t really recommend disabling website data storage, since it will cause compatibility issues on many websites, but this option is there for those who want it. Disabling ITP is also not something I want to recommend, but it might be necessary to access certain broken websites that have not yet been updated to use the Storage Access API.
Accordingly, Andrei has removed the old cookies dialog and moved cookie management into the Clear Personal Data dialog, which is a better place because anyone clearing cookies for a particular website is likely to also want to clear other personal data. (If you want to delete a website’s cookies, then you probably don’t want to leave its SQL databases intact, right?) He had to remove the ability to clear data from a particular point in time, because WebKit doesn’t support this operation for cookies, but that function is probably rarely-used and I think the benefit of the change should outweigh the cost. (We could bring it back in the future if somebody wants to try implementing that feature in WebKit, but I suspect not many users will notice.) Treating cookies as separate and different from other forms of website data storage no longer makes sense in 2020, and it’s good to have finally moved on from that antiquated practice.
New HTML Theme
Carlos Garcia has added a new Adwaita-based HTML theme to WebKitGTK 2.30, and removed support for rendering HTML elements using the GTK theme (except for scrollbars). Trying to use the GTK theme to render web content was fragile and caused many web compatibility problems that nobody ever managed to solve. The GTK developers were never very fond of us doing this in the first place, and the foreign drawing API required to do so has been removed from GTK 4, so this was also good preparation for getting WebKitGTK ready for GTK 4. Carlos’s new theme is similar to Adwaita, but gradients have been toned down or removed in order to give a flatter, neutral look that should blend in nicely with all pages while still feeling modern.
This should be a fairly minor style change for Adwaita users, but a very large change for anyone using custom themes. I don’t expect everyone will be happy, but please trust that this will at least result in better web compatibility and fewer tricky theme-related bug reports.
Left: Adwaita GTK theme controls rendered by WebKitGTK 2.28. Right: hardcoded Adwaita-based HTML theme with toned down gradients.
Although scrollbars will still use the GTK theme as of WebKitGTK 2.30, that will no longer be possible to do in GTK 4, so themed scrollbars are almost certain to be removed in the future. That will be a noticeable disappointment in every app that uses WebKitGTK, but I don’t see any likely solution to this.
Media Permissions
Jan-Michael added new API in WebKitGTK 2.30 to allow muting individual browser tabs, and hooked it up in Epiphany. This is good when you want to silence just one annoying tab without silencing everything.
Meanwhile, Charlie Turner added WebKitGTK API for managing autoplay policies. Videos with sound are now blocked from autoplaying by default, while videos with no sound are still allowed. Charlie hooked this up to Epiphany’s existing permission manager popover, so you can change the behavior for websites you care about without affecting other websites.
Configure your preferred media autoplay policy for a website near you today!
Improved Dialogs
In addition to his work on the Clear Data dialog, Andrei has also implemented many improvements and squashed bugs throughout each view of the preferences dialog, the passwords dialog, and the history dialog, and refactored the code to be much more maintainable. Head over to his blog to learn more about his accomplishments. (Thanks to Google for sponsoring Andrei’s work via Google Summer of Code, and to Alexander for help mentoring.)
Additionally, Adrien Plazas has ported the preferences dialog to use HdyPreferencesWindow, bringing a pretty major design change to the view switcher:
Left: Epiphany 3.36 preferences dialog. Right: Epiphany 3.38. Note the download settings are present in the left screenshot but missing from the right screenshot because the right window is using flatpak, and the download settings are unavailable in flatpak.
User Scripts
User scripts (like Greasemonkey) allow you to run custom JavaScript on websites. WebKit has long offered user script functionality alongside user CSS, but previous versions of Epiphany only exposed user CSS. Jan-Michael has added the ability to configure a user script as well. To enable, visit the Appearance tab in the preferences dialog (a somewhat odd place, but it really needs to be located next to user CSS due to the tight relationship there). Besides allowing you to do, well, basically anything, this also significantly enhances the usability of user CSS, since now you can apply certain styles only to particular websites. The UI is a little primitive — your script (like your CSS) has to be one file that will be run on every website, so don’t try to design a complex codebase using your user script — but you can use conditional statements to limit execution to specific websites as you please, so it should work fairly well for anyone who has need of it. I fully expect 99.9% of users will never touch user scripts or user styles, but it’s nice for power users to have these features available if needed.
HTTP Authentication Password Storage
Jan-Michael and Carlos Garcia have worked to ensure HTTP authentication passwords are now stored in Epiphany’s password manager rather than by WebKit, so they can now be viewed and deleted from Epiphany, which required some new WebKitGTK API to do properly. Unfortunately, WebKitGTK saves network passwords using the default network secret schema, meaning its passwords (saved by older versions of Epiphany) are all leaked: we have no way to know which application owns those passwords, so we don’t have any way to know which passwords were stored by WebKit and which can be safely managed by Epiphany going forward. Accordingly, all previously-stored HTTP authentication passwords are no longer accessible; you’ll have to use seahorse to look them up manually if you need to recover them. HTTP authentication is not very commonly-used nowadays except for internal corporate domains, so hopefully this one-time migration snafu will not be a major inconvenience to most users.
New Tab Animation
Jan-Michael has added a new animation when you open a new tab. If the newly-created tab is not visible in the tab bar, then the right arrow will flash to indicate success, letting you know that you actually managed to open the page. Opening tabs out of view happens too often currently, but at least it’s a nice improvement over not knowing whether you actually managed to open the tab or not. This will be improved further next year, because Alexander is working on a completely new tab widget to replace GtkNotebook.
New View Source Theme
Jim Mason changed view source mode to use a highlight.js theme designed to mimic Firefox’s syntax highlighting, and added dark mode support.
I added a new WebKitGTK 2.30 API to expose the paste as plaintext editor command, which was previously internal but fully-functional. I’ve hooked it up in Epiphany’s context menu as “Paste Text Only.” This is nice when you want to discard markup when pasting into a rich text editor (such as the WordPress editor I’m using to write this post).
Jan-Michael has implemented support for reordering pinned tabs. You can now drag to reorder pinned tabs any way you please, subject to the constraint that all pinned tabs stay left of all unpinned tabs.
Jan-Michael added a new import/export menu, and the bookmarks import/export features have moved there. He also added a new feature to import passwords from Chrome. Meanwhile, ignapk added support for importing bookmarks from HTML (compatible with Firefox).
Jan-Michael added a new preference to web apps to allow running them in the background. When enabled, closing the window will only hide the the window: everything will continue running. This is useful for mail apps, music players, and similar applications.
Continuing Jan-Michael’s list of accomplishments, he removed Epiphany’s previous hidden setting to set a mobile user agent header after discovering that it did not work properly, and replaced it by adding support in WebKitGTK 2.30 for automatically setting a mobile user agent header depending on the chassis type detected by logind. This results in a major user experience improvement when using Epiphany as a mobile browser. Beware: this functionality currently does not work in flatpak because it requires the creation of a new desktop portal.
Stephan Verbücheln has landed multiple fixes to improve display of favicons on hidpi displays.
Zach Harbort fixed a rounding error that caused the zoom level to display oddly when changing zoom levels.
Vanadiae landed some improvements to the search engine configuration dialog (with more to come) and helped investigate a crash that occurs when using the “Set as Wallpaper” function under Flatpak. The crash is pretty tricky, so we wound up disabling that function under Flatpak for now. He also updated screenshots throughout the user help.
Sabri Ünal continued his effort to document and standardize keyboard shortcuts throughout GNOME, adding a few missing shortcuts to the keyboard shortcuts dialog.
Encrypted Media Extensions (a.k.a. EME) is the W3C standard for encrypted media in the web. This way, media providers such as Hulu, Netflix, HBO, Disney+, Prime Video, etc. can provide their contents with a reasonable amount of confidence that it will make it very complicated for people to “save” their assets without their permission. Why do I use the word “serious” in the title? In WebKit there is already support for Clear Key, which is the W3C EME reference implementation but EME supports more encryption systems, even privative ones (I have my opinion about this, you can ask me privately). No service provider (that I know) supports Clear Key, they usually rely on Widevine, PlayReady or some other.
Three years ago, my colleague Žan Doberšek finished the implementation of what was going to be the shell of WebKit’s modern EME implementation, following latest W3C proposal. We implemented that downstream (at Web Platform for Embedded) as well using Thunder, which includes as a plugin a fork of what was Open Content Decryption Module (a.k.a. OpenCDM). The OpenCDM API changed quite a lot during this journey. It works well and there are millions of set-top-boxes using it currently.
The delta between downstream and the upstream GStreamer based WebKit ports was quite big, testing was difficult and syncing was not always easy, so we decided reverse the situation.
Our first step was done by my colleague Charlie Turner, who made Clear Key work upstream again while adapted some changes the Apple folks had done meanwhile. It was amazing to see Clear Key tests passing again and his work with the CDMProxy related classes was awesome. After having ClearKey working, I had to adapt them a bit to accomodate Thunder. To explain a bit about the WebKit EME architecture, I must say that there are two layers. The first is the crossplatform one, which implements the W3C API (MediaKeys, MediaKeySession, CDM…). These classes rely on the platform ones (CDMPrivate, CDMInstance, CDMInstanceSession) to handle the platform management, message exchange, etc. which would be the second layer. Apple playback system is fully integrated with their DRM system so they don’t need anything else. We do because we need to integrate our own decryptors to defer to Thunder for decryption so in the GStreamer based ports we also need the CDMProxy related classes, which would be CDMProxy, CDMInstanceProxy, CDMInstanceSessionProxy… The last two extend CDMInstance and CDMInstanceSession respectively to be able to deal with the key management, that is abstracted to the KeyHandle and KeyStore.
Once the abstraction is there (let’s remember that the abstranction works both for Clear Key and Thunder), the Thunder implementation is quite simple, justgluing the CDMProxy, CDMInstanceProxy and CDMInstanceSessionProxy classes to the Thunder system and writing a GStreamer decryptor element for it. I might have made a mistake when selecting the files but considering Thunder classes + the GStreamer common decryptor code, cloc says it is just 1198 lines of platform code. I think it is pretty low for what it does. Apart from that, obviously, there are 5760 lines of crossplatform code.
To build and run all this you need to do several things:
Build the dependencies with WEBKIT_JHBUILD=1 JHBUILD_ENABLE_THUNDER="yes" to enable the old fashioned JHBuild build and force it to build the Thunder dependencies. All dependendies are on JHBuild, even Widevine is referenced but to download it you need the proper credentials as it is closed source.
Pass --thunder when calling build-webkit.sh.
Run MiniBrowser with WEBKIT_GST_EME_RANK_PRIORITY="Thunder" and pass parameters --enable-mediasource=TRUE --enable-encrypted-media=TRUE --autoplay-policy=allow. The autoplay policy is usually optional but in this case it is necessary for the YouTube TV tests. We need to give the Thunder decryptor a higher priority because of WebM, that does not specify a key system and without it the Clear Key one can be selected and fail. MP4 does not create trouble because the protection system is specified and the caps negotiation does its magic.
As you could have guessed if you have a closer look at the GStreamer JHBuild moduleset, you’ll see that only Widevine is supported. To support more, you only have to make them build in the Thunder ecosystem and add them to CDMFactoryThunder::supportedKeySystems.
When I coded this, all YouTube TV tests for Widevine were green in the desktop. At the moment of writing this post they aren’t because of some problem with the Widevine installation that will be sorted quickly, I hope.
Graphics overlays are everywhere nowadays in the live video broadcasting
industry. In this post I introduce a new demo relying on GStreamer and
WPEWebKit to deliver low-latency web-augmented video broadcasts.
Readers of this blog might remember a few posts about WPEWebKit and a
GStreamer element we at Igalia worked on …
After the latest migration of WebKitGTK test bots to use the new SDK based on Flatpak, the old development environment based on jhbuild became deprecated. It can still be used with export WEBKIT_JHBUILD=1, though, but support for this way of working will gradually fade out.
My mail goal was to have a comfortable IDE that follows standard GUI conventions (that is, no emacs nor vim) and has code indexing features that (more or less) work with the WebKit codebase. Qt Creator was providing all that to me in the old chroot environment thanks to some configuration tricks by Alicia, so it should be good for the new one.
The WebKit source code can be downloaded as always using git:
git clone git.webkit.org/WebKit.git
It’s useful to add WebKit/Tools/Scripts and WebKit/Tools/gtk to your PATH, as well as any other custom tools you may have. You can customize your $HOME/.bashrc for that, but I prefer to have an env.sh environment script to be sourced from the current shell when I want to enter into my development environment (by running webkit). If you’re going to use it too, remember to adjust to your needs the paths used there.
Even if you have a pretty recent distro, it’s still interesting to have the latests Flatpak tools. Add Alex Larsson’s PPA to your apt sources:
sudo add-apt-repository ppa:alexlarsson/flatpak
In order to ensure that your distro has all the packages that webkit requires and to install the WebKit SDK, you have to run these commands (I omit the full path). Downloading the Flatpak modules will take a while, but at least you won’t need to build everything from scratch. You will need to do this again from time to time, every time the WebKit base dependencies change:
install-dependencies update-webkitgtk-libs
Now just build WebKit and check that MiniBrowser works:
This build process should have generated a WebKit/WebKitBuild/GTK/Release/compile_commands.json file with the right parameters and paths used to build each compilation unit in the project. This file can be leveraged by Qt Creator to get the right include paths and build flags after some preprocessing to translate the paths that make sense from inside Flatpak to paths that make sense from the perspective of your main distro. I wrote compile_commands.sh to take care of those transformations. It can be run manually or automatically when calling go full-rebuild or go update.
With all the needed pieces in place, it’s time to import the project into Qt Creator. To do that, click File → Open File or Project, and then select the compile_commands.json file that compile_commands.sh should have generated in the WebKit main directory.
Now make sure that Qt Creator has the right plugins enabled in Help → About Plugins…. Specifically: GenericProjectManager, ClangCodeModel, ClassView, CppEditor, CppTools, ClangTools, TextEditor and LanguageClient (more on that later).
With this setup, after a brief initial indexing time, you will have support for features like Switch header/source (F4), Follow symbol under cursor (F2), shading of disabled if-endif blocks, auto variable type resolving and code outline. There are some oddities of compile_commands.json based projects, though. There are no compilation units in that file for header files, so indexing features for them only work sometimes. For instance, you can switch from a method implementation in the cpp file to its declaration in the header file, but not the opposite. Also, you won’t see all the source files under the Projects view, only the compilation units, which are often just a bunch of UnifiedSource-*.cpp files. That’s why I prefer to use the File System view.
Additional features like Open Type Hierarchy (Ctrl+Shift+T) and Find References to Symbol Under Cursor (Ctrl+Shift+U) are only available when a Language Client for Language Server Protocol is configured. Fortunately, the new WebKit SDK comes with the ccls C/C++/Objective-C language server included. To configure it, open Tools → Options… → Language Client and add a new item with the following properties:
Some “LanguageClient ccls: Unexpectedly finished. Restarting in 5 seconds.” errors will appear in the General Messages panel after configuring the language client and every time you launch Qt Creator. It’s just ccls taking its time to index the whole source code. It’s “normal”, don’t worry about it. Things will get stable and start to work after some minutes.
Due to the way the Locator file indexer works in Qt Creator, it can become confused, run out of memory and die if it finds cycles in the project file tree. This is common when using Flatpak and running the MiniBrowser or the tests, since /proc and other large filesystems are accessible from inside WebKit/WebKitBuild. To avoid that, open Tools → Options… → Environment → Locator and set Refresh interval to 0 min.
I also prefer to call my own custom build and run scripts (go and runtest.sh) instead of letting Qt Creator build the project with the default builders and mess everything. To do that, from the Projects mode (Ctrl+5), click on Build & Run → Desktop → Build and edit the build configuration to be like this:
Build directory: /home/enrique/work/webkit/WebKit
Add build step → Custom process step
Command: go (no absolute route because I have it in my PATH)
Arguments:
Working directory: /home/enrique/work/webkit/WebKit
Then, for Build & Run → Desktop → Run, use these options:
Deployment: No deploy steps
Run:
Run configuration: Custom Executable → Add
Executable: runtest.sh
Command line arguments:
Working directory:
With these configuration you can build the project with Ctrl+B and run it with Ctrl+R.
I think I’m not forgetting anything more regarding environment setup. With the instructions in this post you can end up with a pretty complete IDE. Here’s a screenshot of it working in its full glory:
Anyway, to be honest, nothing will ever reach the level of code indexing features I got with Eclipse some years ago. I could find usages of a variable/attribute and know where it was being read, written or read-written. Unfortunately, that environment stopped working for me long ago, so Qt Creator has been the best I’ve managed to get for a while.
Properly configured web based indexers such as the Searchfox instance configured in Igalia can also be useful alternatives to a local setup, although they lack features such as type hierarchy.
I hope you’ve found this post useful in case you try to setup an environment similar to the one described here. Enjoy!
Last week I attended the Web Engines Hackfest. The
event was sponsored by Igalia (also hosting the event), Adobe and Collabora.
As usual I spent most of the time working on the WebKitGTK+ GStreamer
backend and Sebastian Dröge kindly joined and helped out quite a
bit, make sure to read …
Using videos in the <img> HTML tag can lead to more responsive web-page loads
in most cases. Colin Bendell blogged about this topic, make sure to read his
post on the cloudinary website. As it turns out, this feature has been
supported for more than 2 years in Safari, but …
Working on a web-engine often requires a complex build infrastructure. This post
documents our transition from JHBuild to Flatpak for the WebKitGTK and
WPEWebKit development builds.
For the last 10 years, WebKitGTK has been relying on a custom JHBuild
moduleset to handle its dependencies and (try to) ensure a reproducible …
When you connect to a Wi-Fi network, that network might block your access to the wider internet until you’ve signed into the network’s captive portal page. An untrusted network can disrupt your connection at any time by blocking secure requests and replacing the content of insecure requests with its login page. (Of course this can be done on wired networks as well, but in practice it mainly happens on Wi-Fi.) To detect a captive portal, NetworkManager sends a request to a special test address (e.g. http://fedoraproject.org/static/hotspot.txt) and checks to see whether it the content has been replaced. If so, GNOME Shell will open a little WebKitGTK browser window to display http://nmcheck.gnome.org, which, due to the captive portal, will be hijacked by your hotel or airport or whatever to display the portal login page. Rephrased in security lingo: an untrusted network may cause GNOME Shell to load arbitrary web content whenever it wants. If that doesn’t immediately sound dangerous to you, let’s ask me from four years ago why that might be bad:
Web engines are full of security vulnerabilities, like buffer overflows and use-after-frees. The details don’t matter; what’s important is that skilled attackers can turn these vulnerabilities into exploits, using carefully-crafted HTML to gain total control of your user account on your computer (or your phone). They can then install malware, read all the files in your home directory, use your computer in a botnet to attack websites, and do basically whatever they want with it.
If the web engine is sandboxed, then a second type of attack, called a sandbox escape, is needed. This makes it dramatically more difficult to exploit vulnerabilities.
The captive portal helper will pop up and load arbitrary web content without user interaction, so there’s nothing you as a user could possibly do about it. This makes it a tempting target for attackers, so we want to ensure that users are safe in the absence of a sandbox escape. Accordingly, beginning with GNOME 3.36, the captive portal helper is now sandboxed.
How did we do it? With basically one line of code (plus a check to ensure the WebKitGTK version is new enough). To sandbox any WebKitGTK app, just call webkit_web_context_set_sandbox_enabled(). Ta-da, your application is now magically secure!
No, really, that’s all you need to do. So if it’s that simple, why isn’t the sandbox enabled by default? It can break applications that use WebKitWebExtension to run custom code in the sandboxed web process, so you’ll need to test to ensure that your application still works properly after enabling the sandbox. (The WebKitGTK sandbox will become mandatory in the future when porting applications to GTK 4. That’s thinking far ahead, though, because GTK 4 isn’t supported yet at all.) You may need to use webkit_web_context_add_path_to_sandbox() to give your web extension access to directories that would otherwise be blocked by the sandbox.
The sandbox is critically important for web browsers and email clients, which are constantly displaying untrusted web content. But really, every app should enable it. Fix your apps! Then thank Patrick Griffis from Igalia for developing WebKitGTK’s sandbox, and the bubblewrap, Flatpak, and xdg-desktop-portal developers for providing the groundwork that makes it all possible.
Once upon a time, beginning with GNOME 3.14, Epiphany had supported displaying PDF documents via the Evince NPAPI browser plugin developed by Carlos Garcia Campos. Unfortunately, because NPAPI plugins have to use X11-specific APIs to draw web content, this didn’t suffice for very long. When GNOME switched to Wayland by default in GNOME 3.24 (yes, that was three years ago!), this functionality was left behind. Using an NPAPI plugin also meant the code was inherently unsandboxable and tied to a deprecated technology. Epiphany disabled support for NPAPI plugins by default in Epiphany 3.30, hiding the functionality behind a hidden setting, which has now finally been removed for Epiphany 3.36, killing off NPAPI for good.
Jan-Michael Brummer, who comaintains Epiphany with me, tried bringing back PDF support for Epiphany 3.34 using libevince, but eventually we decided to give up on this approach due to difficulty solving some user experience issues. Also, the rendering occurred in the unsandboxed UI process, which was again not good for security.
But PDF support is now back in Epiphany 3.36, and much better than before! Thanks to Jan-Michael, Epiphany now supports displaying PDFs using the amazing PDF.js. We are thankful for Mozilla’s work in developing PDF.js and open sourcing it for us to use. Viewing PDFs in Epiphany using PDF.js is more convenient than downloading them and opening them in Evince, and because the PDF is rendered in the sandboxed web process, using web technologies rather than poppler, it’s also approximately one bazillion times more secure.
Look, it’s a PDF!
One limitation of PDF.js is that it does not support forms. If you need to fill out PDF forms, you’ll need to download the PDF and open it in Evince, just as you would if using Firefox.
Dark Mode
Thanks to Carlos Garcia, it should finally be possible to use Epiphany with dark GTK themes. WebKitGTK has historically rendered HTML elements using the GTK theme, which has not been good for users of dark themes, which broke badly on many websites, usually due to dark text being drawn on dark backgrounds or various other problems with unexpected dark widgets. Since WebKitGTK 2.28, WebKit will try to manually change to a light GTK theme when it thinks a dark theme is in use, then use the light theme to render web content. (This work has actually been backported to WebKitGTK 2.26.4, so you don’t need to upgrade to WebKitGTK 2.28 to benefit, but the work landed very recently and we haven’t blogged about it yet.) Thanks to Cassidy James from elementary for providing example pages for testing dark mode behavior.
Broken dark mode support prior to WebKitGTK 2.26.4. Notice that the first two pages use dark color schemes when light color schemes are expected, and the dark blue links are hard to read over the dark gray background. Also notice that the text in the second image is unreadable.
Since WebKitGTK 2.26.4, dark mode works as it does in most other browsers. Websites that don’t support dark mode are light, and websites that do support dark mode are dark. Widgets themed using GTK are always light.
Since Carlos had already added support for the prefers-color-scheme media query last year, this now gets us up to dark mode parity with most browsers, except, notably, Safari. Unlike other browsers, Safari allows websites to opt-in to rendering dark system widgets, like WebKitGTK used to do before these changes. Whether to support this in WebKitGTK remains to-be-determined.
Process Swap on Navigation (PSON)
PSON, which debuted in Safari 13, is a major change in WebKit’s process model. PSON is the first component of site isolation, which Chrome has supported for some time, and which Firefox is currently working towards. If you care about web security, you should care a lot about site isolation, because the web browser community has arrived at a consensus that this is the best way to mitigate speculative execution attacks.
Nowadays, all modern web browsers use separate, sandboxed helper processes to render web content, ensuring that the main user interface process, which is unsandboxed, does not touch untrusted web content. Prior to 3.36, Epiphany already used a separate web process to display each browser tab (except for “related views,” where one tab opens another and gains scripting ability over the opened tab, subject to the Same Origin Policy). But in Epiphany 3.36, we now also have a separate web process per website. Each tab will swap between different web processes when navigating between different websites, to prevent any one web process from loading content from different websites.
To make these process swap navigations fast, a pool of prewarmed processes is used to hide the startup cost of launching a new process by ensuring the new process exists before it’s needed; otherwise, the overhead of launching a new web process to perform the navigation would become noticeable. And suspended processes live on after they’re no longer in use because they may be needed for back/forward navigations, which use WebKit’s page cache when possible. (In the page cache, pages are kept in memory indefinitely, to make back/forward navigations fast.)
Due to internal refactoring, PSON previously necessitated some API breakage in WebKitGTK 2.26 that affected Evolution and Geary: WebKitGTK 2.26 deprecated WebKit’s single web process model and required that all applications use one web process per web view, which Evolution and Geary were not, at the time, prepared to handle. We tried hard to avoid this, because we hate to make behavioral changes that break applications, but in this case we decided it was unavoidable. That was the status quo in 2.26, without PSON, which we disabled just before releasing 2.26 in order to limit application breakage to just Evolution and Geary. Now, in WebKitGTK 2.28, PSON is finally available for applications to use on an opt-in basis. (It will become mandatory in the future, for GTK 4 applications.) Epiphany 3.36 opts in. To make this work, Carlos Garcia designed new WebKitGTK APIs for cross-process communication, and used them to replace the private D-Bus server that Epiphany previously used for this purpose.
WebKit still has a long way to go to fully implement site isolation, but PSON is a major step down that road. Thanks to Brady Eidson and Chris Dumez from Apple for making this work, and to Carlos Garcia for handling most of the breakage (there was a lot). As with any major intrusive change of such magnitude, regressions are inevitable, so don’t hesitate to report issues on WebKit Bugzilla.
highlight.js
Once upon a time, WebKit had its own implementation for viewing page source, but this was removed from WebKit way back in 2014, in WebKitGTK 2.6. Ever since, Epiphany would open your default text editor, usually gedit, to display page source. Suffice to say that this was not a very satisfactory solution.
I finally managed to implement view source mode at the Epiphany level for Epiphany 3.30, but I had trouble making syntax highlighting work. I tried using various open source syntax highlighting libraries, but most are designed to highlight small amounts of code, not large web pages. The libraries I tried were not fast enough, so I gave up on syntax highlighting at the time.
Thanks to Jan-Michael, Epiphany 3.36 supports syntax highlighting using highlight.js, so we finally have view source mode working fully properly once again. It works much better than my failed attempts with different JS libraries. Please thank the highlight.js developers for maintaining this library, and for making it open source.
Colors!
Service Workers
Service workers are now available in WebKitGTK 2.28. Our friends at Apple had already implemented service worker support a couple years ago for Safari 11, but we were pretty slow in bringing this functionality to Linux. Finally, WebKitGTK should now be up to par with Safari in this regard.
Cookies!
Patrick Griffis has updated libsoup and WebKitGTK to support SameSite cookies. He’s also tightened up our cookie policy by implementing strict secure cookies, which prevents http:// pages from setting secure cookies (as they could overwrite secure cookies set by https:// pages).
Adaptive Design
As usual, there are more adaptive design improvements throughout the browser, to provide a better user experience on the Librem 5. There’s still more work to be done here, but Epiphany continues to provide the best user experience of any Linux browser at small screen sizes. Thanks to Adrien Plazas and Jan-Michael for their continued work on this.
As before, simply resize your browser window to see Epiphany dynamically transition between desktop mode and mobile mode.
elementary OS
With help from Alexander Mikhaylenko, we’ve also upstreamed many elementary OS design changes, which will be used when running under the Pantheon desktop (and not impact users on other desktops), so that the elementary developers don’t need to maintain their customizations as separate patches anymore. This will eliminate a few elementary-specific bugs, including some keyboard shortcuts that were previously broken only in elementary, and some odd tab bar behavior. Although Epiphany still doesn’t feel quite as native as an app designed just for elementary OS, it’s getting closer.
Epiphany 3.34
I failed to blog about Epiphany 3.34 when I released it last September. Hopefully you have updated to 3.34 already, and are already enjoying the two big features from this release: the new adblocker, and the bubblewrap sandbox.
The new adblocker is based on WebKit Content Blockers, which was developed by Apple several years ago. Adrian Perez developed new WebKitGTK API to expose this functionality, changed Epiphany to use it, and deleted Epiphany’s older resource-hungry adblocker that was originally copied from Midori. Previously, Epiphany kept a large GHashMap of compiled regexes in every web process, consuming a very significant amount of RAM for each process. It also took time to compile these regexes when launching each new web process. Now, the adblock filters are instead compiled into an efficient bytecode format that gets mmapped between all web processes to avoid excessive resource use. The bytecode is interpreted by WebKit itself, rather than by Epiphany’s web process extension (which Epiphany uses to execute custom code in WebKit’s web process), for greatly improved performance.
Lastly, Epiphany 3.34 enabled Patrick’s bubblewrap sandbox, which was added in WebKitGTK 2.26. Bubblewrap is an amazing sandboxing tool, already used effectively by flatpak and rpm-ostree, and I’m very pleased with Patrick’s decision to use it for WebKit as well. Because enabling the sandbox can break applications, it is currently opt-in for GTK 3 apps (but will become mandatory for GTK 4 apps). If your application uses WebKitGTK, you really need to take some time to enable this sandbox using webkit_web_context_set_sandbox_enabled(). The sandbox has introduced a couple regressions that we didn’t notice until too late; notably, printing no longer works, which, half a year later, we still haven’t managed to fix yet. (I’ll try to get to it soon.)
OK, this concludes your 3.36 and 3.34 updates. Onward to 3.38!
Once again this year I attended the GStreamer conference and just before
that, Embedded Linux conference Europe which took place in Lyon (France).
Both events were a good opportunity to demo one of the use-cases I have in mind
for GstWPE, HTML overlays!
Epiphany Technology Preview has moved from https://sdk.gnome.org to https://nightly.gnome.org. The old Epiphany Technology Preview is now end-of-life. Action is required to update. If you installed Epiphany Technology Preview prior to a couple minutes ago, uninstall it using GNOME Software and then reinstall using this new flatpakref.
Apologies for this disruption.
The main benefit to end users is that you’ll no longer need separate remotes for nightly runtimes and nightly applications, because everything is now hosted in one repo. See Abderrahim’s announcement for full details on why this transition is occurring.
This has resulted in a public relations drama that is largely a distraction to the issue at hand. Whatever big-company PR departments have to say on the matter, I have no doubt that the developers working on WebKit recognize the severity of this incident and are grateful to Project Zero, which reported these vulnerabilities and has previously provided numerous other high-quality private vulnerability reports. (Many other organizations deserve credit for similar reports, especially Trend Micro’s Zero Day Initiative.)
WebKit as a project will need to reassess certain software development practices that may have facilitated the abuse of these vulnerabilities. The practice of committing security fixes to open source long in advance of corresponding Safari releases may need to be reconsidered.
Sadly, Uighurs should assume their personal computing devices have been compromised by state-sponsored attackers, and that their private communications are not private. Even if not compromised in this particular incident, similar successful attacks are overwhelmingly likely in the future.
I’m excited to announce that Epiphany Tech Preview has reached version 3.33.3-33, as computed by git describe. That is 33 commits after 3.33.3:
I’m afraid 3.33.4 will arrive long before we make it to 3.33.3-333, so this is probably the last cool version number Epiphany will ever have.
I might be guilty of using an empty commit to claim the -33 commit.
I might also apologize for wasting your time with a useless blog post, except this was rather fun. I await the controversy of your choice in the comments.
Last week I finally found some time to add the automation mode to Epiphany, that allows to run automated tests using WebDriver. It’s important to note that the automation mode is not expected to be used by users or applications to control the browser remotely, but only by WebDriver automated tests. For that reason, the automation mode is incompatible with a primary user profile. There are a few other things affected by the auotmation mode:
There’s no persistency. A private profile is created in tmp and only ephemeral web contexts are used.
URL entry is not editable, since users are not expected to interact with the browser.
An info bar is shown to notify the user that the browser is being controlled by automation.
The window decoration is orange to make it even clearer that the browser is running in automation mode.
So, how can I write tests to be run in Epiphany? First, you need to install a recently enough selenium. For now, only the python API is supported. Selenium doesn’t have an Epiphany driver, but the WebKitGTK driver can be used with any WebKitGTK+ based browser, by providing the browser information as part of session capabilities.
This is a very simple example that just opens Epiphany in automation mode, loads http://www.webkitgtk.org and closes Epiphany. A few comments about the example:
Version 3.31.4 will be the first one including the automation mode.
At the beginning of October I had the wonderful chance of attending the Web
Engines Hackfest in A Coruña, hosted by
Igalia. This year we were over 50 participants, which
was great to associate even more faces to IRC nick names, but more importantly
allows hackers working at all the levels of the Web stack to share a common
space for a few days, making it possible to discuss complex topics and figure
out the future of the projects which allow humanity to see pictures of cute
kittens — among many other things.
Enabling support for the CSS generic system font family.
Fun trivia: Most of the WebKit contributors work from
the United States, so the week of the Web Engines hackfest is probably the only
single moment during the whole year that there is a sizeable peak of activity
in European day times.
Watching repository activity during the hackfest.
Towards WPE Releases
At Igalia we are making an important investment in the WPE WebKit
port, which is specially targeted towards
embedded devices. An important milestone for the project was reached last May
when the code was moved to main WebKit
repository, and has been
receiving the usual stream of improvements and bug fixes. We are now
approaching the moment where we feel that is is ready to start making releases,
which is another major milestone.
Our plan for the WPE is to synchronize with
WebKitGTK+, and produce releases for both in
parallel. This is important because both ports share a good amount of their
code and base dependencies (GStreamer, GLib, libsoup) and our efforts to
stabilize the GTK+ port before each release will benefit the WPE one as well,
and vice versa. In the coming weeks we will be publishing the first official
tarball starting off the WebKitGTK+ 2.18.x stable
branch.
Wild WEBKIT PORT appeared!
Syncing the releases for both ports means that:
Both stable and unstable releases are done in sync with the GNOME
release schedule. Unstable
releases start at version X.Y.1, with Y being an odd number.
About one month before the release dates, we create a new release branch
and from there on we work on stabilizing the code. At least one testing
release with with version X.Y.90 will be made. This is also what GNOME
does, and we will mimic this to avoid confusion for downstream packagers.
The stable release will have version X.Y+1.0. Further maintenance
releases happen from the release branch as needed. At the same time,
a new cycle of unstable releases is started based on the code from the
tip of the repository.
Believe it or not, preparing a codebase for its first releases involves quite
a lot of work, and this is what took most of my coding time during the Web
Engines Hackfest and also the following weeks: from small
fixesfor build
failures all the way to making
sure that public API headers (only the correct
ones!) are
installedand
usable, that applications can
be properly linked, and that
release tarballs can actually be
created. Exhausting? Well, do
not forget that we need to set up a web server to host the tarballs, a small
website, and the documentation. The latter has to be generated (there is still
pending work in this regard), and the whole process of making a release
scripted.
Still with me? Great. Now for a plot twist: we won’t be making
proper releases just yet.
APIs, ABIs, and Releases
There is one topic which I did not touch yet: API/ABI stability. Having done
a release implies that the public API and ABI which are part of it are stable,
and they are not subject to change.
Right after upstreaming WPE we switched over from the cross-port WebKit2 C API
and added a new, GLib-based API to WPE. It is remarkably similar (if not the
same in many cases) to the API exposed by WebKitGTK+, and this makes us
confident that the new API is higher-level, more ergonomic, and better overall.
At the same time, we would like third party developers to give it a try (which
is easier having releases) while retaining the possibility of getting feedback
and improving the WPE GLib API before setting it on stone (which is not
possible after a release).
It is for this reason that at least during the first WPE release cycle we
will make preview releases, meaning that there might be API and ABI
changes from one release to the next. As usual we will not be making
breaking changes in between releases of the same stable series, i.e. code
written for 2.18.0 will continue to build unchanged with any subsequent
2.18.X release.
At any rate, we do not expect the API to receive big changes because —as
explained above— it mimics the one for WebKitGTK+, which has already proven
itself both powerful enough for complex applications and convenient to use for
the simpler ones. Due to this, I encourage developers to try out WPE as soon
as we have the first preview release fresh out of the oven.
Packaging for Buildroot
At Igalia we routinely work with embedded devices, and often we make use of
Buildroot for cross-compilation. Having actual
releases of WPE will allow us to contribute a set of build definitions for the
WPE WebKit port and its dependencies — something that I have already started
working on.
Lately I have been taking care of keeping the WebKitGTK+ packaging for
Buildroot up-to-date and it has been delightful to work with such a welcoming
community. I am looking forward to having WPE supported there, and to keep
maintaining the build definitions for both. This will allow making use of WPE
with relative ease, while ensuring that Buildroot users will pick our updates
promptly.
Generic System Font
Some applications like GNOME Web
Epiphany use a WebKitWebView to display
widget-like controls which try to follow the design of the rest of the desktop.
Unfortunately for GNOME applications this means
Cantarell gets hardcoded
in the style sheet —it is the default font after all— and this results in
mismatched fonts when the user has chosen a different font for the interface
(e.g. in Tweaks). You can see
this in the following screen capture of Epiphany:
Web using hardcoded Cantarell and (on hover) `-webkit-system-font`.
Here I have configured the beautiful Inter UI font as
the default for the desktop user interface. Now, if you roll your mouse over
the image, you will see how much better it looks to use a consistent font.
This change also affects the list of plugins and applications, error messages,
and in general all the about: pages.
If you are running GNOME 3.26, this is already
fixed using font: menu
(part of the CSS
spec
since ye olde CSS 2.1) — but we can do better: Safari has had support since
2015,
for a generic “system” font family, similar to sans-serif or cursive:
/* Using the new generic font family (nice!). */body {
font-family: -webkit-system-font;
}
/* Using CSS 2.1 font shorthands (not so nice). */body {
font: menu; /* Pick ALL font attributes... */font-size: 12pt; /* ...then reset some of them. */font-weight: 400;
}
Web Inspector using Cantarell, the default GNOME 3 font
([full size](minibrowser-inspector-cantarell.png)).
I am convinced that users do notice and appreciate attention to detail,
even if they do unconsciously, and therefore it is worthwhile to work on this
kind of improvements.
Plus, as a design enthusiast with a slight case of typographic
OCD, I cannot stop myself
from noticing inconsistent usage of fonts and my mind is now at ease knowing
that opening the Web Inspector won’t be such a jarring experience anymore.
Outro
But there’s one more thing: On occasion we developers have to debug situations
in which a process is seemingly stuck. One useful technique involves running
the offending process under the control of a debugger (or, in an embedded
device, under gdbserver and controlled remotely), interrupting its execution
at intervals, and printing stack traces to try and figure out what is going on.
Unfortunately, in some circumstances running a debugger can be difficult or
impractical. Wouldn’t it be grand if it was possible to interrupt the process
without needing a debugger and request a stack trace? Enter “Out-Of-Band
Stack Traces” (proof of
concept):
The process installs a signal handler using
sigaction(7), with the
SA_SIGINFO flag set.
On reception of the signal, the kernel interrupts the process (even if it’s
in an infinite loop), and invokes the signal handler passing an extra
pointer to an ucontext_t value, which contains a snapshot of the execution
status of the thread which was in the CPU before the signal handler was
invoked. This is true for many platform including Linux and most BSDs.
The signal handler code can get obtain the instruction and stack pointers
from the ucontext_t value, and walk the stack to produce a stack trace
of the code that was being executed. Jackpot! This is of course
architecture dependent but not difficult to get right (and well tested)
for the most common ones like x86 and ARM.
The nice thing about this approach is that the code that obtains the stack
trace is built into the program (no rebuilds needed), and it does not even
require to relaunch the process in a debugger — which can be crucial for
analyzing situations which are hard to reproduce, or which do not happen
when running inside a debugger. I am looking forward to have some time to
integrate this properly into WebKitGTK+ and specially WPE, because it will
be most useful in embedded devices.
WebDriver is an automation API to control a web browser. It allows to create automated tests for web applications independently of the browser and platform. WebKitGTK+ 2.18, that will be released next week, includes an initial implementation of the WebDriver specification.
WebDriver in WebKitGTK+
There’s a new process (WebKitWebDriver) that works as the server, processing the clients requests to spawn and control the web browser. The WebKitGTK+ driver is not tied to any specific browser, it can be used with any WebKitGTK+ based browser, but it uses MiniBrowser as the default. The driver uses the same remote controlling protocol used by the remote inspector to communicate and control the web browser instance. The implementation is not complete yet, but it’s enough for what many users need.
The clients
The web application tests are the clients of the WebDriver server. The Selenium project provides APIs for different languages (Java, Python, Ruby, etc.) to write the tests. Python is the only language supported by WebKitGTK+ for now. It’s not yet upstream, but we hope it will be integrated soon. In the meantime you can use our fork in github. Let’s see an example to understand how it works and what we can do.
from selenium import webdriver
# Create a WebKitGTK driver instance. It spawns WebKitWebDriver
# process automatically that will launch MiniBrowser.
wkgtk = webdriver.WebKitGTK()
# Let's load the WebKitGTK+ website.
wkgtk.get("https://www.webkitgtk.org")
# Find the GNOME link.
gnome = wkgtk.find_element_by_partial_link_text("GNOME")
# Click on the link.
gnome.click()
# Find the search form.
search = wkgtk.find_element_by_id("searchform")
# Find the first input element in the search form.
text_field = search.find_element_by_tag_name("input")
# Type epiphany in the search field and submit.
text_field.send_keys("epiphany")
text_field.submit()
# Let's count the links in the contents div to check we got results.
contents = wkgtk.find_element_by_class_name("content")
links = contents.find_elements_by_tag_name("a")
assert len(links) > 0
# Quit the driver. The session is closed so MiniBrowser
# will be closed and then WebKitWebDriver process finishes.
wkgtk.quit()
Note that this is just an example to show how to write a test and what kind of things you can do, there are better ways to achieve the same results, and it depends on the current source of public websites, so it might not work in the future.
Web browsers / applications
As I said before, WebKitWebDriver process supports any WebKitGTK+ based browser, but that doesn’t mean all browsers can automatically be controlled by automation (that would be scary). WebKitGTK+ 2.18 also provides new API for applications to support automation.
First of all the application has to explicitly enable automation using webkit_web_context_set_automation_allowed(). It’s important to know that the WebKitGTK+ API doesn’t allow to enable automation in several WebKitWebContexts at the same time. The driver will spawn the application when a new session is requested, so the application should enable automation at startup. It’s recommended that applications add a new command line option to enable automation, and only enable it when provided.
After launching the application the driver will request the browser to create a new automation session. The signal “automation-started” will be emitted in the context to notify the application that a new session has been created. If automation is not allowed in the context, the session won’t be created and the signal won’t be emitted either.
The WebKitAutomationSession will emit the signal “create-web-view” every time the driver needs to create a new web view. The application can then create a new window or tab containing the new web view that should be returned by the signal. This signal will always be emitted even if the browser has already an initial web view open, in that case it’s recommened to return the existing empty web view.
Web views are also automation aware, similar to ephemeral web views, web views that allow automation should be created with the constructor property “is-controlled-by-automation” enabled.
This is the new API that applications need to implement to support WebDriver, it’s designed to be as safe as possible, but there are many things that can’t be controlled by WebKitGTK+, so we have several recommendations for applications that want to support automation:
Add a way to enable automation in your application at startup, like a command line option, that is disabled by default. Never allow automation in a normal application instance.
Enabling automation is not the only thing the application should do, so add an automation mode to your application.
Add visual feedback when in automation mode, like changing the theme, the window title or whatever that makes clear that a window or instance of the application is controllable by automation.
Add a message to explain that the window is being controlled by automation and the user is not expected to use it.
Use ephemeral web views in automation mode.
Use a temporal user profile in application mode, do not allow automation to change the history, bookmarks, etc. of an existing user.
Do not load any homepage in automation mode, just keep an empty web view (about:blank) that can be used when a new web view is requested by automation.
The WebKitGTK client driver
Applications need to implement the new automation API to support WebDriver, but the WebKitWebDriver process doesn’t know how to launch the browsers. That information should be provided by the client using the WebKitGTKOptions object. The driver constructor can receive an instance of a WebKitGTKOptions object, with the browser information and other options. Let’s see how it works with an example to launch epiphany:
from selenium import webdriver
from selenium.webdriver import WebKitGTKOptions
options = WebKitGTKOptions()
options.browser_executable_path = "/usr/bin/epiphany"
options.add_browser_argument("--automation-mode")
epiphany = webdriver.WebKitGTK(browser_options=options)
Again, this is just an example, Epiphany doesn’t even support WebDriver yet. Browsers or applications could create their own drivers on top of the WebKitGTK one to make it more convenient to use.
from selenium import webdriver
epiphany = webdriver.Epiphany()
Plans
During the next release cycle, we plan to do the following tasks:
Complete the implementation: add support for all commands in the spec and complete the ones that are partially supported now.
Add support for running the WPT WebDriver tests in the WebKit bots.
Add a WebKitGTK driver implementation for other languages in Selenium.
My wife asked me for some rough LOC numbers on the WebKit project and I think I could share them with you here as well. They come from r221232. As I’ll take into account some generated code it is relevant to mention that I built WebKitGTK+ with the default CMake options.
First thing I did was running sloccount Source and got the following numbers:
Let’s have a look now at the LayoutTests (they test the functionality of WebCore + the platform). Tests are composed mainly by HTML files so if you run sloccount LayoutTests you get:
It’s quite interesting to see that sloccount does not consider HTML which is quite relevant when you’re testing a web engine so again, we have to count them manually (thanks to Carlos López who helped me to properly grep here as some binary lines were giving me a headache to get the numbers):
You can see 2205690 of “meaningful lines” that combine HTML + other languages that you can see above. I can’t substract here to just get the HTML lines because the number above take into account files with a different extension than HTML, though many of them do include other languages, specially JavaScript.
But the LayoutTests do not include only pure WebKit tests. There are some imported ones so it might be interesting to run the same procedure under LayoutTests/imported to see which ones are imported and not written directly into the WebKit project. I emphasize that because they can be written by WebKit developers in other repositories and actually I can present myself and Youenn Fablet as an example as we wrote tests some tests that were finally moved into the specification and included back later when imported. So again, sloccount LayoutTests/imported:
There are also some other tests that we can talk about, for example the JSTests. I’ll mention already the numbers summed up regarding languages and the manual HTML code (if you made it here, you know the drill already):
And this is all. Remember that these are just some rough statistics, not a “scientific” paper.
Update:
In her expert opinion, in the WebKit project we are devoting around 50% of the total LOC to testing, which makes it a software engineering “textbook” project regarding testing and I think we can be proud of it!
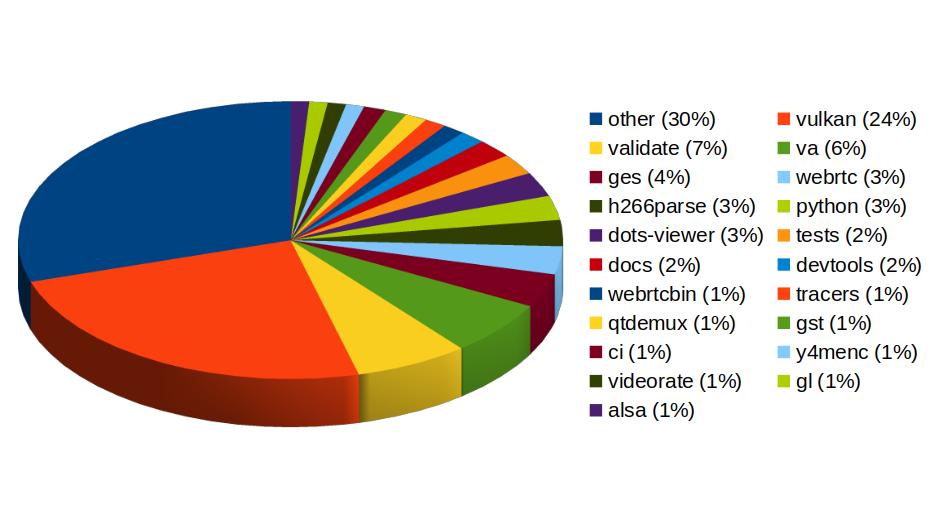
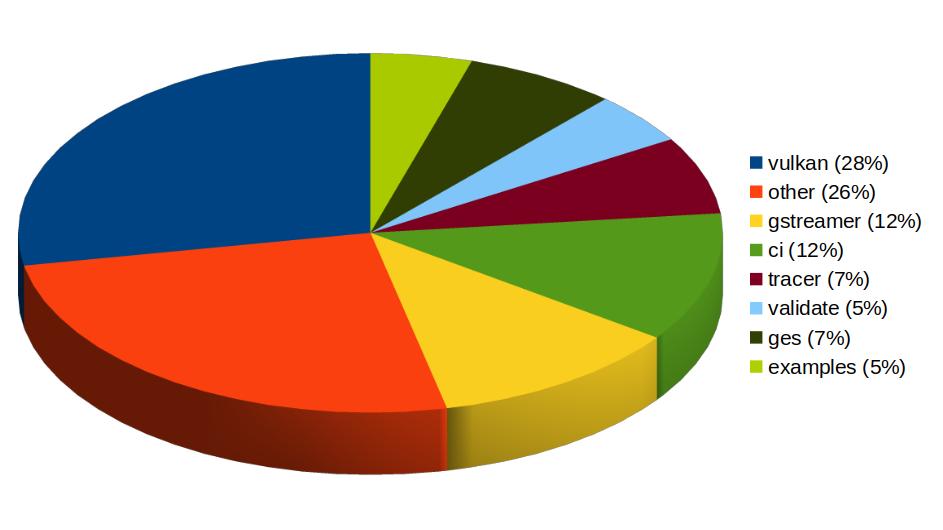
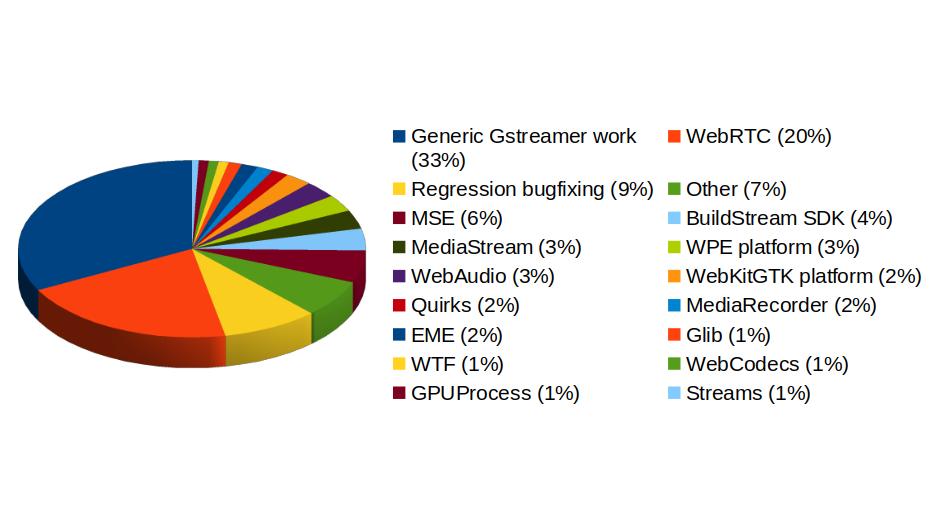


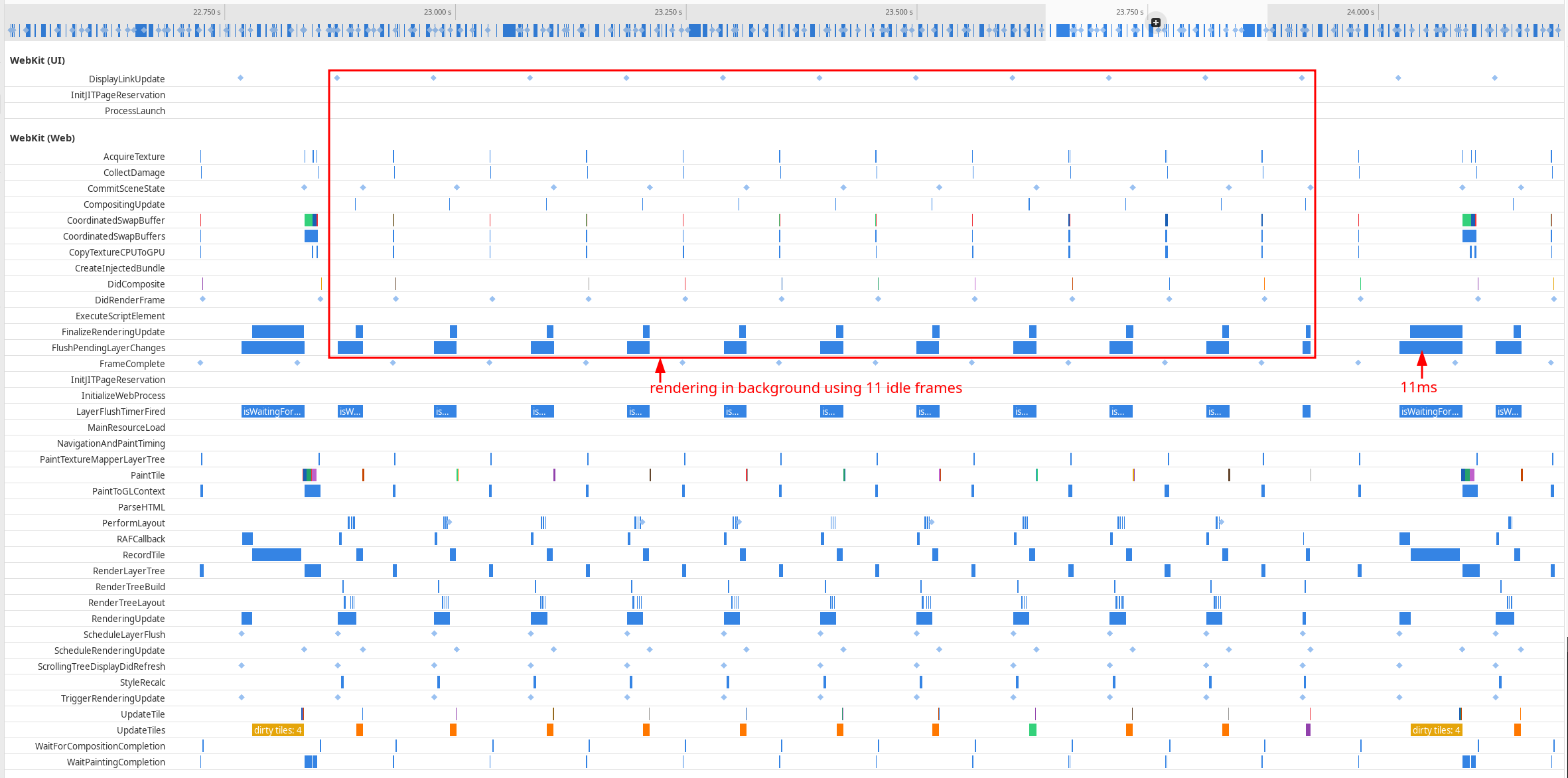

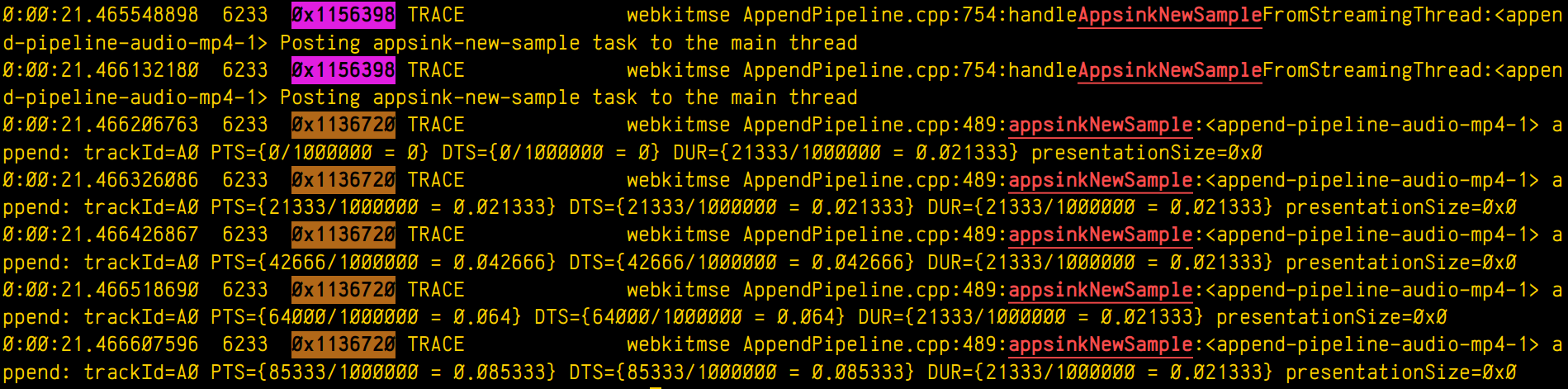
 ).
).
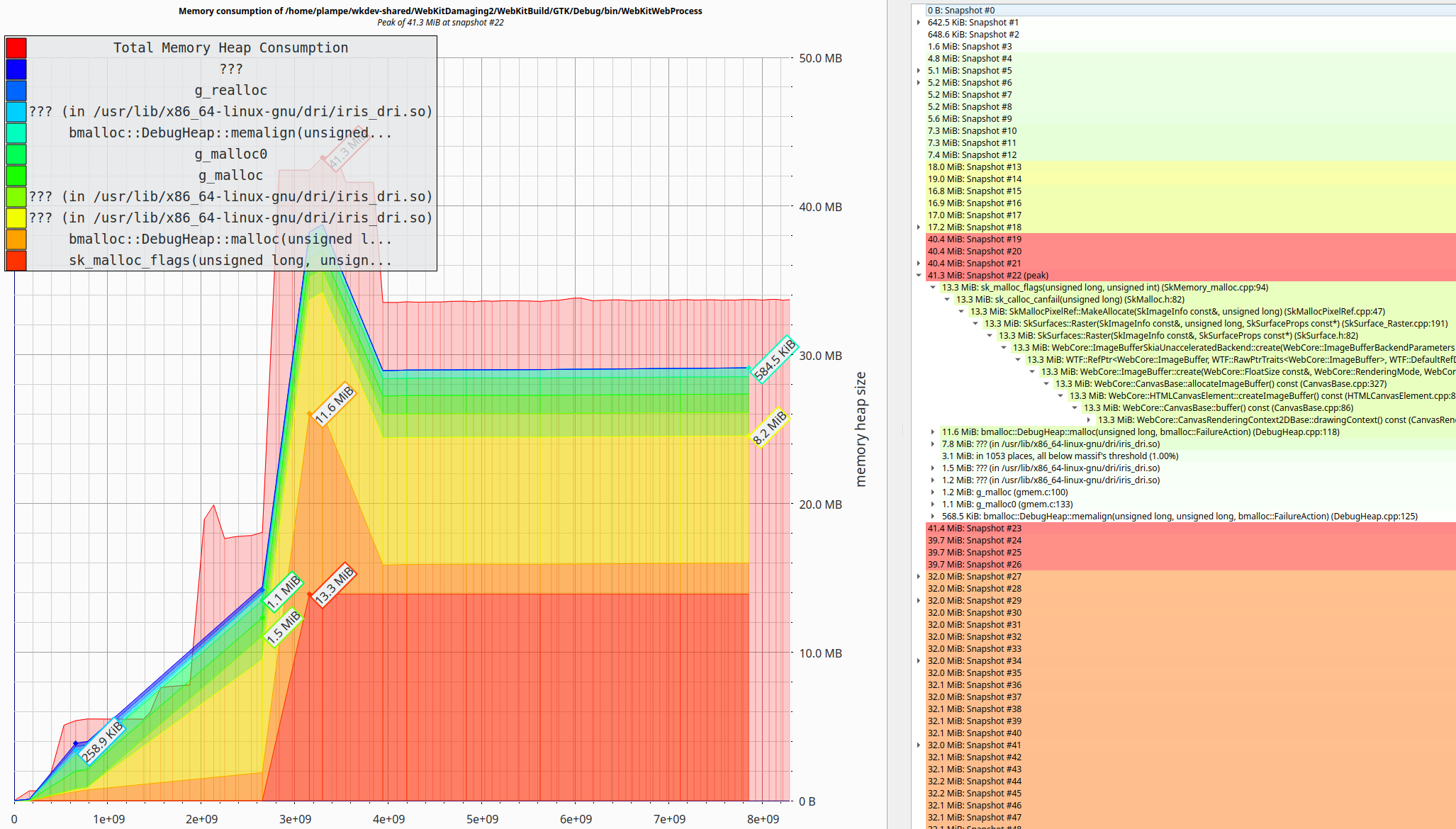
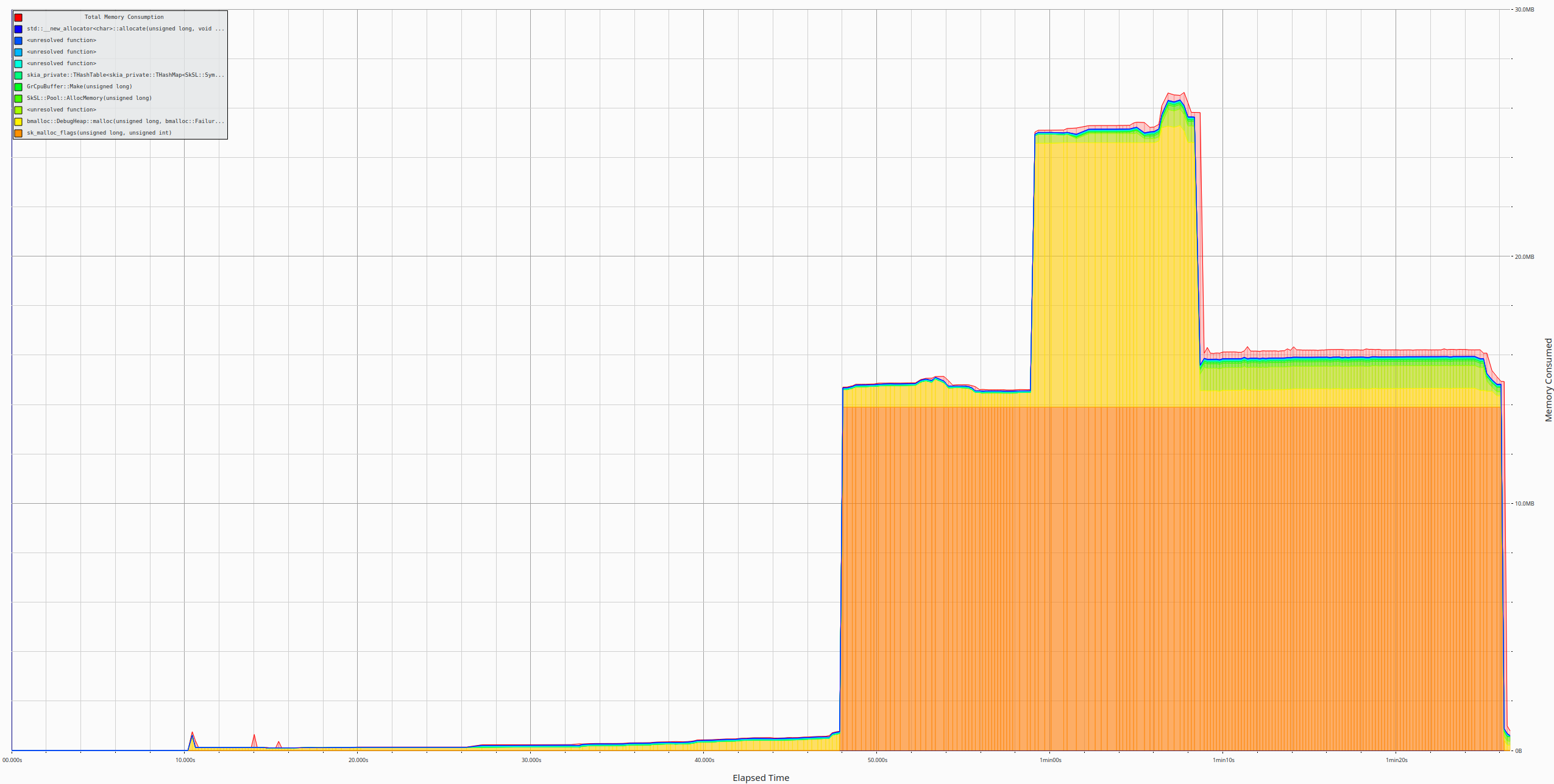
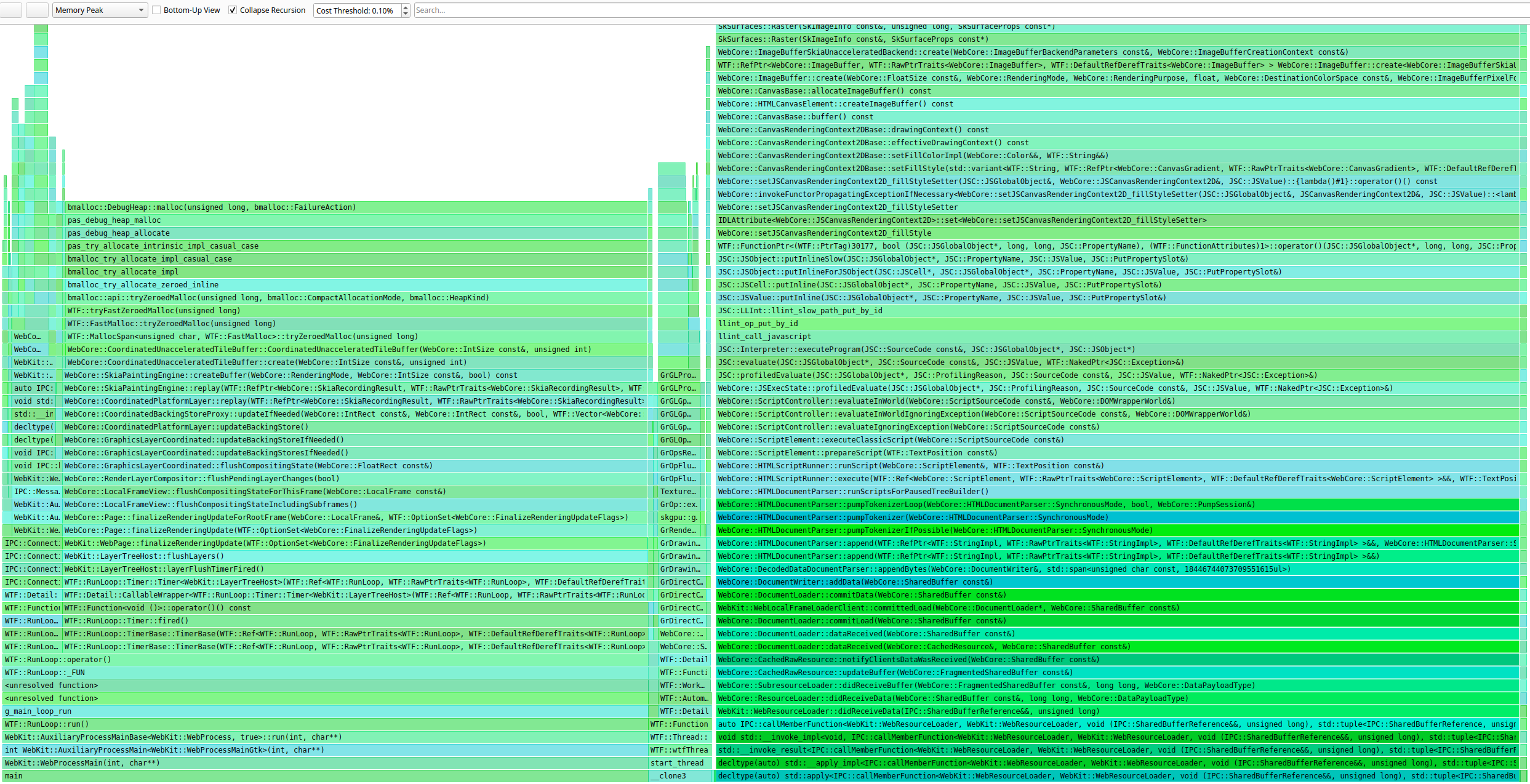
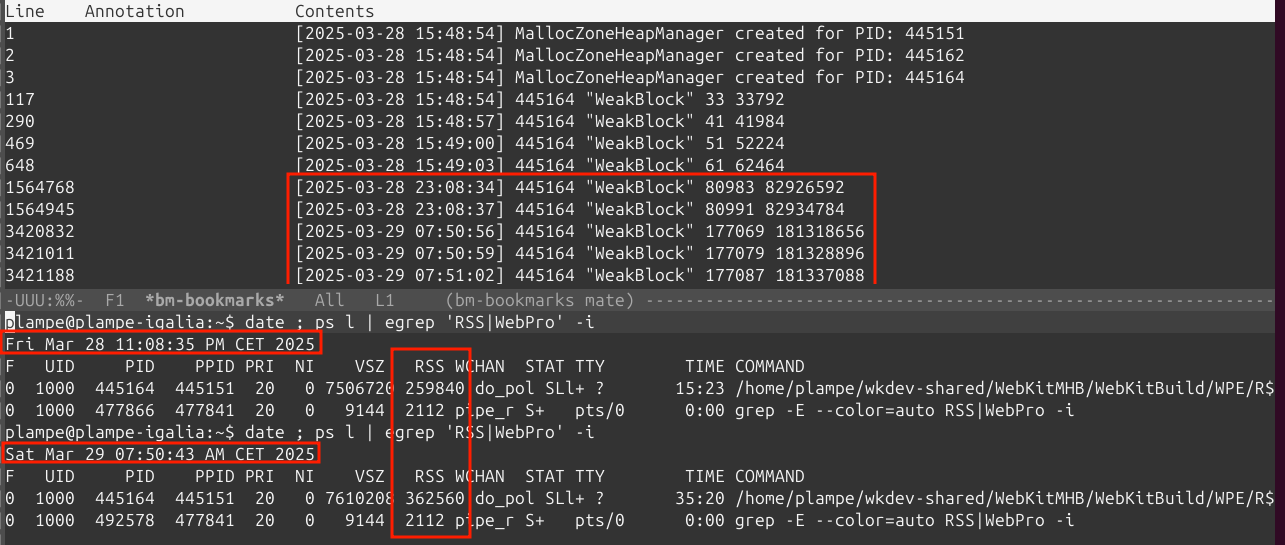
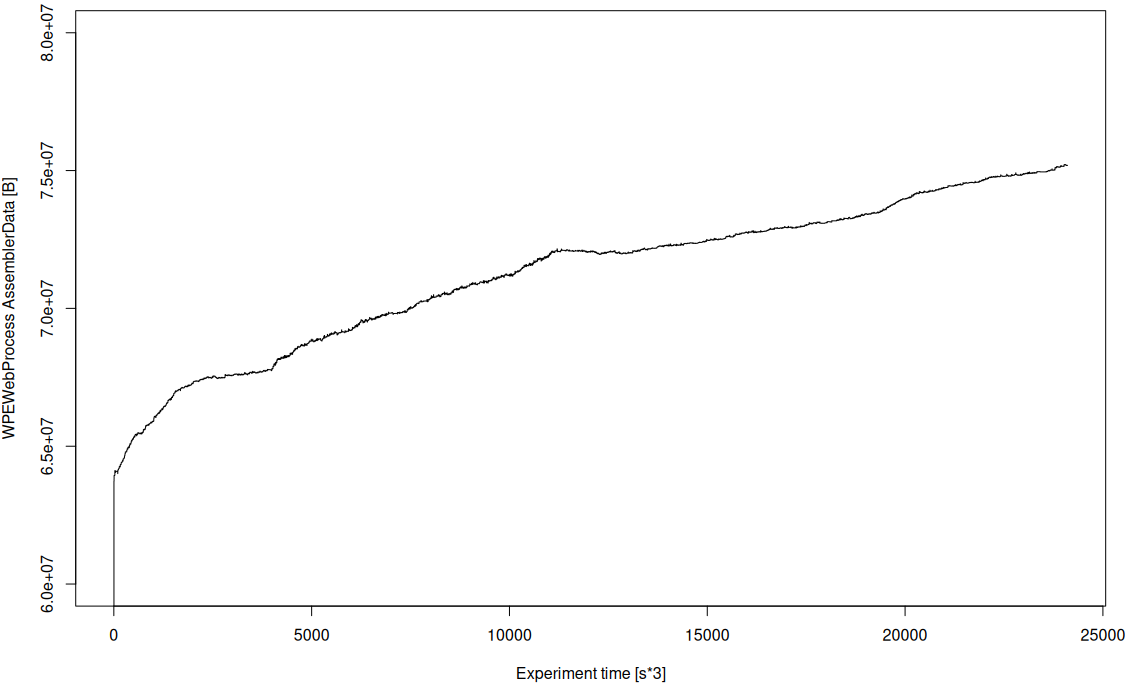

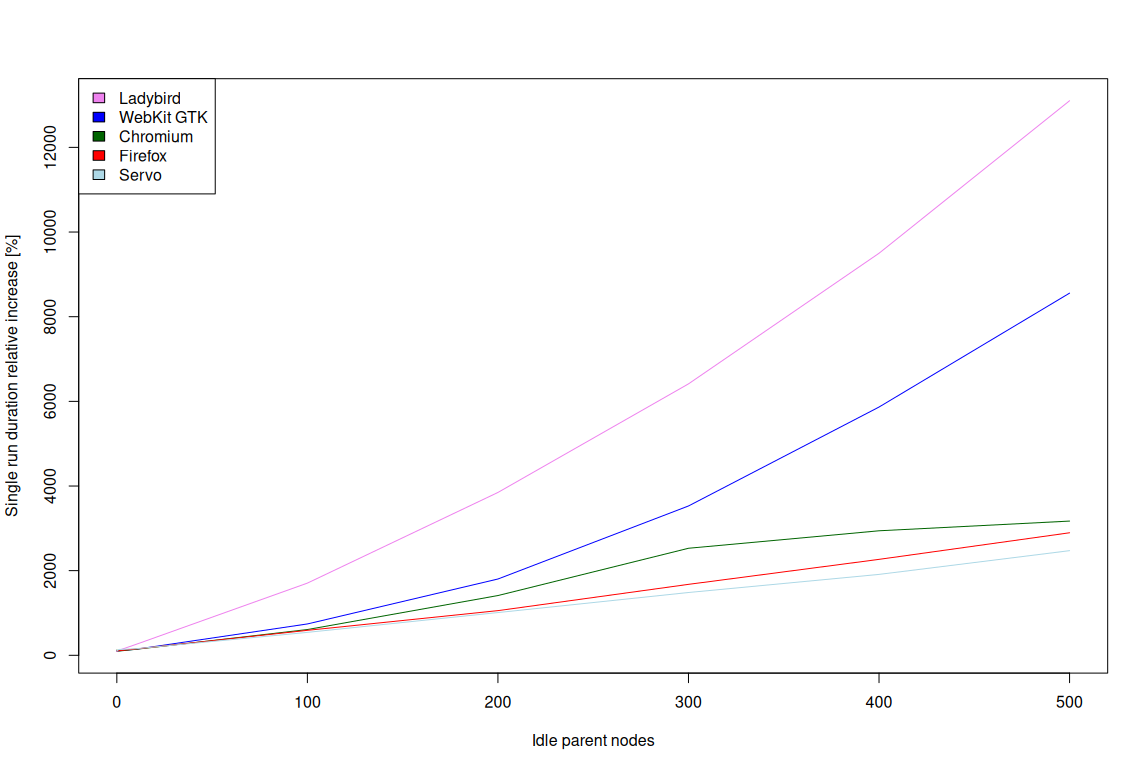
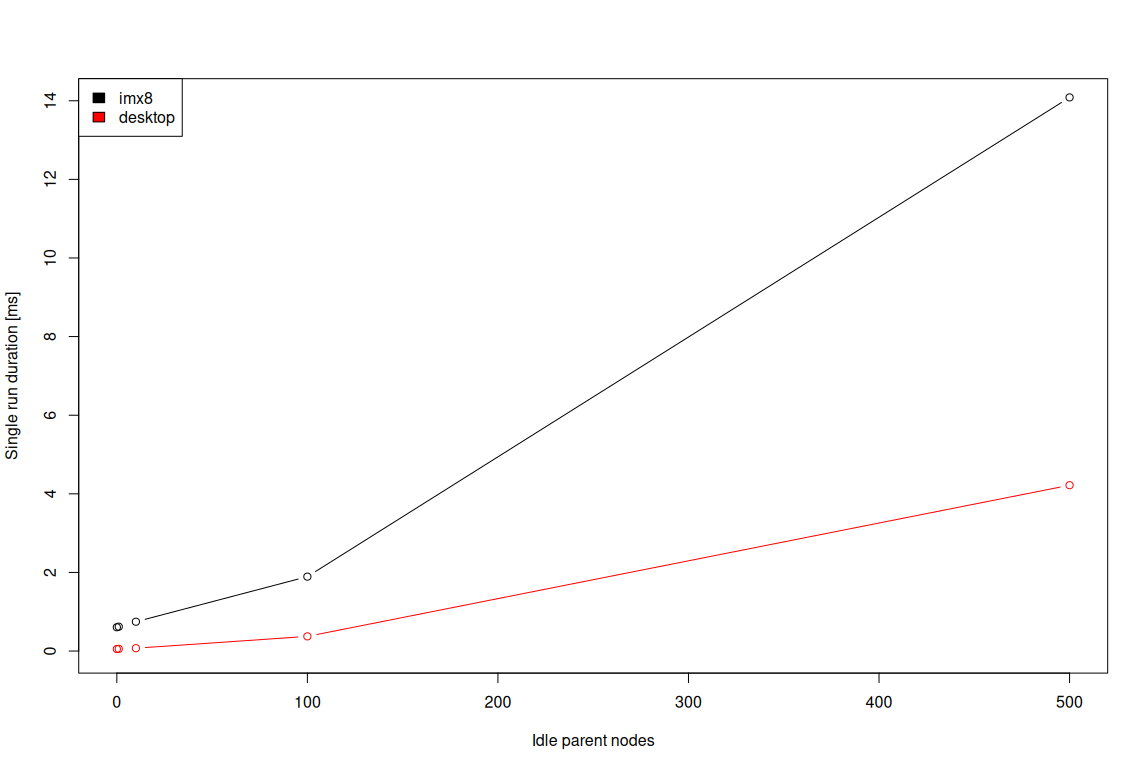
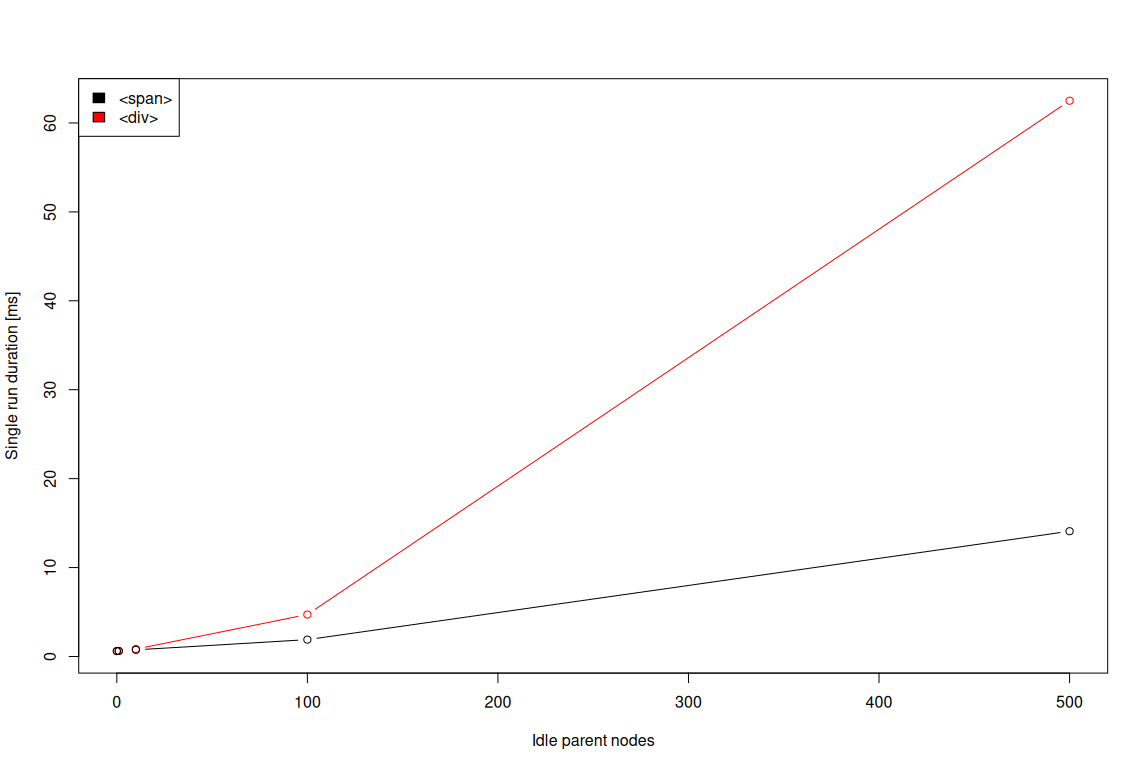
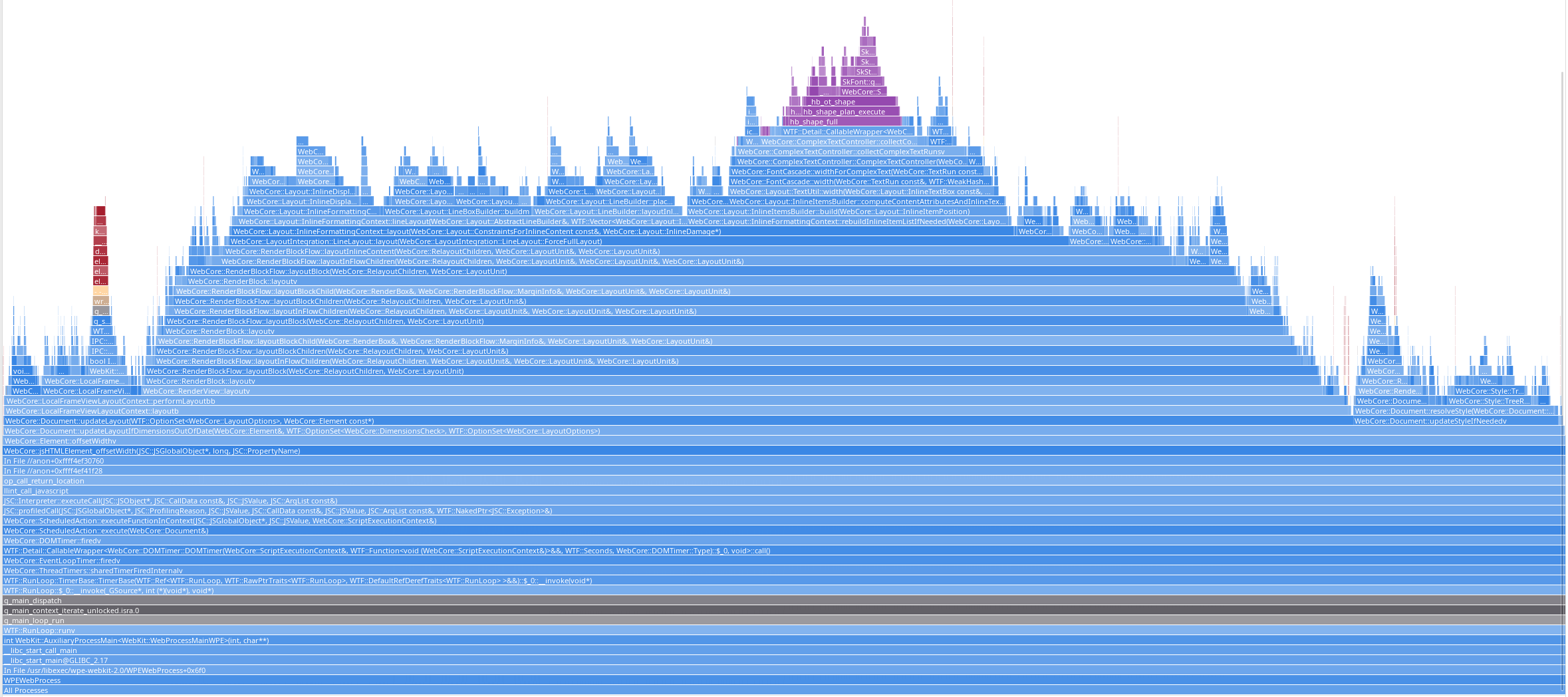

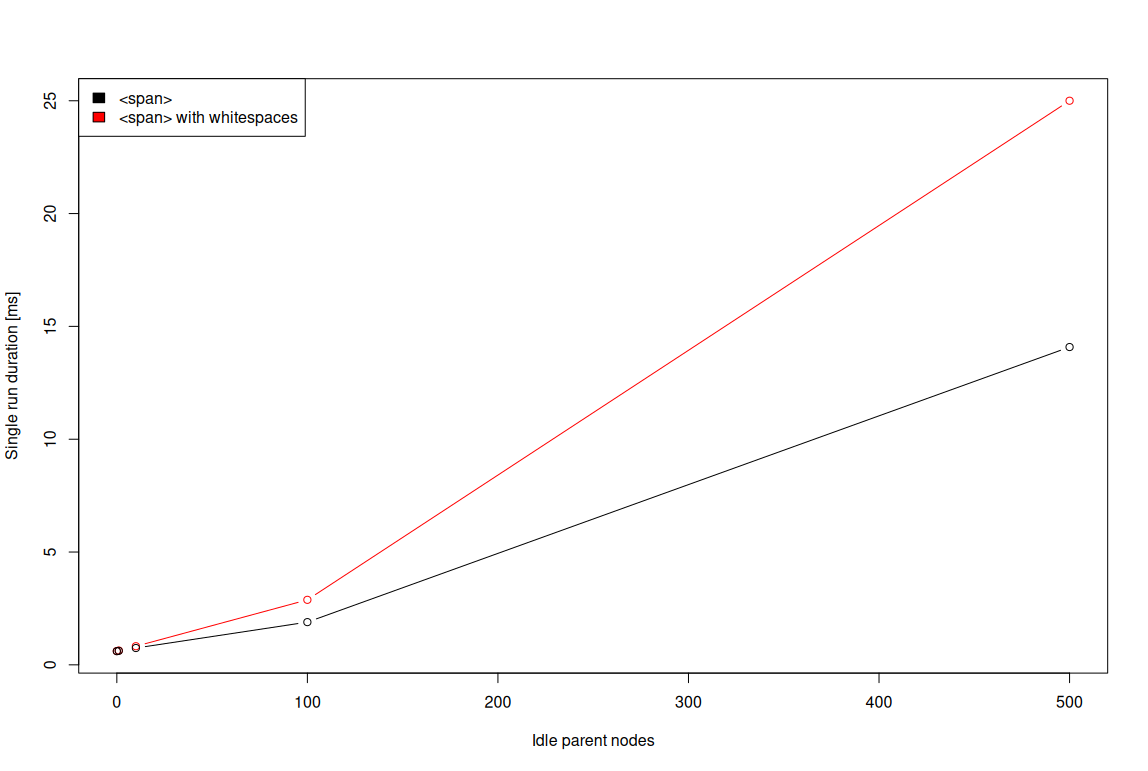
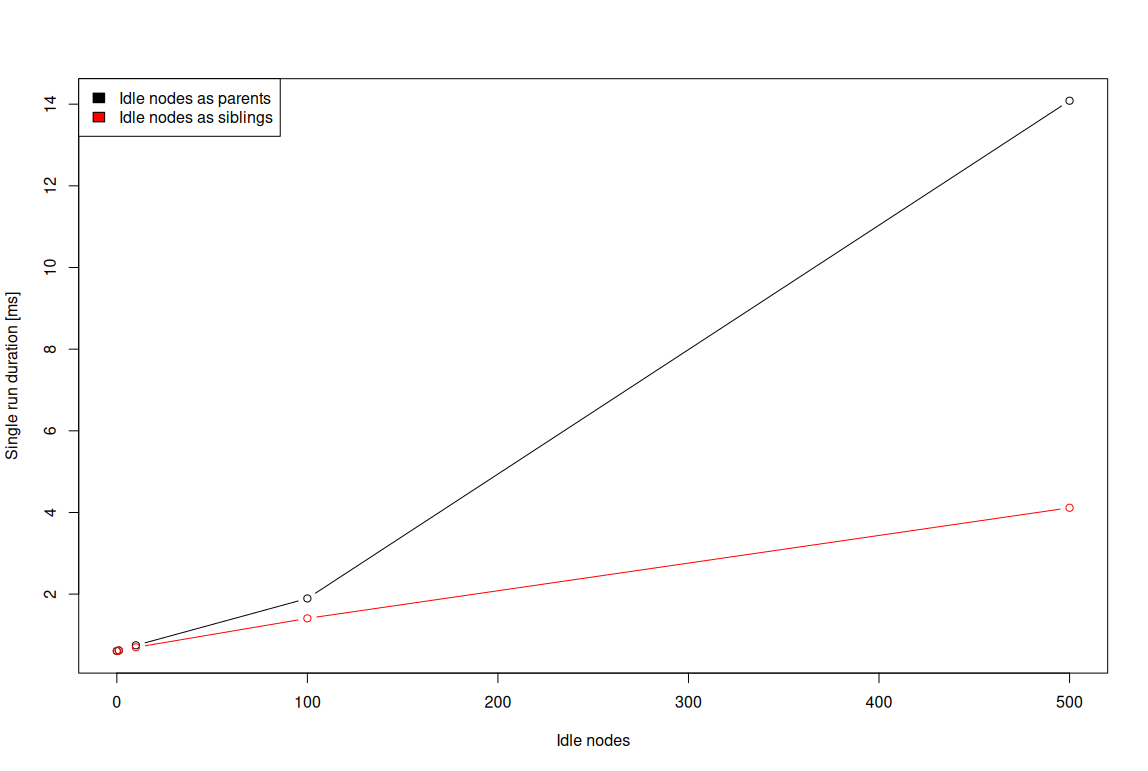







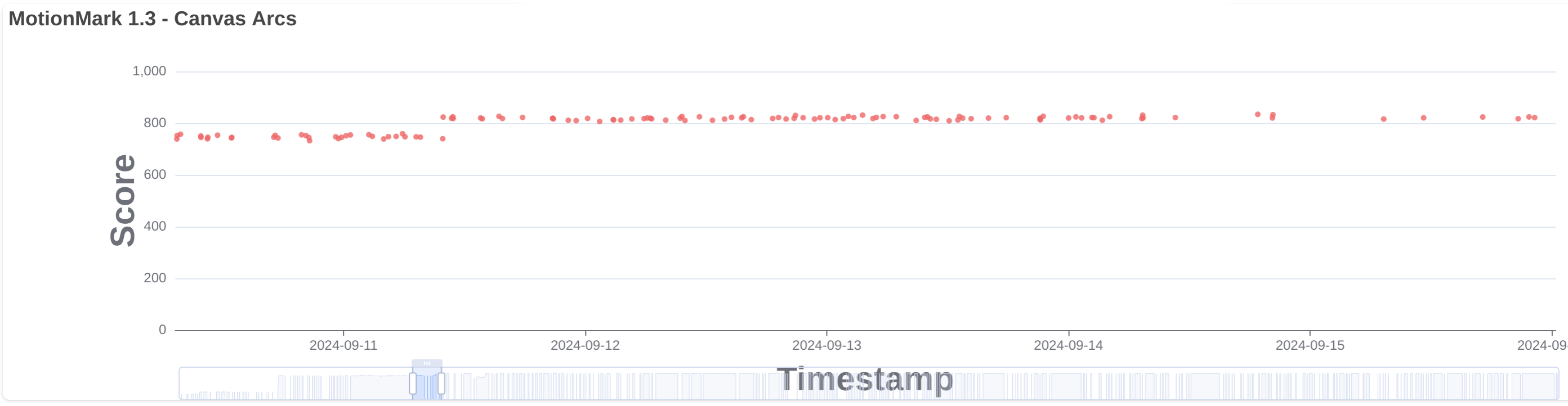
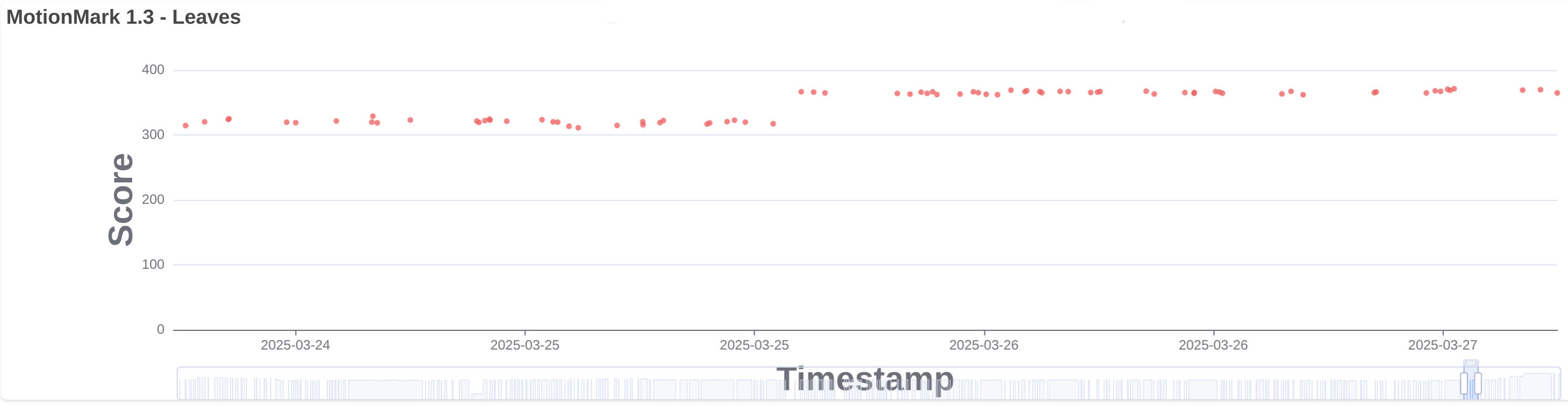
 In the image above, one can see the following elements:
In the image above, one can see the following elements:

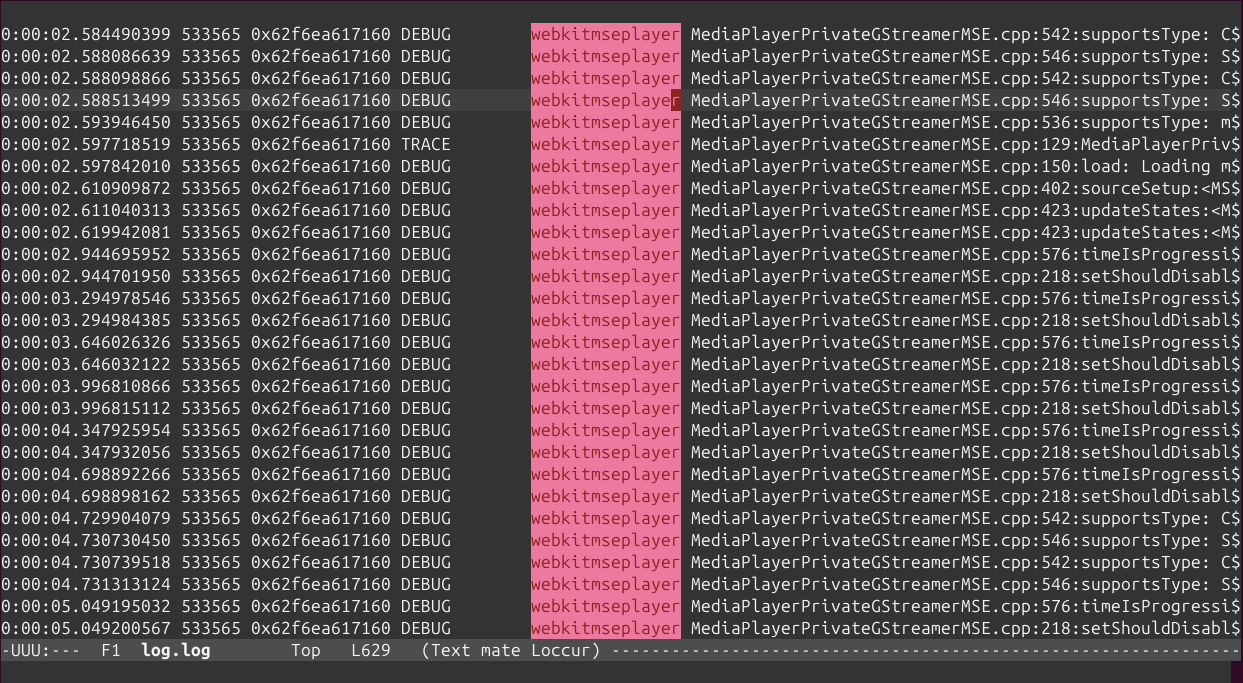
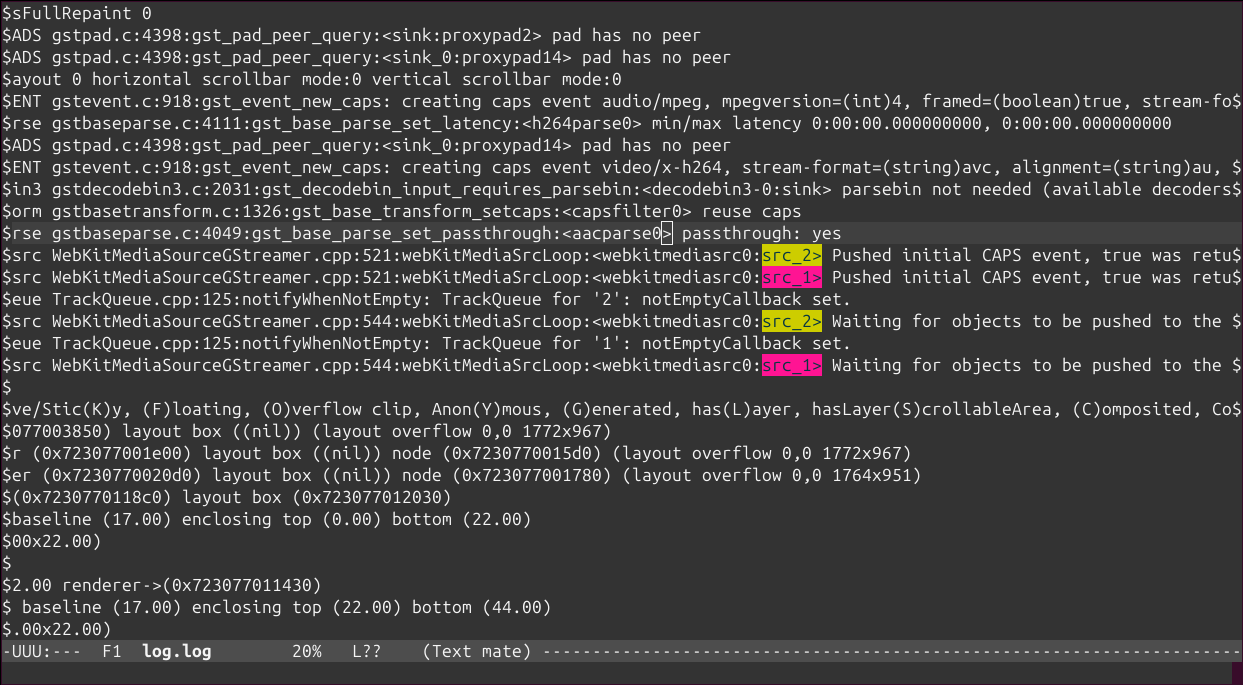 just by moving the cursor around and using
just by moving the cursor around and using  as well as non-visual capabilities that will be discussed in further sections.
as well as non-visual capabilities that will be discussed in further sections.